本文提供了一个自定义聚合函数(UDAF),实现将多行数据合并为一行并按照指定列进行排序,并以居民用电户电网终端数据为例,介绍如何在实时计算控制台使用该函数进行数据聚合和排序。
示例数据
居民用电户电网终端数据表electric_info,包括事件标识event_id,用户标识user_id,事件时间event_time,用户终端状态status。需要将用户的终端状态按照事件时间升序排列。
electric_info
event_id
user_id
event_time
status
1
1222
2023-06-30 11:14:00
LD
2
1333
2023-06-30 11:12:00
LD
3
1222
2023-06-30 11:11:00
TD
4
1333
2023-06-30 11:12:00
LD
5
1222
2023-06-30 11:15:00
TD
6
1333
2023-06-30 11:18:00
LD
7
1222
2023-06-30 11:19:00
TD
8
1333
2023-06-30 11:10:00
TD
9
1555
2023-06-30 11:16:00
TD
10
1555
2023-06-30 11:17:00
LD
预期结果
user_id
status
1222
TD,LD,TD,TD
1333
TD,LD,LD,LD
1555
TD,LD
步骤一:准备数据源
本文以云数据库RDS为例。
- 说明
RDS MySQL版实例需要与Flink工作空间处于同一VPC。不在同一VPC下时请参见网络连通性。
创建名称为electric的数据库,并创建高权限账号或具有数据库electric读写权限的普通账号。
通过DMS登录RDS MySQL,在electric数据库中创建表electric_info和electric_info_SortListAgg,并插入数据。
CREATE TABLE `electric_info` ( event_id bigint NOT NULL PRIMARY KEY COMMENT '事件id', user_id bigint NOT NULL COMMENT '用户标识', event_time timestamp NOT NULL COMMENT '事件时间', status varchar(10) NOT NULL COMMENT '用户终端状态' ); CREATE TABLE `electric_info_SortListAgg` ( user_id bigint NOT NULL PRIMARY KEY COMMENT '用户标识', status_sort varchar(50) NULL COMMENT '用户终端状态按事件时间升序' ); -- 准备数据 INSERT INTO electric_info VALUES (1,1222,'2023-06-30 11:14','LD'), (2,1333,'2023-06-30 11:12','LD'), (3,1222,'2023-06-30 11:11','TD'), (4,1333,'2023-06-30 11:12','LD'), (5,1222,'2023-06-30 11:15','TD'), (6,1333,'2023-06-30 11:18','LD'), (7,1222,'2023-06-30 11:19','TD'), (8,1333,'2023-06-30 11:10','TD'), (9,1555,'2023-06-30 11:16','TD'), (10,1555,'2023-06-30 11:17','LD');
步骤二:注册UDF
pom.xml文件已配置了Flink 1.17.1版该自定义函数需要的最小化依赖信息。关于使用自定义函数的更多信息,详情请参见自定义函数。
本示例中ASI_UDAF实现了多行数据合并一行并按照指定列进行排序,详情如下。后续您可以根据实际业务情况进行修改。
package ASI_UDAF; import org.apache.commons.lang3.StringUtils; import org.apache.flink.table.functions.AggregateFunction; import java.util.ArrayList; import java.util.Comparator; import java.util.Iterator; import java.util.List; public class ASI_UDAF{ /**Accumulator class*/ public static class AcList { public List<String> list; } /**Aggregate function class*/ public static class SortListAgg extends AggregateFunction<String,AcList> { public String getValue(AcList asc) { /**Sort the data in the list according to a specific rule*/ asc.list.sort(new Comparator<String>() { @Override public int compare(String o1, String o2) { return Integer.parseInt(o1.split("#")[1]) - Integer.parseInt(o2.split("#")[1]); } }); /**Traverse the sorted list, extract the required fields, and join them into a string*/ List<String> ret = new ArrayList<String>(); Iterator<String> strlist = asc.list.iterator(); while (strlist.hasNext()) { ret.add(strlist.next().split("#")[0]); } String str = StringUtils.join(ret, ','); return str; } /**Method to create an accumulator*/ public AcList createAccumulator() { AcList ac = new AcList(); List<String> list = new ArrayList<String>(); ac.list = list; return ac; } /**Accumulation method: add the input data to the accumulator*/ public void accumulate(AcList acc, String tuple1) { acc.list.add(tuple1); } /**Retraction method*/ public void retract(AcList acc, String num) { } } }进入注册UDF页面。
注册UDF方式的优点是便于后续开发进行代码复用。对于Java类型的UDF,您也可以通过依赖文件项进行上传,详情请参见自定义聚合函数(UDAF)。
登录实时计算控制台。
单击目标工作空间操作列下的控制台。
单击。
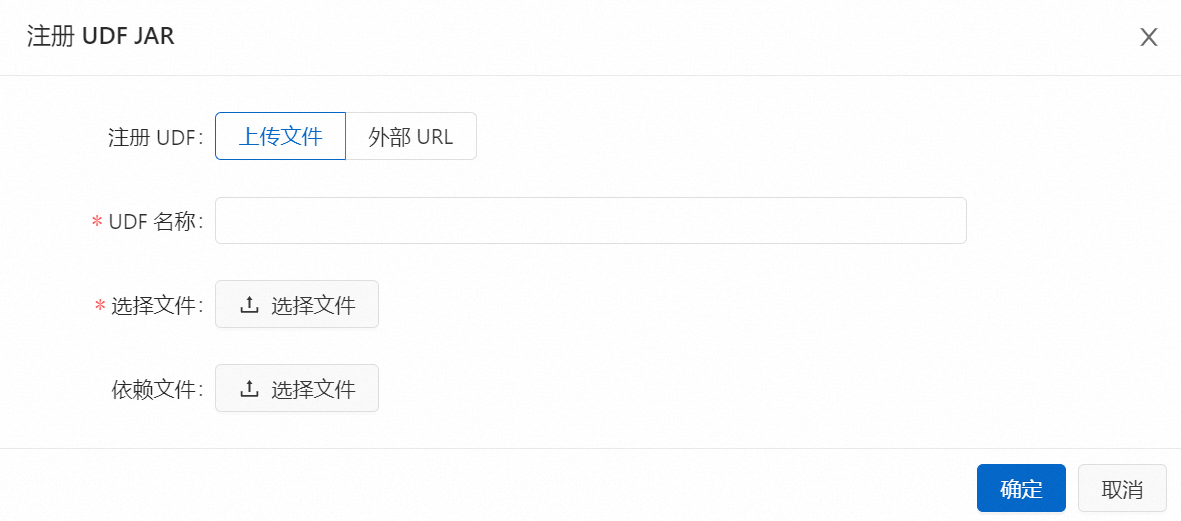
单击左侧的函数页签,单击注册UDF。

在选择文件位置上传步骤1中的JAR文件,单击确定。
 说明
说明您的UDF JAR文件会被上传到该OSS Bucket的sql-artifacts目录下。
此外,Flink开发控制台会解析您UDF JAR文件中是否使用了Flink UDF、UDAF和UDTF接口的类,并自动提取类名,填充到Function Name字段中。
在管理函数对话框,单击创建函数。
在SQL编辑器页面左侧函数列表,您可以看到已注册成功的UDF。
步骤三:创建Flink作业
在页面,单击新建。
单击空白的流作业草稿。
单击下一步。
在新建作业草稿对话框,填写作业配置信息。
作业参数
说明
文件名称
作业的名称。
说明作业名称在当前项目中必须保持唯一。
存储位置
指定该作业的存储位置。
您还可以在现有文件夹右侧,单击
 图标,新建子文件夹。
图标,新建子文件夹。引擎版本
当前作业使用的Flink的引擎版本。需要与pom中的version一致。
引擎版本号含义、版本对应关系和生命周期重要时间点详情请参见引擎版本介绍。
编写DDL和DML代码。
--创建临时表electric_info CREATE TEMPORARY TABLE electric_info ( event_id bigint not null, `user_id` bigint not null, event_time timestamp(6) not null, status string not null, primary key(event_id) not enforced ) WITH ( 'connector' = 'mysql', 'hostname' = 'rm-bp1s1xgll21******.mysql.rds.aliyuncs.com', 'port' = '3306', 'username' = 'your_username', 'password' = '${secret_values.mysql_pw}', 'database-name' = 'electric', 'table-name' = 'electric_info' ); CREATE TEMPORARY TABLE electric_info_sortlistagg ( `user_id` bigint not null, status_sort varchar(50) not null, primary key(user_id) not enforced ) WITH ( 'connector' = 'mysql', 'hostname' = 'rm-bp1s1xgll21******.mysql.rds.aliyuncs.com', 'port' = '3306', 'username' = 'your_username', 'password' = '${secret_values.mysql_pw}', 'database-name' = 'electric', 'table-name' = 'electric_info_sortlistagg' ); --将electric_info表中的数据聚合并插入到electric_info_sortlistagg表中 --将status和event_time拼接成的字符串作为参数传递给已注册的自定义函数ASI_UDAF$SortListAgg INSERT INTO electric_info_sortlistagg SELECT `user_id`, `ASI_UDAF$SortListAgg`(CONCAT(status,'#',CAST(UNIX_TIMESTAMP(event_time) as STRING))) FROM electric_info GROUP BY user_id;参数说明如下,您可以根据实际情况进行修改。MySQL连接器更多参数详情请参见MySQL。
参数
说明
备注
connector
连接器类型。
本示例固定值为
mysql。hostname
MySQL数据库的IP地址或者Hostname。
本文填写为RDS MySQL实例的内网地址。
username
MySQL数据库服务的用户名。
无。
password
MySQL数据库服务的密码。
本示例通过使用名为mysql_pw变量的方式填写密码值,避免信息泄露,详情请参见项目变量。
database-name
MySQL数据库名称。
本示例填写为步骤一:准备数据源中创建的数据库electric。
table-name
MySQL表名。
本示例填写为electric或electric_info_sortlistagg。
port
MySQL数据库服务的端口号。
无。
(可选)单击右上方的深度检查和调试,功能详情请参见作业开发地图。
单击部署,单击确定。
在页面,单击目标作业名称操作列下的启动,选择无状态启动。
步骤四:查询结果
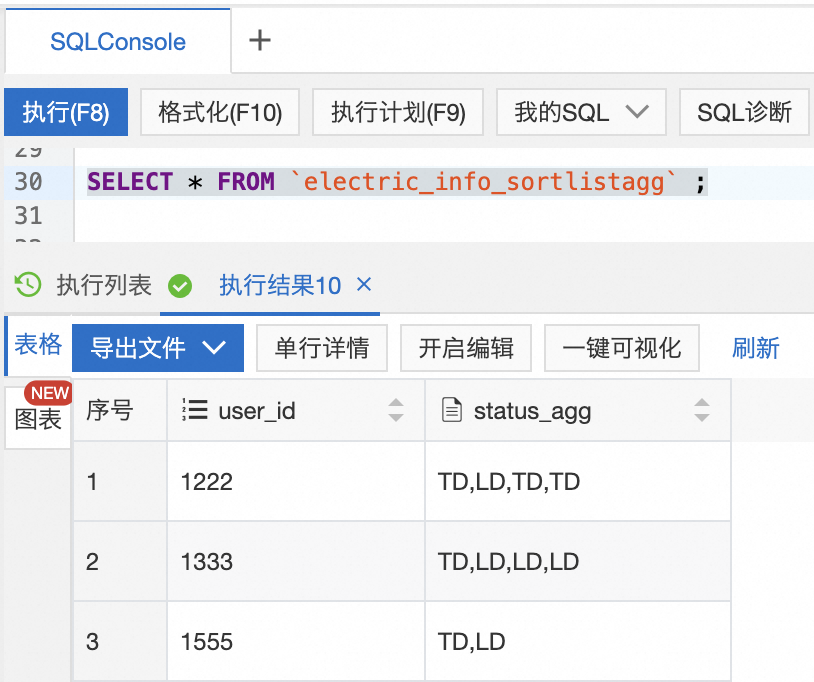
在RDS中使用如下语句查看用户的终端状态按照事件时间升序排列结果。
SELECT * FROM `electric_info_sortlistagg`;结果如下: