本文介绍重启变更报错的详细说明、可能原因及解决方案。
报错说明
当您触发了Elasticsearch实例重启变更时,系统提示“集群状态不健康或存在close索引,不能执行当前操作,建议待集群状态稳定或开启已关闭的索引后再试”。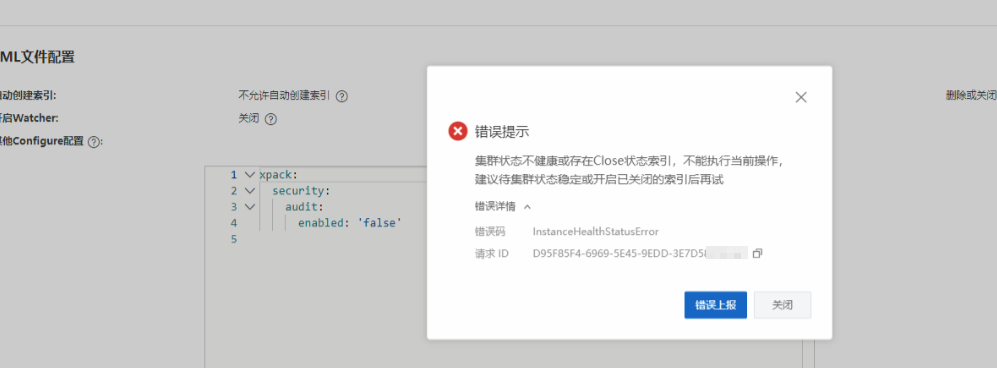
问题原因及解决方案
当集群存在以下情况,重启或变更实例时会报出此类错误:
- 集群中存在close状态的索引。
您可以通过
GET /_cat/indices?v命令查看索引状态。如果索引状态为close,可通过POST /<index_name>/_open将索引状态设置为open。 - 集群处于yellow或red状态。
您可以通过
GET /_cat/health?v命令查看集群状态。常见的异常原因及解决方案如下。常见异常原因 解决方案 shard自动分配,已经达到最大重试次数5次 建议通过 POST /_cluster/reroute?retry_failed=true命令,重新分配分片。某一索引主副本分片分配到一个节点,对应报错信息为:the shard cannot be allocated to the same node on which a copy of the shard already exists 建议将副本设置为0,待集群正常后再设置为1。 已达到节点最大允许同时分配分片个数的限制 当前节点正在分配shard,请耐心等待。您可以通过 GET _cluster/allocation/explain命令,查看完整的未分配原因。节点失联 通过 GET _cat/nodes?v命令,查看节点是否已脱离集群。建议对脱离集群的节点进行重启。磁盘使用率高 磁盘使用率达到水位线,当前节点磁盘已降到85%以下,建议对节点进行重启,使诊断回归正位。 堆内存熔断 建议限流,并将历史索引close降低内存开销。 其他 集群存在主分片未分配,需要关注CPU使用率、堆内存使用情况,结合 GET _cluster/allocation/explain命令,获取shard未分配信息进行分析。 - 集群状态正常,但负载过高。
常见排查方式、异常原因及解决方案如下。
排查方式 常见异常原因 解决方案 - 查看磁盘使用率监控
GET _cat/allocation命令GET _cluster/allocation/explain命令- 查看日志
磁盘使用率达到85% 磁盘使用率达到85%,影响到分片的创建,建议按照以下方式处理。处理后,可通过查看磁盘监控,判断磁盘使用率是否降到85%以下。 - 删除历史索引数据。
- 扩容磁盘。
- 将索引副本数设置为0。
查看CPU使用率监控、热线程 CPU使用率达到85% CPU使用率达到85%,影响到集群的稳定性。需要降低流量或扩容,关注集群总体读或写入QPS监控。 查看堆内存监控、日志、old gc collection count、old gc collecting.ms 堆内存达到75%以上 堆内存过高,将严重影响到降低集群的稳定性,建议按照以下方式处理: - 降低读写量。
- 强制扩容集群规格。
- 将历史索引的状态设置为close,降低内存使用率。
查看load_1m监控 load_1m>CPU核数 load_1m超过CPU核数,说明当前服务器负载大,需要关注集群总体读或写入QPS监控及磁盘吞吐(每秒读写大小)监控,及时降低流量或扩容。 说明- 关于监控指标的详细信息,请参见指标含义与异常处理建议。
- 关于日志的详细信息,请参见查询日志。