Spark Load通过外部的Spark资源实现对导入数据的预处理,提高StarRocks大数据量的导入性能并且节省StarRocks集群的计算资源。Spark Load主要用于初次迁移、大数据量导入StarRocks的场景(数据量可到TB级别)。本文为您介绍Spark Load导入的基本概念、基本原理、使用示例、最佳实践以及常见问题。
背景信息
Spark Load是一种异步导入方式,您需要通过MySQL协议创建Spark类型导入任务,并可以通过SHOW LOAD命令查看导入结果。
本文图片和部分内容来源于开源StarRocks的Bulk load using Apache Spark。
基本概念
Spark ETL:在导入流程中主要负责数据的ETL工作,包括全局字典构建(BITMAP类型)、分区、排序和聚合等。
Broker:是一个独立的无状态进程。封装了文件系统接口,提供StarRocks读取远端存储系统中文件的能力。
全局字典:保存了数据从原始值到编码值映射的数据结构,原始值可以是任意数据类型,而编码后的值为整型。全局字典主要应用于精确去重预计算的场景。
基本原理
用户通过MySQL客户端提交Spark类型导入任务,FE记录元数据并返回用户提交成功。
Spark Load的主要流程如下图所示。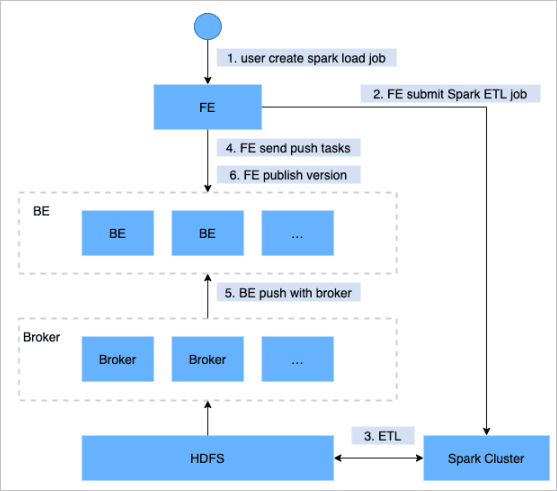
Spark Load任务的执行主要分为以下几个阶段:
向FE提交Spark Load任务。
FE调度提交ETL任务到Spark集群执行。
Spark集群执行ETL完成对导入数据的预处理,包括全局字典构建(BITMAP类型)、分区、排序和聚合等。
ETL任务完成后,FE获取预处理过的每个分片的数据路径,并调度相关的BE执行Push任务。
BE通过Broker读取数据,转化为StarRocks存储格式。
FE调度生效版本,完成导入任务。
全局字典
适用场景
目前StarRocks中BITMAP列是使用类库Roaringbitmap实现的,而Roaringbitmap的输入数据类型只能是整型,因此如果要在导入流程中实现对于BITMAP列的预计算,则需要将输入数据的类型转换成整型。在StarRocks现有的导入流程中,全局字典的数据结构是基于Hive表实现的,保存了原始值到编码值的映射。
构建流程
读取上游数据源的数据,生成一张Hive临时表,记为hive-table。
从hive-table中抽取待去重字段的去重值,生成一张新的Hive表,记为distinct-value-table。
新建一张全局字典表,记为dict-table。一列为原始值,一列为编码后的值。
将distinct-value-table与dict-table进行LEFT JOIN,计算出新增的去重值集合,然后对这个集合使用窗口函数进行编码,此时去重列原始值就多了一列编码后的值,最后将这两列的数据写回dict-table。
将dict-table与hive-table进行JOIN,完成hive-table中原始值替换成整型编码值的工作。
hive-table会被下一步数据预处理的流程所读取,经过计算后导入到StarRocks中。
数据预处理
数据预处理的基本流程如下:
从数据源读取数据,上游数据源可以是HDFS文件,也可以是Hive表。
对读取到的数据完成字段映射、表达式计算,并根据分区信息生成分桶字段bucket-id。
根据StarRocks表的Rollup元数据生成RollupTree。
遍历RollupTree,进行分层的聚合操作,下一个层级的Rollup可以由上一个层级的Rollup计算得来。
每次完成聚合计算后,会根据bucket-id对数据进行分桶然后写入HDFS中。
后续Broker会拉取HDFS中的文件然后导入StarRocks BE节点中。
基本操作
配置ETL集群
Spark作为一种外部计算资源在StarRocks中用来完成ETL工作,未来可能还有其他的外部资源会加入到StarRocks中使用。例如,Spark或GPU用于查询,HDFS或S3用于外部存储,MapReduce用于ETL等,因此引入Resource Management来管理StarRocks使用的这些外部资源。
提交Spark导入任务之前,需要配置执行ETL任务的Spark集群。操作语法如下所示。
-- create spark resource
CREATE EXTERNAL RESOURCE resource_name
PROPERTIES
(
type = spark,
spark_conf_key = spark_conf_value,
working_dir = path,
broker = broker_name,
broker.property_key = property_value
);
-- drop spark resource
DROP RESOURCE resource_name;
-- show resources
SHOW RESOURCES
SHOW PROC "/resources";
-- privileges
GRANT USAGE_PRIV ON RESOURCE resource_name TO user_identityGRANT USAGE_PRIV ON RESOURCE resource_name TO ROLE role_name;
REVOKE USAGE_PRIV ON RESOURCE resource_name FROM user_identityREVOKE USAGE_PRIV ON RESOURCE resource_name FROM ROLE role_name;创建资源
resource-name为StarRocks中配置的Spark资源的名字。
PROPERTIES是Spark资源的相关参数,参数描述如下表所示,更多参数描述请参见Spark Configuration。
参数
描述
type
资源类型。必填参数,目前仅支持Spark。
Spark相关参数
spark.master
必填参数,目前支持yarn。
spark.submit.deployMode
Spark程序的部署模式。必填参数,支持cluster和client两种。
spark.hadoop.fs.defaultFS
Master为YARN时必填。
spark.hadoop.yarn.resourcemanager.address
单点Resource Manager地址。
spark.hadoop.yarn.resourcemanager.ha.enabled
Resource Manager启用HA。默认值为true。
spark.hadoop.yarn.resourcemanager.ha.rm-ids
Resource Manager逻辑ID列表。
spark.hadoop.yarn.resourcemanager.hostname.rm-id
对于每个rm-id,指定Resource Manager对应的主机名。
说明HA Resource Manager只需配置spark.hadoop.yarn.resourcemanager.hostname.rm-id或spark.hadoop.yarn.resourcemanager.address.rm-id中的任意一个。
spark.hadoop.yarn.resourcemanager.address.rm-id
对于每个rm-id,指定host:port以供客户端提交作业。
说明HA Resource Manager只需配置spark.hadoop.yarn.resourcemanager.hostname.rm-id或spark.hadoop.yarn.resourcemanager.address.rm-id中的任意一个。
working_dir
ETL使用的目录。
说明Spark作为ETL资源使用时必填。例如,hdfs://host:port/tmp/starrocks。
broker
Broker名字。
说明Spark作为ETL资源使用时必填。需要使用
ALTER SYSTEM ADD BROKER命令提前完成配置。broker.property_key
Broker读取ETL生成中间文件时需要指定的认证信息等。
创建资源示例如下所示。
-- yarn cluster模式 CREATE EXTERNAL RESOURCE "spark0" PROPERTIES ( "type" = "spark", "spark.master" = "yarn", "spark.submit.deployMode" = "cluster", "spark.jars" = "xxx.jar,yyy.jar", "spark.files" = "/tmp/aaa,/tmp/bbb", "spark.executor.memory" = "1g", "spark.yarn.queue" = "queue0", "spark.hadoop.yarn.resourcemanager.address" = "resourcemanager_host:8032", "spark.hadoop.fs.defaultFS" = "hdfs://namenode_host:9000", "working_dir" = "hdfs://namenode_host:9000/tmp/starrocks", "broker" = "broker0", "broker.username" = "user0", "broker.password" = "password0" ); -- yarn HA cluster模式 CREATE EXTERNAL RESOURCE "spark1" PROPERTIES ( "type" = "spark", "spark.master" = "yarn", "spark.submit.deployMode" = "cluster", "spark.hadoop.yarn.resourcemanager.ha.enabled" = "true", "spark.hadoop.yarn.resourcemanager.ha.rm-ids" = "rm1,rm2", "spark.hadoop.yarn.resourcemanager.hostname.rm1" = "host1", "spark.hadoop.yarn.resourcemanager.hostname.rm2" = "host2", "spark.hadoop.fs.defaultFS" = "hdfs://namenode_host:9000", "working_dir" = "hdfs://namenode_host:9000/tmp/starrocks", "broker" = "broker1" ); -- HDFS HA cluster模式 CREATE EXTERNAL RESOURCE "spark2" PROPERTIES ( "type" = "spark", "spark.master" = "yarn", "spark.hadoop.yarn.resourcemanager.address" = "resourcemanager_host:8032", "spark.hadoop.fs.defaultFS" = "hdfs://myha", "spark.hadoop.dfs.nameservices" = "myha", "spark.hadoop.dfs.ha.namenodes.myha" = "mynamenode1,mynamenode2", "spark.hadoop.dfs.namenode.rpc-address.myha.mynamenode1" = "nn1_host:rpc_port", "spark.hadoop.dfs.namenode.rpc-address.myha.mynamenode2" = "nn2_host:rpc_port", "spark.hadoop.dfs.client.failover.proxy.provider" = "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider", "working_dir" = "hdfs://myha/tmp/starrocks", "broker" = "broker2", "broker.dfs.nameservices" = "myha", "broker.dfs.ha.namenodes.myha" = "mynamenode1,mynamenode2", "broker.dfs.namenode.rpc-address.myha.mynamenode1" = "nn1_host:rpc_port", "broker.dfs.namenode.rpc-address.myha.mynamenode2" = "nn2_host:rpc_port", "broker.dfs.client.failover.proxy.provider" = "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider" );查看资源
show resources;普通账户只能看到自己有USAGE-PRIV使用权限的资源。root和admin账户可以看到所有的资源。
资源权限
资源权限通过GRANT REVOKE来管理,目前仅支持USAGE-PRIV使用权限。您可以将USAGE-PRIV权限赋予某个用户或者某个角色,角色的使用与之前一致。示例如下。
-- 授予spark0资源的使用权限给用户user0 GRANT USAGE_PRIV ON RESOURCE "spark0" TO "user0"@"%"; -- 授予spark0资源的使用权限给角色role0 GRANT USAGE_PRIV ON RESOURCE "spark0" TO ROLE "role0"; -- 授予所有资源的使用权限给用户user0 GRANT USAGE_PRIV ON RESOURCE * TO "user0"@"%"; -- 授予所有资源的使用权限给角色role0 GRANT USAGE_PRIV ON RESOURCE * TO ROLE "role0"; -- 撤销用户user0的spark0资源使用权限 REVOKE USAGE_PRIV ON RESOURCE "spark0" FROM "user0"@"%";
配置Spark客户端
FE底层通过执行spark-submit命令提交Spark任务,因此需要为FE配置Spark客户端,建议使用官方2.4.5或以上版本的Spark 2.x,Spark下载地址下载完成后,请按照以下步骤完成配置:
配置SPARK-HOME环境变量
将Spark客户端放在FE同一台机器上的目录下,并在FE的配置文件中配置spark_home_default_dir指向此目录,此配置项的值默认为FE根目录下的lib/spark2x路径,此配置项不可为空。
配置Spark依赖包
将Spark客户端下的jars文件夹内所有JAR包归档打包成一个ZIP文件,并在FE的配置文件中配置spark_resource_path指向此ZIP文件。如果此配置项为空,则FE会尝试寻找FE根目录下的lib/spark2x/jars/spark-2x.zip文件,如果没有找到则会报文件不存在的错误。
当提交Spark Load任务时,会将归档好的依赖文件上传至远端仓库,默认仓库路径挂在working_dir/{cluster_id}目录下,并以
--spark-repository--{resource-name}命名,表示集群内的一个Resource对应一个远端仓库,远端仓库目录结构参考如下。---spark-repository--spark0/ |---archive-1.0.0/ | |---lib-990325d2c0d1d5e45bf675e54e44fb16-spark-dpp-1.0.0-jar-with-dependencies.jar | |---lib-7670c29daf535efe3c9b923f778f61fc-spark-2x.zip |---archive-1.1.0/ | |---lib-64d5696f99c379af2bee28c1c84271d5-spark-dpp-1.1.0-jar-with-dependencies.jar | |---lib-1bbb74bb6b264a270bc7fca3e964160f-spark-2x.zip |---archive-1.2.0/ | |-...
除了Spark依赖(默认以spark-2x.zip命名),FE还会上传DPP的依赖包至远端仓库。如果此次Spark Load提交的所有依赖文件都已存在远端仓库,则不需要再上传依赖,节省下了每次重复上传大量文件的时间。
配置YARN客户端
FE底层通过YARN命令获取正在运行的Application的状态,以及终止Application,因此需要为FE配置YARN客户端,建议使用官方2.5.2或以上版本的Hadoop 2.x。Hadoop下载地址,下载完成后,请按照以下步骤完成配置:
配置YARN可执行文件路径
将下载好的YARN客户端放在FE同一台机器的目录下,并在FE配置文件中配置yarn_client_path参数,指向YARN的二进制可执行文件,默认为FE根目录下的lib/yarn-client/hadoop/bin/yarn路径。
配置生成YARN所需的配置文件的路径(可选)
当FE通过YARN客户端获取Application的状态,或者终止Application时,默认会在FE根目录下的lib/yarn-config路径下生成执行yarn命令所需的配置文件,此路径可以通过在FE配置文件配置yarn_config_dir参数修改,目前生成的配置文件包括core-site.xml和yarn-site.xml。
创建导入任务
创建语法
LOAD LABEL load_label (data_desc, ...) WITH RESOURCE resource_name [resource_properties] [PROPERTIES (key1=value1, ... )] * load_label: db_name.label_name * data_desc: DATA INFILE ('file_path', ...) [NEGATIVE] INTO TABLE tbl_name [PARTITION (p1, p2)] [COLUMNS TERMINATED BY separator ] [(col1, ...)] [COLUMNS FROM PATH AS (col2, ...)] [SET (k1=f1(xx), k2=f2(xx))] [WHERE predicate] DATA FROM TABLE hive_external_tbl [NEGATIVE] INTO TABLE tbl_name [PARTITION (p1, p2)] [SET (k1=f1(xx), k2=f2(xx))] [WHERE predicate] * resource_properties: (key2=value2, ...)创建导入的详细语法可以执行
HELP SPARK LOAD命令查看帮助。Spark Load的创建导入语法中参数意义如下:Label
导入任务的标识。每个导入任务,都有一个在单DataBase内部唯一的Label。具体规则与Broker Load一致。
数据描述类参数
目前支持的数据源有CSV和Hive table。其他规则与Broker Load一致。
导入作业参数
导入作业参数主要指的是Spark Load创建导入语句中的属于opt_properties部分的参数。导入作业参数是作用于整个导入作业的。规则与Broker Load一致。
Spark资源参数
Spark资源需要提前配置到StarRocks系统中并且赋予用户USAGE-PRIV权限后才能使用Spark Load。当您有临时性的需求,例如增加任务使用的资源而修改Spark configs时,可以设置以下参数,设置仅对本次任务生效,并不影响StarRocks集群中已有的配置。
WITH RESOURCE 'spark0' ( "spark.driver.memory" = "1g", "spark.executor.memory" = "3g" )数据源为Hive表时的导入
如果期望在导入流程中将Hive表作为数据源,则需要先新建一张类型为Hive的外部表,然后提交导入命令时指定外部表的表名即可。
导入流程构建全局字典
适用于StarRocks表聚合列的数据类型为BITMAP类型。在Load命令中指定需要构建全局字典的字段即可,格式为
StarRocks字段名称=bitmap_dict(hive表字段名称)。重要目前只有在上游数据源为Hive表时才支持全局字典的构建。
示例:
上游数据源为HDFS文件时创建导入任务的情况
LOAD LABEL db1.label1 ( DATA INFILE("hdfs://emr-header-1.cluster-xxx:9000/user/starRocks/test/ml/file1") INTO TABLE tbl1 COLUMNS TERMINATED BY "," (tmp_c1,tmp_c2) SET ( id=tmp_c2, name=tmp_c1 ), DATA INFILE("hdfs://emr-header-1.cluster-xxx:9000/user/starRocks/test/ml/file2") INTO TABLE tbl2 COLUMNS TERMINATED BY "," (col1, col2) where col1 > 1 ) WITH RESOURCE 'spark0' ( "spark.executor.memory" = "2g", "spark.shuffle.compress" = "true" ) PROPERTIES ( "timeout" = "3600" );上游数据源是Hive表时创建导入任务的情况
新建Hive资源。
CREATE EXTERNAL RESOURCE hive0 properties ( "type" = "hive", "hive.metastore.uris" = "thrift://emr-header-1.cluster-xxx:9083" );新建Hive外部表。
CREATE EXTERNAL TABLE hive_t1 ( k1 INT, K2 SMALLINT, k3 varchar(50), uuid varchar(100) ) ENGINE=hive properties ( "resource" = "hive0", "database" = "tmp", "table" = "t1" );提交load命令,要求导入的StarRocks表中的列必须在Hive外部表中存在。
LOAD LABEL db1.label1 ( DATA FROM TABLE hive_t1 INTO TABLE tbl1 SET ( uuid=bitmap_dict(uuid) ) ) WITH RESOURCE 'spark0' ( "spark.executor.memory" = "2g", "spark.shuffle.compress" = "true" ) PROPERTIES ( "timeout" = "3600" );
查看导入任务
Spark Load和Broker Load都是异步导入方式。您必须将创建导入的Label记录下来,并且在SHOW LOAD命令中使用此Label来查看导入结果。查看导入的命令在所有导入方式中是通用的,具体语法可执行HELP SHOW LOAD命令查看。
执行以下命令,查看导入任务。
show load order by createtime desc limit 1\G返回信息如下。
*************************** 1. row ***************************
JobId: 76391
Label: label1
State: FINISHED
Progress: ETL:100%; LOAD:100%
Type: SPARK
EtlInfo: unselected.rows=4; dpp.abnorm.ALL=15; dpp.norm.ALL=28133376
TaskInfo: cluster:cluster0; timeout(s):10800; max_filter_ratio:5.0E-5
ErrorMsg: N/A
CreateTime: 2019-07-27 11:46:42
EtlStartTime: 2019-07-27 11:46:44
EtlFinishTime: 2019-07-27 11:49:44
LoadStartTime: 2019-07-27 11:49:44
LoadFinishTime: 2019-07-27 11:50:16
URL: http://1.1.*.*:8089/proxy/application_1586619723848_0035/
JobDetails: {"ScannedRows":28133395,"TaskNumber":1,"FileNumber":1,"FileSize":200000}返回结果中涉及到的参数如下表所示。
参数 | 描述 |
State | 导入任务当前所处的阶段。 任务提交之后状态为PENDING,提交Spark ETL之后状态变为ETL,ETL完成之后FE调度BE执行push操作,状态变为LOADING,push完成并且版本生效后状态变为FINISHED。 导入任务的最终阶段有CANCELLED和FINISHED两个状态,当Load Job处于这两个阶段时导入完成。其中CANCELLED为导入失败,FINISHED为导入成功。 |
Progress | 导入任务的进度描述。包括ETL和LOAD两种进度,对应了导入流程的ETL和LOADING两个阶段。 LOAD的进度范围为0~100%。 说明
|
Type | 导入任务的类型。Spark Load为SPARK。 |
CreateTime | 导入任务的创建时间。 |
EtlStartTime | ETL阶段开始的时间。 |
EtlFinishTime | ETL阶段完成的时间。 |
LoadStartTime | LOADING阶段开始的时间。 |
LoadFinishTime | 整个导入任务完成的时间。 |
JobDetails | 显示作业的详细运行状态,包括导入文件的个数、总大小(字节)、子任务个数、已处理的原始行数等。示例如下。 |
URL | 可以复制输入到浏览器,跳转至相应Application的Web页面。 |
其余返回结果集中参数含义可以参见Broker Load,详情请参见Broker Load。
查看Spark Launcher提交日志
Spark任务提交过程中产生的详细日志,日志默认保存在FE根目录下log/spark_launcher_log路径下,并以spark-launcher-{load-job-id}-{label}.log格式命名,日志会在此目录下保存一段时间,当FE元数据中的导入信息被清理时,相应的日志也会被清理,默认保存时间为3天。
取消导入任务
当Spark Load作业状态不为CANCELLED或FINISHED时,您可以手动取消。取消时需要指定待取消导入任务的Label。取消导入命令语法可以执行HELP CANCEL LOAD命令查看。
相关系统配置
以下配置属于Spark Load的系统级别配置,也就是作用于所有Spark Load导入任务的配置,主要通过修改fe.conf来调整配置值。
参数 | 描述 |
enable-spark-load | 开启Spark Load和创建Resource功能。 默认值为false,表示关闭此功能。 |
spark-load-default-timeout-second | 任务默认超时时间。 默认值为259200秒(3天)。 |
spark-home-default-dir | Spark客户端路径。 默认值为fe/lib/spark2x。 |
spark-launcher-log-dir | 打包好的Spark依赖文件路径。 默认值为空。 |
spark-launcher-log-dir | Spark客户端的提交日志存放的目录。 默认值为fe/log/spark-launcher-log。 |
yarn-client-path | YARN二进制可执行文件路径。 默认值为fe/lib/yarn-client/hadoop/bin/yarn。 |
yarn-config-dir | YARN配置文件生成路径。 默认值为fe/lib/yarn-config。 |
最佳实践
使用Spark Load最适合的场景是原始数据在文件系统(HDFS)中,数据量在几十GB到TB级别。小数据量还是建议使用Stream Load或者Broker Load。
完整Spark Load导入示例,请参见03_sparkLoad2StarRocks.md。