Flink Connector内部实现是通过缓存并批量由Stream Load导入。本文为您介绍Flink Connector的使用方式及示例。
背景信息
因为Flink官方只提供了flink-connector-jdbc,不足以满足导入性能要求,所以新增了flink-connector-starrocks,其内部实现是通过缓存并批量由Stream Load导入。
使用方式
您可以下载源码进行测试:下载flink-connector-starrocks源码。
将以下内容添加pom.xml中。
<dependency>
<groupId>com.starrocks</groupId>
<artifactId>flink-connector-starrocks</artifactId>
<!-- for flink-1.11, flink-1.12 -->
<version>x.x.x_flink-1.11</version>
<!-- for flink-1.13 -->
<version>x.x.x_flink-1.13</version>
</dependency>说明 您可以在版本信息页面,查看Latest Version信息,替换代码中的
x.x.x。代码示例如下:
- 方式一
// -------- sink with raw json string stream -------- fromElements(new String[]{ "{\"score\": \"99\", \"name\": \"stephen\"}", "{\"score\": \"100\", \"name\": \"lebron\"}" }).addSink( StarRocksSink.sink( // the sink options StarRocksSinkOptions.builder() .withProperty("jdbc-url", "jdbc:mysql://fe1_ip:query_port,fe2_ip:query_port,fe3_ip:query_port?xxxxx") .withProperty("load-url", "fe1_ip:http_port;fe2_ip:http_port;fe3_ip:http_port") .withProperty("username", "xxx") .withProperty("password", "xxx") .withProperty("table-name", "xxx") .withProperty("database-name", "xxx") .withProperty("sink.properties.format", "json") .withProperty("sink.properties.strip_outer_array", "true") .build() ) ); // -------- sink with stream transformation -------- class RowData { public int score; public String name; public RowData(int score, String name) { ...... } } fromElements( new RowData[]{ new RowData(99, "stephen"), new RowData(100, "lebron") } ).addSink( StarRocksSink.sink( // the table structure TableSchema.builder() .field("score", DataTypes.INT()) .field("name", DataTypes.VARCHAR(20)) .build(), // the sink options StarRocksSinkOptions.builder() .withProperty("jdbc-url", "jdbc:mysql://fe1_ip:query_port,fe2_ip:query_port,fe3_ip:query_port?xxxxx") .withProperty("load-url", "fe1_ip:http_port;fe2_ip:http_port;fe3_ip:http_port") .withProperty("username", "xxx") .withProperty("password", "xxx") .withProperty("table-name", "xxx") .withProperty("database-name", "xxx") .withProperty("sink.properties.column_separator", "\\x01") .withProperty("sink.properties.row_delimiter", "\\x02") .build(), // set the slots with streamRowData (slots, streamRowData) -> { slots[0] = streamRowData.score; slots[1] = streamRowData.name; } ) ); - 方式二
// create a table with `structure` and `properties` // Needed: Add `com.starrocks.connector.flink.table.StarRocksDynamicTableSinkFactory` to: `src/main/resources/META-INF/services/org.apache.flink.table.factories.Factory` tEnv.executeSql( "CREATE TABLE USER_RESULT(" + "name VARCHAR," + "score BIGINT" + ") WITH ( " + "'connector' = 'starrocks'," + "'jdbc-url'='jdbc:mysql://fe1_ip:query_port,fe2_ip:query_port,fe3_ip:query_port?xxxxx'," + "'load-url'='fe1_ip:http_port;fe2_ip:http_port;fe3_ip:http_port'," + "'database-name' = 'xxx'," + "'table-name' = 'xxx'," + "'username' = 'xxx'," + "'password' = 'xxx'," + "'sink.buffer-flush.max-rows' = '1000000'," + "'sink.buffer-flush.max-bytes' = '300000000'," + "'sink.buffer-flush.interval-ms' = '5000'," + "'sink.properties.column_separator' = '\\x01'," + "'sink.properties.row_delimiter' = '\\x02'," + "'sink.max-retries' = '3'" + "'sink.properties.*' = 'xxx'" + // stream load properties like `'sink.properties.columns' = 'k1, v1'` ")" );
其中,Sink选项如下表所示。
| 参数 | 是否必选 | 默认值 | 类型 | 描述 |
|---|---|---|---|---|
| connector | 是 | 无 | String | starrocks。 |
| jdbc-url | 是 | 无 | String | 用于在StarRocks中执行查询操作。 |
| load-url | 是 | 无 | String | 指定FE的IP和HTTP端口,格式为fe_ip:http_port;fe_ip:http_port ,多个时使用半角分号(;)分隔。 |
| database-name | 是 | 无 | String | StarRocks数据库名称。 |
| table-name | 是 | 无 | String | StarRocks表名称。 |
| username | 是 | 无 | String | StarRocks连接用户名。 |
| password | 是 | 无 | String | StarRocks连接密码。 |
| sink.semantic | 否 | at-least-once | String | 取值为at-least-once或exactly-once。 |
| sink.buffer-flush.max-bytes | 否 | 94371840(90M) | String | Buffer可容纳的最大数据量,取值范围为64 MB~10 GB。 |
| sink.buffer-flush.max-rows | 否 | 500000 | String | Buffer可容纳的最大数据行数,取值范围为64,000~5000,000。 |
| sink.buffer-flush.interval-ms | 否 | 300000 | String | Buffer刷新时间间隔,取值范围为 1000 ms~3600000 ms。 |
| sink.max-retries | 否 | 1 | String | 最大重试次数,取值范围为0~10。 |
| sink.connect.timeout-ms | 否 | 1000 | String | 连接到load-url的超时时间,取值范围为100~60000。 |
| sink.properties.* | 否 | 无 | String | Sink属性。 |
重要
- 为了保证Sink数据的Exactly-once语义,需要外部系统的Two-phase Commit机制。由于StarRocks无此机制,所以需要依赖Flink的checkpoint-interval,在每次Checkpoint时保存批数据以及其Label,在Checkpoint完成后的第一次invoke中阻塞flush所有缓存在state中的数据,以此达到Exactly-once。但如果StarRocks终止了,会导致您的Flink Sink Stream算子长时间阻塞,并引起Flink的监控报警或强制退出。
- 默认使用CSV格式进行导入,您可以通过指定sink.properties.row_delimiter(该参数自StarRocks 1.15.0版本开始支持)为\\x02,sink.properties.column_separator为\\x01,来自定义行分隔符与列分隔符。
- 如果遇到导入停止的情况,请尝试增加Flink任务的内存。
- 如果代码运行正常且能接收到数据,但是写入不成功时,请确认当前机器是否能访问BE的http_port端口,即能ping通BE服务使用的IP地址。
例如,如果一台机器有外网和内网IP,且FE或BE的http_port均可通过外网
ip:port访问,集群里绑定的IP为内网IP,任务里loadurl写的FE外网ip:http_port,FE会将写入任务转发给BE内网ip:port,此时如果Client机器ping不通BE的内网IP就会写入失败。
示例:使用Flink-connector写入实现MySQL数据同步
基本原理
通过Flink-cdc和StarRocks-migrate-tools(简称smt)可以实现MySQL数据的秒级同步。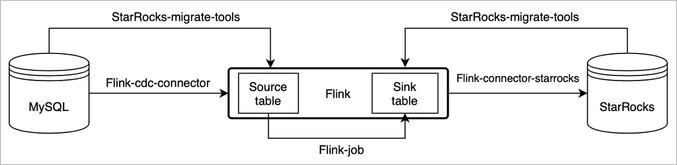
说明 本文图片和部分内容来源于开源StarRocks的Realtime synchronization from MySQL。
smt可以根据MySQL和StarRocks的集群信息和表结构自动生成Source table和Sink table的建表语句。
操作步骤
- 准备工作
- 下载Flink。
推荐使用1.13,最低支持1.11版本。
- 下载Flink CDC connector。
下载对应Flink版本的Flink-MySQL-CDC。
- 下载Flink StarRocks connector。重要 1.13、1.11和1.12版本使用不同的connector。
- 下载Flink。
- 复制flink-sql-connector-mysql-cdc-xxx.jar,flink-connector-starrocks-xxx.jar到flink-xxx/lib/下。
- 下载smt.tar.gz,解压缩并修改配置文件。相关配置项描述如下:
db:修改为MySQL的连接信息。be_num:需要配置成StarRocks集群的节点数。[table-rule.1]:匹配规则,可以根据正则表达式匹配数据库和表名生成建表的SQL,也可以配置多个规则。flink.starrocks.*:StarRocks的集群配置信息。
代码示例如下。[db] host = 192.168.**.** port = 3306 user = root password = [other] # number of backends in StarRocks be_num = 3 # `decimal_v3` is supported since StarRocks-1.18.1 use_decimal_v3 = false # file to save the converted DDL SQL output_dir = ./result [table-rule.1] # pattern to match databases for setting properties database = ^console_19321.*$ # pattern to match tables for setting properties table = ^.*$ ############################################ ### flink sink configurations ### DO NOT set `connector`, `table-name`, `database-name`, they are auto-generated ############################################ flink.starrocks.jdbc-url=jdbc:mysql://192.168.**.**:9030 flink.starrocks.load-url= 192.168.**.**:8030 flink.starrocks.username=root flink.starrocks.password= flink.starrocks.sink.properties.column_separator=\x01 flink.starrocks.sink.properties.row_delimiter=\x02 flink.starrocks.sink.buffer-flush.interval-ms=15000 - 执行
starrocks-migrate-tool命令,将所有建表语句都生成在result目录下。您可以通过ls result命令,查看result目录。flink-create.1.sql smt.tar.gz starrocks-create.all.sql flink-create.all.sql starrocks-create.1.sql - 执行以下命令,生成StarRocks的表结构。
Mysql -h<FE的IP地址> -P9030 -uroot -p < starrocks-create.1.sql - 执行以下命令,生成Flink table,同步任务会持续执行。
bin/sql-client.sh -f flink-create.1.sql重要 如果是Flink 1.13之前的版本可能无法直接执行该脚本,需要逐行提交,并且需要打开MySQL binlog。 - 执行以下命令,查看任务状态。
bin/flink list -running您可以通过Flink WebUI或者$FLINK_HOME/log目录下的日志文件查看任务的详细信息和执行状态。
使用本示例时,需要注意以下信息:
- 如果有多组规则,则需要给每一组规则匹配database,table和flink-connector的配置。代码示例如下。
[table-rule.1] # pattern to match databases for setting properties database = ^console_19321.*$ # pattern to match tables for setting properties table = ^.*$ ############################################ ### flink sink configurations ### DO NOT set `connector`, `table-name`, `database-name`, they are auto-generated ############################################ flink.starrocks.jdbc-url=jdbc:mysql://192.168.**.**:9030 flink.starrocks.load-url= 192.168.**.**:8030 flink.starrocks.username=root flink.starrocks.password= flink.starrocks.sink.properties.column_separator=\x01 flink.starrocks.sink.properties.row_delimiter=\x02 flink.starrocks.sink.buffer-flush.interval-ms=15000 [table-rule.2] # pattern to match databases for setting properties database = ^database2.*$ # pattern to match tables for setting properties table = ^.*$ ############################################ ### flink sink configurations ### DO NOT set `connector`, `table-name`, `database-name`, they are auto-generated ############################################ flink.starrocks.jdbc-url=jdbc:mysql://192.168.**.**:9030 flink.starrocks.load-url= 192.168.**.**:8030 flink.starrocks.username=root flink.starrocks.password= # 如果导入数据不方便选出合适的分隔符,则可以考虑使用JSON格式,但是会有一定的性能损失,使用方法:用以下参数替换flink.starrocks.sink.properties.column_separator和flink.starrocks.sink.properties.row_delimiter参数。 flink.starrocks.sink.properties.strip_outer_array=true flink.starrocks.sink.properties.format=json说明 Flink.starrocks.sink系列的参数,可以给不同的规则配置不同的导入频率等。 - 针对分库分表的大表可以单独配置一个规则。例如,有两个数据库edu_db_1和edu_db_2,每个数据库下面分别有course_1、course_2两张表,并且所有表的数据结构都是相同的,通过如以下配置把他们导入StarRocks的一张表中进行分析。
[table-rule.3] # pattern to match databases for setting properties database = ^edu_db_[0-9]*$ # pattern to match tables for setting properties table = ^course_[0-9]*$ ############################################ ### flink sink configurations ### DO NOT set `connector`, `table-name`, `database-name`, they are auto-generated ############################################ flink.starrocks.jdbc-url=jdbc:mysql://192.168.**.**:9030 flink.starrocks.load-url= 192.168.**.**:8030 flink.starrocks.username=root flink.starrocks.password= flink.starrocks.sink.properties.column_separator=\x01 flink.starrocks.sink.properties.row_delimiter=\x02 flink.starrocks.sink.buffer-flush.interval-ms=5000配置后会自动生成一个多对一的导入关系,在StarRocks默认生成的表名是course__auto_shard,也可以自行在生成的配置文件中修改。
- 如果在
sql-client中命令行执行建表和同步任务,需要做对反斜线(\)字符进行转义。代码示例如下。'sink.properties.column_separator' = '\\x01' 'sink.properties.row_delimiter' = '\\x02'