本文汇总了Spark使用时的常见问题。
Spark Core
Spark SQL
PySpark
Spark Streaming
spark-submit
在哪里可以查看Spark历史作业?
您可以在EMR控制台目标集群的访问链接与端口页签,单击Spark UI链接,即可查看到Spark历史作业运行信息。访问UI详情,请参见通过控制台访问开源组件Web界面。
是否支持Standalone模式提交Spark作业?
不支持。E-MapReduce支持使用Spark on YARN以及Spark on Kubernetes模式提交作业,不支持Standalone和Mesos模式。
如何减少Spark2命令行工具的日志输出?
EMR DataLake集群选择Spark2服务后,使用spark-sql和spark-shell等命令行工具时默认输出INFO级别日志,如果想减少日志输出,可以修改log4j日志级别。具体操作如下:
在运行命令行工具的节点(例如,master节点)新建一个log4j.properties配置文件,也可以从默认配置文件复制,复制命令如下所示。
cp /etc/emr/spark-conf/log4j.properties /new/path/to/log4j.properties修改新配置文件的日志级别。
log4j.rootCategory=WARN, console修改Spark服务spark-defaults.conf配置文件中的配置项spark.driver.extraJavaOptions,将参数值中的-Dlog4j.configuration=file:/etc/emr/spark-conf/log4j.properties替换为-Dlog4j.configuration=file:/new/path/to/log4j.properties。
重要路径需要添加file:前缀。
如何使用Spark3的小文件合并功能?
您可以通过设置参数spark.sql.adaptive.merge.output.small.files.enabled为true,来自动合并小文件。由于合并后的文件会压缩,如果您觉得合并后的文件太小,可以适当调大参数spark.sql.adaptive.advisoryOutputFileSizeInBytes的值,默认值为256 MB。
如何处理SparkSQL数据倾斜?
针对Spark2,处理方式如下:
读取表时过滤无关数据,例如null。
广播小表(Broadcast)。
select /*+ BROADCAST (table1) */ * from table1 join table2 on table1.id = table2.id根据倾斜key,分离倾斜数据。
select * from table1_1 join table2 on table1_1.id = table2.id union all select /*+ BROADCAST (table1_2) */ * from table1_2 join table2 on table1_2.id = table2.id倾斜key已知时,打散数据。
select id, value, concat(id, (rand() * 10000) % 3) as new_id from A select id, value, concat(id, suffix) as new_id from ( select id, value, suffix from B Lateral View explode(array(0, 1, 2)) tmp as suffix)倾斜key未知时,打散数据。
select t1.id, t1.id_rand, t2.name from ( select id , case when id = null then concat(‘SkewData_’, cast(rand() as string)) else id end as id_rand from test1 where statis_date = ‘20221130’) t1 left join test2 t2 on t1.id_rand = t2.id
针对Spark3,可以在EMR控制台Spark3服务的配置页签,修改spark.sql.adaptive.enabled和spark.sql.adaptive.skewJoin.enabled的参数值为true。
如何指定PySpark使用Python 3版本?
下面内容以可选服务为Spark2,EMR-5.7.0版本的DataLake集群为例,介绍如何指定PySpark使用Python 3版本。
您可以通过以下两种方式修改Python的版本:
临时生效方式
通过SSH方式登录集群,详情请参见登录集群。
执行以下命令,修改Python的版本。
export PYSPARK_PYTHON=/usr/bin/python3执行以下命令,查看Python的版本。
pyspark当返回信息中包含如下信息时,表示已修改Python版本为Python 3。
Using Python version 3.6.8
永久生效方式
通过SSH方式登录集群,详情请参见登录集群。
修改配置文件。
执行以下命令,打开文件profile。
vi /etc/profile按下
i键进入编辑模式。在profile文件末尾添加以下信息,以修改Python的版本。
export PYSPARK_PYTHON=/usr/bin/python3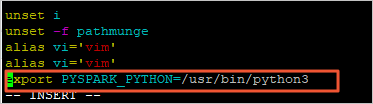
按下
Esc键退出编辑模式,输入:wq保存并关闭文件。
执行以下命令,重新执行刚修改的配置文件,使之立即生效。
source /etc/profile执行以下命令,查看Python的版本。
pyspark当返回信息中包含如下信息时,表示已修改Python版本为Python 3。
Using Python version 3.6.8
为什么Spark Streaming作业运行一段时间后无故结束?
首先检查Spark版本是否是1.6之前版本,如果是的话,请更新Spark版本。
Spark 1.6之前版本存在内存泄漏的问题,会导致Container被中止掉。
检查自己的代码在内存使用上有没有做好优化。
为什么Spark Streaming作业已经结束,但是E-MapReduce控制台显示作业状态还处于“运行中”?
检查作业提交方式是否为Yarn-Client模式,因为E-MapReduce对Yarn-Client模式的Spark Streaming作业的状态监控存在问题,所以请修改为Yarn-Cluster模式。
为什么在启用了Kerberos的EMR集群中,使用YARN-Cluster模式执行spark-submit时会报错java.lang.ClassNotFoundException?
具体报错信息如下图。
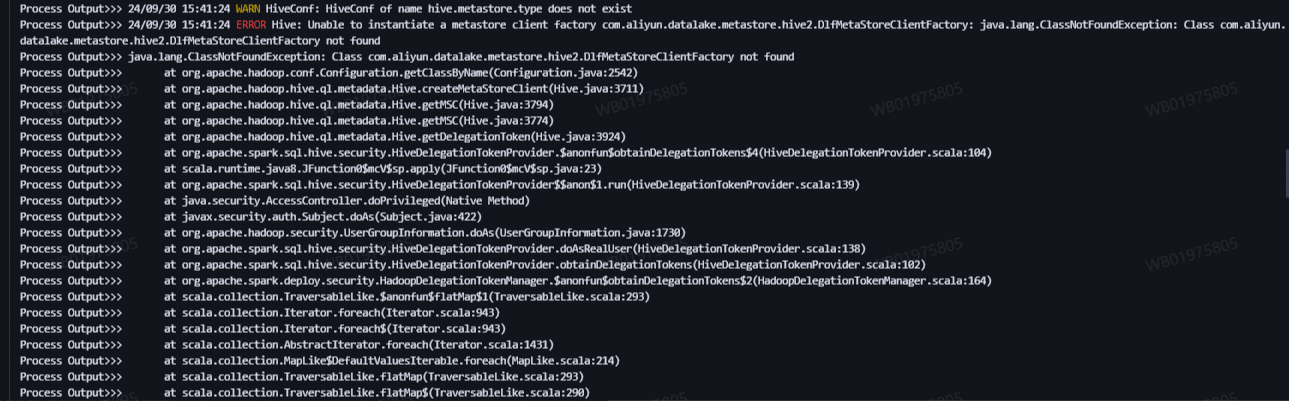
原因分析:EMR集群开启Kerberos之后,在YARN-Cluster模式下,Driver的classpath不会自动扩展以包含指定目录中的JAR文件,从而导致执行Spark任务时报错。
解决方案:在EMR集群开启Kerberos之后,使用spark-submit在YARN-Cluster模式下提交任务时,需要增加--jars参数。除了用户程序本身依赖的JAR包外,还需要添加/opt/apps/METASTORE/metastore-current/hive2目录中的所有JAR包。
在YARN-Cluster模式下,--jars参数中的所有依赖必须以“,”分隔,不支持目录形式。
例如,如果您的应用程序JAR包为 /opt/apps/SPARK3/spark3-current/examples/jars/spark-examples_2.12-3.5.3-emr.jar,则 spark-submit 命令如下:
spark-submit --deploy-mode cluster --class org.apache.spark.examples.SparkPi --master yarn \
--jars $(ls /opt/apps/METASTORE/metastore-current/hive2/*.jar | tr '\n' ',') \
/opt/apps/SPARK3/spark3-current/examples/jars/spark-examples_2.12-3.5.3-emr.jar