本文为您介绍在E-MapReduce中如何使用Hive客户端、Beeline、JDBC三种方式连接Hive。
前提条件
注意事项
操作步骤
普通集群
通过Hive客户端连接
执行以下命令,连接Hive。
hive可选: 执行
quit;或exit;,可以退出Hive。
通过Beeline客户端连接
执行以下命令,连接Hive。
beeline -u jdbc:hive2://master-1-1:10000可选: 执行
!quit或!exit,可以退出Beeline。
通过JDBC方式连接
在执行本操作之前,请确保您已安装Java环境及Java编程工具,并已正确配置相关环境变量。
在
pom.xml文件中配置项目依赖(hadoop-common和hive-jdbc)。本示例新增的项目依赖如下所示。<dependencies> <dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-jdbc</artifactId> <version>3.1.3</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>3.2.1</version> </dependency> </dependencies>请确保hadoop-common和hive-jdbc的版本信息与EMR集群中Hadoop-Common和Hive的软件信息保持一致。软件信息可以在EMR控制台目标集群基础信息页签的软件信息区域查看。
编写代码,连接HiveServer2并操作Hive表数据。示例代码如下所示。
import java.sql.*; public class App { private static String driverName = "org.apache.hive.jdbc.HiveDriver"; public static void main(String[] args) throws SQLException { try { Class.forName(driverName); } catch (ClassNotFoundException e) { e.printStackTrace(); } Connection con = DriverManager.getConnection( "jdbc:hive2://<Master节点的公网IP地址>:10000", "root", ""); Statement stmt = con.createStatement(); String sql = "select * from sample_tbl limit 10"; ResultSet res = stmt.executeQuery(sql); while (res.next()) { System.out.println(res.getString(1) + "\t" + res.getString(2)); } } }说明使用该方式需要开放10000端口,详情请参见管理安全组。
验证打包项目工程(即生成的JAR包),并上传JAR包至运行环境。
重要JAR包的运行需要依赖hadoop-common和hive-jdbc。如果运行环境的环境变量中未包含这两个依赖包,您需要下载并配置这些依赖包,或者将这两个依赖包直接打包在一起。运行JAR包时,如果缺少这两个依赖包,则会提示以下错误:
缺失hadoop-common:提示
java.lang.NoClassDefFoundError: org/apache/hadoop/conf/Configuration。缺失hive-jdbc:提示
java.lang.ClassNotFoundException: org.apache.hive.jdbc.HiveDriver。
本示例生成的JAR包为
emr-hiveserver2-1.0.jar,需将该JAR包上传至E-MapReduce集群的Master节点。测试JAR包是否可以正常运行。
重要运行JAR包的服务器与E-MapReduce集群需要在同一个VPC和安全组下,并且网络可达。如果两者的VPC不同或网络环境不同,则需要通过公网地址访问,或先使用网络产品打通两者的网络,再通过内网访问。网络连通性测试方法:
公网:
telnet master-1-1的公网IP地址 10000内网:
telnet master-1-1的内网IP地址 10000
java -jar emr-hiveserver2-1.0.jar
高安全集群
通过Hive客户端连接
执行以下命令,进入Kerberos的admin.local工具。
如果您是使用root用户,登录KDC(Kerberos的服务端程序)所在的master-1-1节点,则可以执行以下命令,直接进入admin工具。
kadmin.local当返回信息中包含如下信息时,表示已进入admin.local命令行。
Authenticating as principal hadoop/admin@EMR.C-85D4B8D74296****.COM with password. kadmin.local:如果您登录的是其他节点或者使用Gateway时,则可以通过填写admin-user和admin-password进入admin工具。
kadmin -p <admin-user> -w <admin-password>说明如果您使用的是EMR自建的KDC,则参数:
<admin-user>:固定值为root/admin。<admin-password>:您可以在E-MapReduce控制台,Kerberos服务的配置页面,获取admin_pwd的参数值。
当返回信息中包含如下信息时,表示已进入admin命令行。
Authenticating as principal root/admin with password. kadmin:
执行以下命令,创建用户名为test的Principal。
本文示例密码设置为123456。
addprinc -pw 123456 test当返回信息中包含如下信息时,表示创建成功。
Principal "test@EMR.C-85D4B8D74296****.COM" created.说明需要记录用户名和密码,在创建TGT(Ticket Granting Ticket)时会用到。
执行
quit命令,可以退出Kerberos的admin.local工具。登录您需要运行Hive Client的机器,执行以下命令,创建并切换至test用户。
useradd test su test执行以下命令,创建TGT。
kinit回车后输入test用户的密码,本文示例密码为123456。
直接使用
hive命令访问Hive Client。hive
通过Beeline客户端连接
执行以下命令,进入Kerberos的admin.local工具。
如果您是使用root用户,登录KDC(Kerberos的服务端程序)所在的master-1-1节点,则可以执行以下命令,直接进入admin工具。
kadmin.local当返回信息中包含如下信息时,表示已进入admin.local命令行。
Authenticating as principal hadoop/admin@EMR.C-85D4B8D74296****.COM with password. kadmin.local:如果您登录的是其他节点或者使用Gateway时,则可以通过填写admin-user和admin-password进入admin工具。
kadmin -p <admin-user> -w <admin-password>说明如果您使用的是EMR自建的KDC,则参数:
<admin-user>:固定值为root/admin。<admin-password>:您可以在E-MapReduce控制台,Kerberos服务的配置页面,获取admin_pwd的参数值。
当返回信息中包含如下信息时,表示已进入admin命令行。
Authenticating as principal root/admin with password. kadmin:
执行以下命令,创建用户名为test的Principal。
本文示例密码设置为123456。
addprinc -pw 123456 test当返回信息中包含如下信息时,表示创建成功。
Principal "test@EMR.C-85D4B8D74296****.COM" created.说明需要记录用户名和密码,在创建TGT(Ticket Granting Ticket)时会用到。
执行
quit命令,可以退出Kerberos的admin.local工具。登录您需要运行Hive Client的机器,执行以下命令,创建并切换至test用户。
useradd test su test执行以下命令,创建TGT。
kinit回车后输入test用户的密码,本文示例密码为123456。
执行以下命令,访问Hive Client。
beeline -u "jdbc:hive2://master-1-1.c-56187feb57f0****.cn-hangzhou.emr.aliyuncs.com:10000/;principal=hive/_HOST@EMR.c-56187feb57f0****.COM"其中,以下信息需要您按照实际情况替换:
master-1-1.c-56187feb57f0****.cn-hangzhou.emr.aliyuncs.com:完整的主机名(包括域名)。您可以通过在HiveServer2服务的节点(通常是master-1-1节点)执行hostname -f命令获取。EMR.c-56187feb57f0****.COM:realm名称。您可以在EMR控制台Kerberos服务的配置页签,搜索并查看realm参数,参数值即为该realm名称。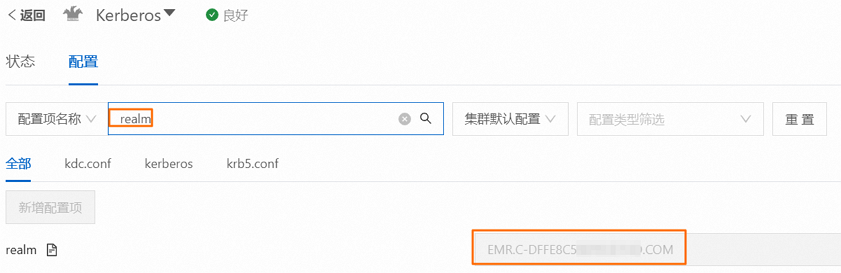
高可用集群
通过Beeline客户端连接
根据您所选择的服务发现模式(zooKeeper 或 multiServers),使用以下相应的命令来配置Beeline连接。
使用zooKeeper模式
beeline -u 'jdbc:hive2://master-1-1:2181,master-1-2:2181,master-1-3:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2'使用multiServers模式
beeline -u 'jdbc:hive2://master-1-1:10000,master-1-2:10000,master-1-3:10000/default;serviceDiscoveryMode=multiServers'