EMR支持CRD、spark-submit和控制台终端三种方式提交作业。本文为您介绍如何通过这三种方式提交Spark作业。
前提条件
已在EMR on ACK控制台创建Spark集群,详情请参见创建集群。
注意事项
在本文的示例中,JAR包已经直接打包在了镜像中。如果您使用的是自己的JAR包,您可以将其上传到阿里云OSS。上传操作请参见简单上传。
此时,需要您修改命令中的local:///opt/spark/examples/spark-examples.jar为您OSS上存放JAR包的真实路径,路径格式为oss://<yourBucketName>/<path>.jar。
提交作业
方式一:使用CRD方式提交作业
通过kubectl连接Kubernetes集群,详情请参见获取集群KubeConfig并通过kubectl工具连接集群。
新建spark-pi.yaml文件,文件内容如下。
apiVersion: "sparkoperator.k8s.io/v1beta2" kind: SparkApplication metadata: name: spark-pi-simple spec: type: Scala sparkVersion: 3.2.1 mainClass: org.apache.spark.examples.SparkPi mainApplicationFile: "local:///opt/spark/examples/spark-examples.jar" arguments: - "1000" driver: cores: 1 coreLimit: 1000m memory: 4g executor: cores: 1 coreLimit: 1000m memory: 8g memoryOverhead: 1g instances: 1本文示例中的参数描述,请参见spark-on-k8s-operator。
说明文件名您可以自定义,本文以spark-pi.yaml为例介绍。
本文以Spark 3.2.1(EMR-5.6.0)版本为例,其他版本时请修改sparkVersion的配置。
执行如下命令,提交作业。
kubectl apply -f spark-pi.yaml --namespace <集群对应的namespace>本文示例代码中的
<集群对应的namespace>,需要替换为集群的命名空间,您可以登录E-MapReduce on ACK控制台,在集群详情页面查看。返回如下信息。
sparkapplication.sparkoperator.k8s.io/spark-pi-simple created说明spark-pi-simple为本示例提交任务后的作业名。可选:您可以在作业详情页面查看已创建的作业信息。
方式二:使用spark-submit方式提交作业
通过kubectl连接Kubernetes集群,详情请参见获取集群KubeConfig并通过kubectl工具连接集群。
执行以下命令,安装阿里云EMR提供的emr-spark-ack工具并授权。
wget https://ecm-repo-cn-hangzhou.oss-cn-hangzhou.aliyuncs.com/emr-on-ack/util/emr-spark-ack chmod 755 emr-spark-ack使用emr-spark-ack工具提交作业。
提交作业的语法如下。
./emr-spark-ack -n <集群对应的namespace> <spark命令>说明语法中的
<spark命令>支持spark-submit、spark-sql、spark-shell和pyspark四种,语法和Spark本身完全一致。Cluster模式示例
通过spark-submit提交spark-pi作业。
./emr-spark-ack -n <集群对应的namespace> spark-submit \ --name spark-pi-submit \ --deploy-mode cluster \ --class org.apache.spark.examples.SparkPi \ local:///opt/spark/examples/spark-examples.jar \ 1000Client模式示例
spark-sql命令方式
# 本地准备sql文件 echo "select 1+1">test.sql # 提交作业 ./emr-spark-ack -n <集群对应的namespace> spark-sql -f test.sql在Spark 3及以上集群版本(EMR-5.X版本)中,emr-spark-ack工具支持本地依赖自动上传,提交命令里面的本地文件依赖,包括
--jars,--files和-f等参数中传入的本地文件,会自动上传到EMR on ACK集群内,用于K8s环境的作业提交。代码示例及返回信息见下图。
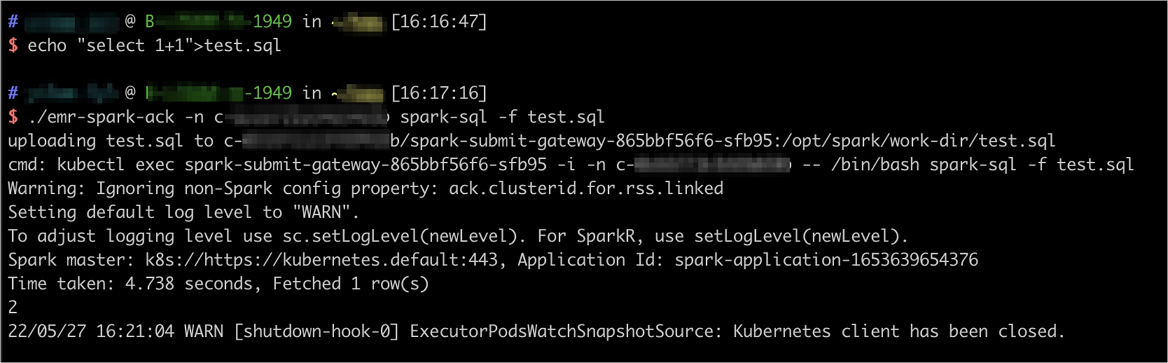
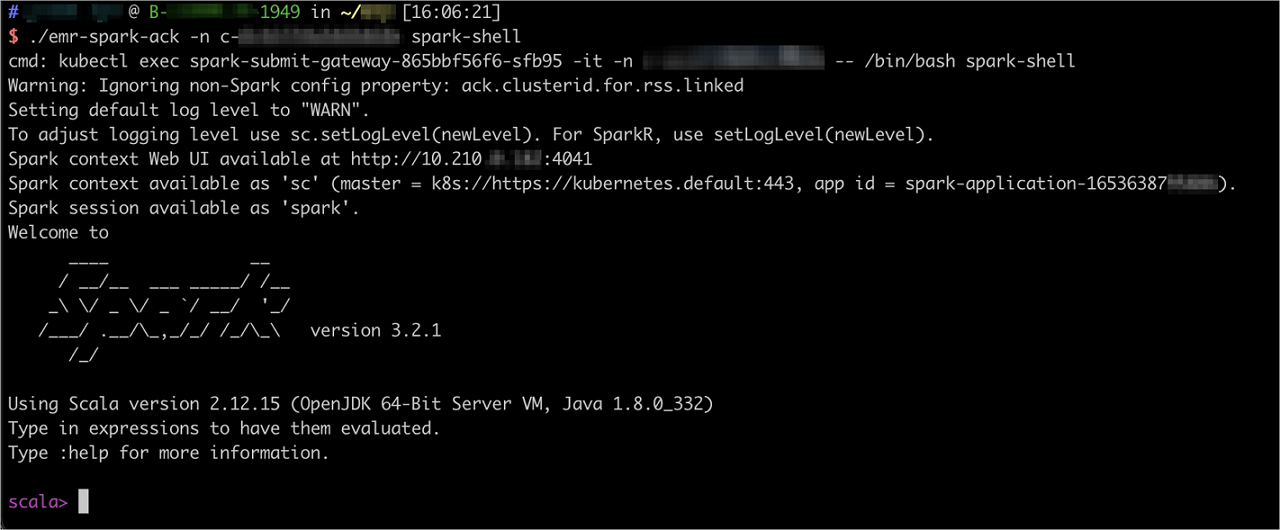
spark-shell命令方式
./emr-spark-ack -n <集群对应的namespace> spark-shell代码示例及返回信息见下图。
可选:您可以在作业详情页面,查看已创建的作业信息。
可选:使用emr-spark-ack工具终止作业。
终止作业的语法如下。
./emr-spark-ack -n <集群对应的namespace> kill <Spark_app_id>说明语法中的
<Spark_app_id>是emr-spark-ack工具在提交作业时生成的,您可以在输出日志中查看。
方式三:使用控制台终端方式提交作业
进入访问链接与端口页面。
登录EMR on ACK。
在EMR on ACK页面,单击目标集群的集群名。
单击上方的访问链接与端口页签。
在访问链接与端口页面,单击SparkSubmitGateway UI对应的链接。
即可进入Shell终端。
在Shell终端中,可以通过以下两种方式运行Spark命令。
spark-sql命令方式
spark-sql进入spark-sql后,您可以直接运行Spark命令进行交互式查询。
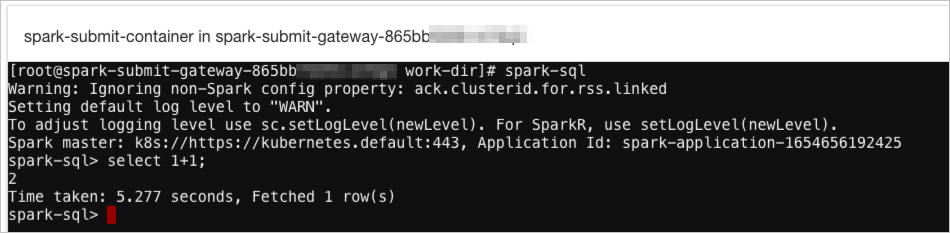
spark-submit命令方式
spark-submit \ --name spark-pi-submit \ --deploy-mode cluster \ --class org.apache.spark.examples.SparkPi \ local:///opt/spark/examples/spark-examples.jar \ 1000
可选:您可以在作业详情页面查看已创建的作业信息。
相关文档
通过kubectl管理Spark作业详情,请参见使用kubectl管理作业。
通过阿里云日志服务收集Spark作业的日志详情,请参见使用日志服务收集Spark作业日志。
在EMR on ACK中设置Spark集群的元数据详情,请参见为Spark集群设置元数据。
使用ECI弹性调度Spark作业详情,请参见使用ECI弹性调度Spark作业。