本文介绍在基于Intel® TDX安全特性的g8i实例中,使用BigDL PPML解决方案运行分布式的全链路安全的Spark大数据分析应用。
背景信息
随着企业将数据和计算资源迁移上云,保护大数据分析和AI应用的数据安全和隐私成为关键挑战。
基于BigDL PPML解决方案,在阿里云TDX实例中运行标准的人工智能和大数据处理应用(例如Apache Spark、Apache Flink、TensorFlow、PyTorch等),可以保证数据传输的安全性、数据使用的安全性、应用程序的完整性。更多信息,请参见BigDL-PPML。
Intel® Trusted Domain Extension(Intel® TDX)以硬件安全保障信息安全,不依赖固件和宿主机的安全状态,为您提供物理级的加密计算环境。
阿里云g8i实例基于Intel® TDX技术(下文简称为TDX实例),提供了TDX加密计算能力,打造了基于硬件级别的更高安全等级的可信机密环境,保障应用和数据的机密性与完整性不受恶意软件的破坏。
BigDL PPML(BigDL Privacy Preserving Machine Learning)基于Intel® TDX技术构建了一整套解决方案,能够让您进行非常安全的数据分析和AI应用。
技术架构
基于BigDL PPML,您可以在加密数据环境中,运行现有的分布式大数据分析和AI应用程序(例如Apache Spark、Apache Flink、TensorFlow、PyTorch、OpenVINO等),无需修改任何代码。大数据分析和AI应用程序运行在基于阿里云TDX实例的Kubernetes集群上,其计算和内存受Intel® TDX保护。在底层,BigDL PPML自动为分布式应用程序启用端到端安全机制,包括TDX保护:
在基于TDX实例的Kubernetes集群上提供和证明可信集群环境。
通过KMS进行密钥管理,用于分布式数据加密、解密。
安全的分布式计算和通信。

如上图所示,BigDL PPML方案基于Intel® TDX的阿里云TDX实例,部署Kubernetes集群环境。从数据流角度来看,所有数据均以加密方式存储在数据湖和数据仓库中。
BigDL PPML Worker节点加载机密数据,通过远程证明以及密钥管理系统获取数据密钥,在阿里云TDX实例中进行解密。
使用大数据和人工智能的计算框架,对数据进行分布式预处理、模型训练以及模型推理等。
将最终结果、数据或者模型,以加密方式写回到分布式存储中。
另外在各节点之间的数据均被加密传输(AES加密、TLS等),从而做到全链路的隐私保护和数据安全。
操作步骤
本文以运行Spark大数据分析为例,介绍如何基于阿里云TDX实例,运行分布式的端到端安全的大数据分析应用(本文以运行Simple Query用例为例)。更多大数据AI应用使用说明,请参见BigDL PPML Tutorials & Examples。
步骤一:部署Kubernetes集群及运行环境
本文中Kubernetes集群使用1个Master节点和2个Worker节点。总节点数量须与购买实例数量一致。您可以根据实际业务,选择节点数量。
创建具备Intel® TDX安全特性的g8i实例。
具体操作,请参见自定义购买实例。您需要注意以下参数:
实例规格:运行Simple Query用例的最小实例规格为32 vCPU 64 GiB,本文使用ecs.g8i.8xlarge
镜像:Alibaba Cloud Linux 3.2104 LTS 64位
公网IP:分配公网IPv4地址
购买实例数量:3
远程连接ECS实例。
具体操作,请参见ECS远程连接方式概述。
部署Kubernetes集群并进行安全配置。
在已创建的g8i实例中,部署Kubernetes集群。
具体操作,请参见Creating a cluster with kubeadm。
执行如下命令,在Kubernetes集群的Master节点上进行安全配置(RBAC配置)。
kubectl create serviceaccount spark kubectl create clusterrolebinding spark-role --clusterrole=edit --serviceaccount=default:spark --namespace=default
创建PersistentVolume。
以root用户,执行如下命令,创建pv-volume.yaml。
vim pv-volume.yaml按
i键进入编辑模式。在pv-volume.yaml中添加如下内容。
apiVersion: v1 kind: PersistentVolume metadata: name: task-pv-volume labels: type: local spec: storageClassName: manual capacity: storage: 10Gi accessModes: - ReadWriteOnce hostPath: path: "/mnt/data"按
Esc键,输入:wq,保存并退出编辑模式。分别执行如下命令,创建并查看已创建的PersistentVolume。
kubectl apply -f pv-volume.yaml kubectl get pv task-pv-volume
创建PersistentVolumeClaim。
以root用户,执行如下命令,创建pv-claim.yaml。
vim pv-claim.yaml按
i键进入编辑模式。在pv-claim.yaml中添加如下内容。
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: task-pv-claim spec: storageClassName: manual accessModes: - ReadWriteOnce resources: requests: storage: 3Gi按
Esc键,输入:wq,保存并退出编辑模式。分别执行如下命令,创建并查看已创建的PersistentVolumeClaim。
kubectl apply -f pv-claim.yaml kubectl get pvc task-pv-claim
步骤二:加密训练数据
在Kubernetes集群的每个节点上,执行如下命令,获取BigDL PPML镜像。
该镜像用于运行标准的Spark应用,提供数据加密、解密等功能。
docker pull intelanalytics/bigdl-ppml-trusted-bigdata-gramine-reference-16g:2.3.0-SNAPSHOT生成训练数据people.csv。
在Kubernetes集群的Master节点上,下载训练数据脚本generate_people_csv.py。
wget https://github.com/intel-analytics/BigDL/raw/main/ppml/scripts/generate_people_csv.py执行如下命令,生成训练数据people.csv。
python generate_people_csv.py </save/path/of/people.csv> <num_lines>说明</save/path/of/people.csv>请修改为实际的people.csv路径,如/home/user。
<num_lines>请修改为训练数据people.csv的行数,如500。
执行如下命令,将训练数据people.csv移到指定目录。
sudo scp /home/user/people.csv /mnt/data/simplekms/重要/home/user请替换成实际的用户目录。/mnt/data/simplekms/仅为示例,本文中/mnt/data/simplekms/用于存放加密、解密数据,后文中出现/mnt/data/simplekms/时不再单独说明。
在Master节点上,执行如下命令,运行bigdl-ppml-client容器。
该容器用来加密、解密训练数据。
说明/home/user/kuberconfig:/root/.kube/config请根据实际运行程序的用户进行修改,例如:使用root时:
/root/kuberconfig:/root/.kube/config使用普通用户(如test)时:
/home/test/kuberconfig:/root/.kube/config
export K8S_MASTER=k8s://$(kubectl cluster-info | grep 'https.*6443' -o -m 1) echo The k8s master is $K8S_MASTER . export SPARK_IMAGE=intelanalytics/bigdl-ppml-trusted-bigdata-gramine-reference-16g:2.3.0-SNAPSHOT sudo docker run -itd --net=host \ -v /etc/kubernetes:/etc/kubernetes \ -v /home/user/kuberconfig:/root/.kube/config \ -v /mnt/data:/mnt/data \ -e RUNTIME_SPARK_MASTER=$K8S_MASTER \ -e RUNTIME_K8S_SPARK_IMAGE=$SPARK_IMAGE \ -e RUNTIME_PERSISTENT_VOLUME_CLAIM=task-pv-claim \ --name bigdl-ppml-client \ $SPARK_IMAGE bash docker exec -it bigdl-ppml-client bash在Master节点上,加密训练数据people.csv。
执行如下命令,使用APPID、APIKEY生成primarykey。
您可以使用simple kms自行生成1~12位长度的APPID、APIKEY。本示例中,APPID为98463816****,APIKEY为15780936****,--primaryKeyPath指定primarykey存储的位置。
java -cp '/ppml/spark-3.1.3/conf/:/ppml/spark-3.1.3/jars/*:/ppml/bigdl-2.3.0-SNAPSHOT/jars/*' \ com.intel.analytics.bigdl.ppml.examples.GeneratePrimaryKey \ --primaryKeyPath /mnt/data/simplekms/primaryKey \ --kmsType SimpleKeyManagementService \ --simpleAPPID 98463816**** \ --simpleAPIKEY 15780936****创建加密脚本encrypt.py。
执行如下命令,切换到
/mnt/data/simplekms目录下。cd /mnt/data/simplekms执行如下命令,创建并打开encrypt.py文件。
sudo vim encrypt.py按
i进入编辑模式。在encrypt.py文件中,添加如下内容。
# encrypt.py from bigdl.ppml.ppml_context import * args = {"kms_type": "SimpleKeyManagementService", "app_id": "98463816****", "api_key": "15780936****", "primary_key_material": "/mnt/data/simplekms/primaryKey" } sc = PPMLContext("PPMLTest", args) csv_plain_path = "/mnt/data/simplekms/people.csv" csv_plain_df = sc.read(CryptoMode.PLAIN_TEXT) \ .option("header", "true") \ .csv(csv_plain_path) csv_plain_df.show() output_path = "/mnt/data/simplekms/encrypted-input" sc.write(csv_plain_df, CryptoMode.AES_CBC_PKCS5PADDING) \ .mode('overwrite') \ .option("header", True) \ .csv(output_path)按
Esc键,输入:wq,保存并退出编辑模式。
在bigdl-ppml-client容器中,执行如下命令,使用APPID、APIKEY、primarykey加密people.csv。
加密后的数据储存在
/mnt/data/simplekms/encrypted-output下。java \ -cp '/ppml/spark-3.1.3/conf/:/ppml/spark-3.1.3/jars/*:/ppml/bigdl-2.3.0-SNAPSHOT/jars/*' \ -Xmx1g org.apache.spark.deploy.SparkSubmit \ --master 'local[4]' \ --conf spark.network.timeout=10000000 \ --conf spark.executor.heartbeatInterval=10000000 \ --conf spark.python.use.daemon=false \ --conf spark.python.worker.reuse=false \ --py-files /ppml/bigdl-2.3.0-SNAPSHOT/python/bigdl-ppml-spark_3.1.3-2.3.0-SNAPSHOT-python-api.zip,/ppml/bigdl-2.3.0-SNAPSHOT/python/bigdl-spark_3.1.3-2.3.0-SNAPSHOT-python-api.zip,/ppml/bigdl-2.3.0-SNAPSHOT/python/bigdl-dllib-spark_3.1.3-2.3.0-SNAPSHOT-python-api.zip \ /mnt/data/simplekms/encrypt.py
在每个Worker节点,分别执行如下命令,复制Master节点的
/mnt/data/simplekms到每个Worker节点上。cd /mnt/data sudo scp -r user@192.168.XXX.XXX:/mnt/data/simplekms .说明user请替换成实际的Master节点用户名,192.168.XXX.XXX请修改为实际的Master节点IP。
步骤三:运行基于BigDL PPML的大数据分析用例
在bigdl-ppml-client容器中,向Kubernetes集群提交Spark任务,运行Simple Query用例。
说明spark.driver.host=192.168.XXX.XXX请修改为实际的Master节点IP地址。
${SPARK_HOME}/bin/spark-submit \ --master $RUNTIME_SPARK_MASTER \ --deploy-mode client \ --name spark-simplequery-tdx \ --conf spark.driver.memory=4g \ --conf spark.executor.cores=4 \ --conf spark.executor.memory=4g \ --conf spark.executor.instances=2 \ --conf spark.driver.host=192.168.XXX.XXX \ --conf spark.kubernetes.authenticate.driver.serviceAccountName=spark \ --conf spark.cores.max=8 \ --conf spark.kubernetes.container.image=$RUNTIME_K8S_SPARK_IMAGE \ --class com.intel.analytics.bigdl.ppml.examples.SimpleQuerySparkExample \ --conf spark.network.timeout=10000000 \ --conf spark.executor.heartbeatInterval=10000000 \ --conf spark.kubernetes.executor.deleteOnTermination=false \ --conf spark.driver.extraClassPath=local://${BIGDL_HOME}/jars/* \ --conf spark.executor.extraClassPath=local://${BIGDL_HOME}/jars/* \ --conf spark.kubernetes.file.upload.path=/mnt/data \ --conf spark.kubernetes.driver.volumes.persistentVolumeClaim.${RUNTIME_PERSISTENT_VOLUME_CLAIM}.options.claimName=${RUNTIME_PERSISTENT_VOLUME_CLAIM} \ --conf spark.kubernetes.driver.volumes.persistentVolumeClaim.${RUNTIME_PERSISTENT_VOLUME_CLAIM}.mount.path=/mnt/data \ --conf spark.kubernetes.executor.volumes.persistentVolumeClaim.${RUNTIME_PERSISTENT_VOLUME_CLAIM}.options.claimName=${RUNTIME_PERSISTENT_VOLUME_CLAIM} \ --conf spark.kubernetes.executor.volumes.persistentVolumeClaim.${RUNTIME_PERSISTENT_VOLUME_CLAIM}.mount.path=/mnt/data \ --jars local:///ppml/bigdl-2.3.0-SNAPSHOT/jars/bigdl-ppml-spark_3.1.3-2.3.0-SNAPSHOT.jar \ local:///ppml/bigdl-2.3.0-SNAPSHOT/jars/bigdl-ppml-spark_3.1.3-2.3.0-SNAPSHOT.jar \ --inputPartitionNum 8 \ --outputPartitionNum 8 \ --inputEncryptModeValue AES/CBC/PKCS5Padding \ --outputEncryptModeValue AES/CBC/PKCS5Padding \ --inputPath /mnt/data/simplekms/encrypted-input \ --outputPath /mnt/data/simplekms/encrypted-output \ --primaryKeyPath /mnt/data/simplekms/primaryKey \ --kmsType SimpleKeyManagementService \ --simpleAPPID 98463816**** \ --simpleAPIKEY 15780936****在Master节点上,监控任务运行状态。
执行如下命令,查看driver和executor名称和运行状态。
kubectl get pod当运行状态由
Running变成Completed时,说明Spark任务已运行完成。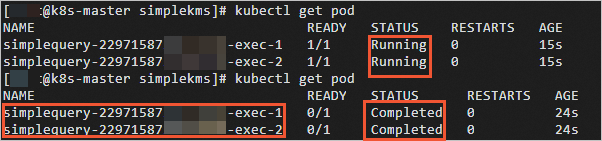
执行如下命令,查看pod日志。
kubectl logs simplequery-xxx-exec-1说明simplequery-xxx-exec-1请替换为上一步查询到的simplequery名。
当pod日志中限制
Finished时,说明Spark任务已运行完成。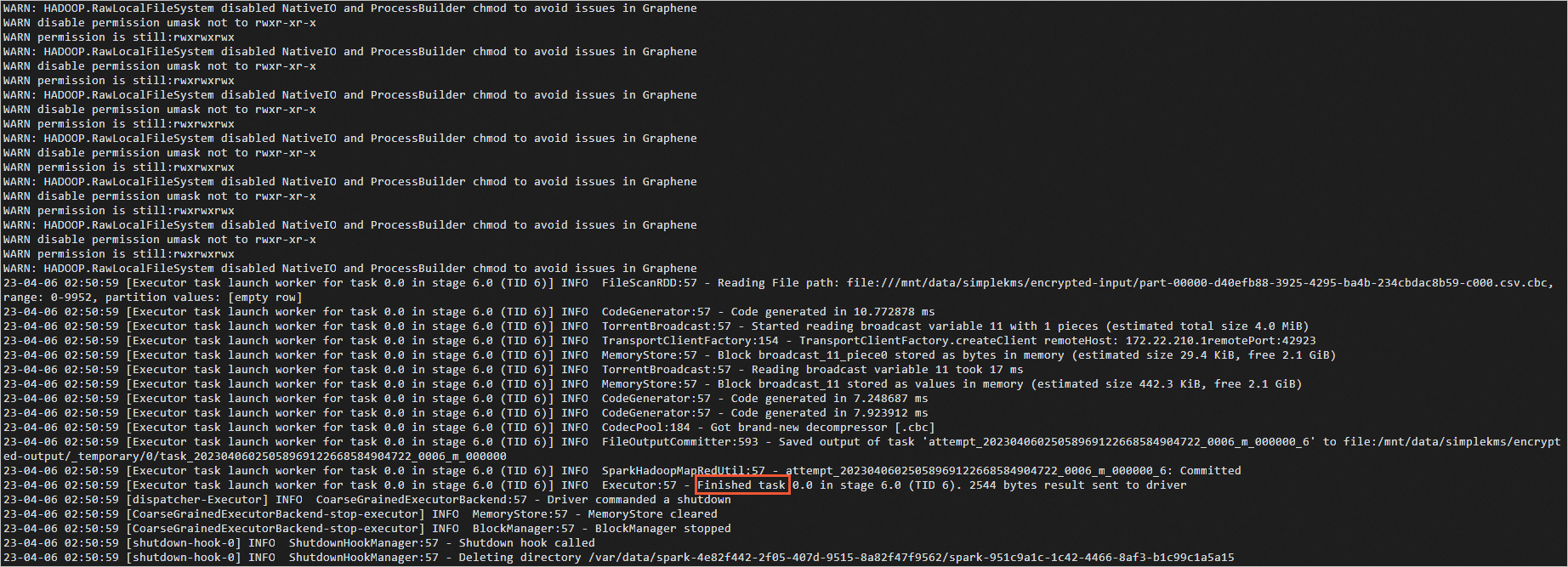
步骤四:解密结果
将各个Worker节点上的encrypted-output目录下的
.meta和part-XXXX.csv.cbc文件上传到Master节点encrypted-output目录中。上传完成后,Master节点上的encrypted-output数据如下所示。

在Master节点上的
/mnt/data/simplekms目录下,创建decrypt.py文件。执行如下命令,切换到
/mnt/data/simplekms目录。cd /mnt/data/simplekms执行如下命令,创建并打开decrypt.py文件。
sudo vim decrypt.py按
i进入编辑模式。在decrypt.py文件中,添加如下内容。
from bigdl.ppml.ppml_context import * args = {"kms_type": "SimpleKeyManagementService", "app_id": "98463816****", "api_key": "15780936****", "primary_key_material": "/mnt/data/simplekms/primaryKey" } sc = PPMLContext("PPMLTest", args) encrypted_csv_path = "/mnt/data/simplekms/encrypted-output" csv_plain_df = sc.read(CryptoMode.AES_CBC_PKCS5PADDING) \ .option("header", "true") \ .csv(encrypted_csv_path) csv_plain_df.show() output_path = "/mnt/data/simplekms/decrypted-output" sc.write(csv_plain_df, CryptoMode.PLAIN_TEXT) \ .mode('overwrite') \ .option("header", True)\ .csv(output_path)按
Esc键,输入:wq,保存并退出编辑模式。
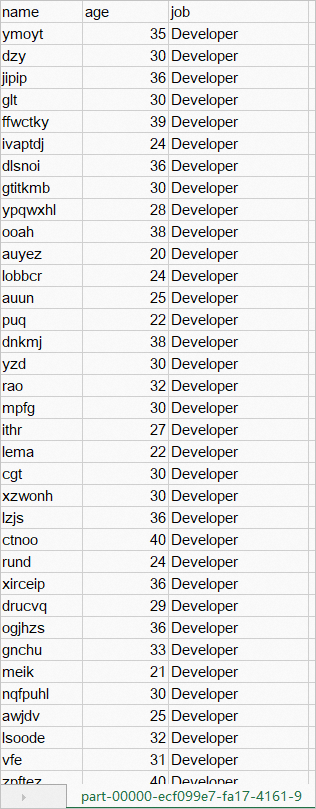
在Master节点上,执行如下命令,解密
encrypted_csv_path目录下的数据。使用APPID、APIKEY、primarykey进行解密,解密后的数据
part-XXXX.csv储存在/mnt/data/simplekms/decrypted-output目录下。java \ -cp '/ppml/spark-3.1.3/conf/:/ppml/spark-3.1.3/jars/*:/ppml/bigdl-2.3.0-SNAPSHOT/jars/*' \ -Xmx1g org.apache.spark.deploy.SparkSubmit \ --master 'local[4]' \ --conf spark.network.timeout=10000000 \ --conf spark.executor.heartbeatInterval=10000000 \ --conf spark.python.use.daemon=false \ --conf spark.python.worker.reuse=false \ --py-files /ppml/bigdl-2.3.0-SNAPSHOT/python/bigdl-ppml-spark_3.1.3-2.3.0-SNAPSHOT-python-api.zip,/ppml/bigdl-2.3.0-SNAPSHOT/python/bigdl-spark_3.1.3-2.3.0-SNAPSHOT-python-api.zip,/ppml/bigdl-2.3.0-SNAPSHOT/python/bigdl-dllib-spark_3.1.3-2.3.0-SNAPSHOT-python-api.zip \ /mnt/data/simplekms/decrypt.py在Windows系统中查看该解密后数据,显示如下: