本文介绍如何使用数据传输服务DTS(Data Transmission Service),将PolarDB-X 2.0的数据同步至MaxCompute。
前提条件
已开通MaxCompute并创建MaxCompute项目。更多信息,请参见开通MaxCompute和DataWorks和创建MaxCompute项目。
已设置MaxCompute白名单,允许DTS访问MaxCompute。更多信息,请参见设置阿里云产品访问MaxCompute白名单。
已使用阿里云账号(主账号),创建并记录AccessKey信息。
注意事项
DTS不会将源数据库中的外键同步到目标数据库,因此源数据库的级联、删除等操作不会同步到目标数据库。
类型 | 说明 |
源库限制 |
|
其他限制 |
|
其他注意事项 | DTS会在源库定时更新`dts_health_check`.`ha_health_check`表以推进binlog位点。 |
费用说明
| 同步类型 | 链路配置费用 |
| 库表结构同步和全量数据同步 | 不收费。 |
| 增量数据同步 | 收费,详情请参见计费概述。 |
支持同步的SQL操作
操作类型 | SQL操作语句 |
DML | INSERT、UPDATE、DELETE |
DDL | ALTER TABLE、ADD COLUMN 说明 不支持同步包含属性的加列操作。 |
操作步骤
进入目标地域的同步任务列表页面(二选一)。
通过DTS控制台进入
登录数据传输服务DTS控制台。
在左侧导航栏,单击数据同步。
在页面左上角,选择同步实例所属地域。
通过DMS控制台进入
说明实际操作可能会因DMS的模式和布局不同,而有所差异。更多信息,请参见极简模式控制台和自定义DMS界面布局与样式。
登录DMS数据管理服务。
在顶部菜单栏中,选择。
在同步任务右侧,选择同步实例所属地域。
单击创建任务,进入任务配置页面。
配置源库及目标库信息。
类别
配置
说明
无
任务名称
DTS会自动生成一个任务名称,建议配置具有业务意义的名称(无唯一性要求),便于后续识别。
源库信息
选择已有连接信息
若您需要使用已录入系统(新建或保存)的数据库实例,请在下拉列表中选择所需的数据库实例,下方的数据库信息将自动进行配置。
说明DMS控制台的配置项为选择DMS数据库实例。
若您未将数据库实例录入到系统,或无需使用已录入系统的数据库实例,则需要手动配置下方的数据库信息。
数据库类型
选择PolarDB-X 2.0。
接入方式
选择云实例。
实例地区
选择PolarDB-X 2.0实例所属地域。
是否跨阿里云账号
本示例为同一阿里云账号间的同步,选择不跨账号。
实例ID
选择源PolarDB-X 2.0实例ID。
数据库账号
填入PolarDB-X 2.0的数据库账号,需具备REPLICATION SLAVE、REPLICATION CLIENT及待同步对象的SELECT权限。
说明授权方式,请参见数据同步过程中的账号权限问题。
数据库密码
填入该数据库账号对应的密码。
目标库信息
选择已有连接信息
若您需要使用已录入系统(新建或保存)的数据库实例,请在下拉列表中选择所需的数据库实例,下方的数据库信息将自动进行配置。
说明DMS控制台的配置项为选择DMS数据库实例。
若您未将数据库实例录入到系统,或无需使用已录入系统的数据库实例,则需要手动配置下方的数据库信息。
数据库类型
选择MaxCompute。
接入方式
选择云实例。
实例地区
选择目标MaxCompute实例所属地域。
Project
填入目标MaxCompute项目的名称。
主账号AccessKeyId
填入前提条件备的一组AccessKey信息。
主账号AccessKeySecret
配置完成后,在页面下方单击测试连接以进行下一步。
说明请确保DTS服务的IP地址段能够被自动或手动添加至源库和目标库的安全设置中,以允许DTS服务器的访问。更多信息,请参见添加DTS服务器IP地址白名单。
若源库或目标库为自建数据库(接入方式不是云实例),则还需要在弹出的DTS服务器访问授权对话框单击测试连接。
单击确定,完成ODPS账号授权。
配置任务对象。
在对象配置页面,配置待同步的对象。
配置
说明
同步类型
固定选中增量同步。默认情况下,您还需要同时选中库表结构同步和全量同步。预检查完成后,DTS会将源实例中待同步对象的全量数据在目标集群中初始化,作为后续增量同步数据的基线数据。
目标已存在表的处理模式
预检查并报错拦截:检查目标数据库中是否有同名的表。如果目标数据库中没有同名的表,则通过该检查项目;如果目标数据库中有同名的表,则在预检查阶段提示错误,数据同步任务不会被启动。
说明如果目标库中同名的表不方便删除或重命名,您可以更改该表在目标库中的名称,请参见库表列名映射。
忽略报错并继续执行:跳过目标数据库中是否有同名表的检查项。
警告选择为忽略报错并继续执行,可能导致数据不一致,给业务带来风险,例如:
表结构一致的情况下,如在目标库遇到与源库主键或唯一键的值相同的记录:
全量期间,DTS会保留目标集群中的该条记录,即源库中的该条记录不会同步至目标数据库中。
增量期间,DTS不会保留目标集群中的该条记录,即源库中的该条记录会覆盖至目标数据库中。
表结构不一致的情况下,可能会导致无法初始化数据、只能同步部分列的数据或同步失败,请谨慎操作。
附加列规则
DTS在将数据同步到MaxCompute时,会在同步的目标表中添加一些附加列。如果附加列和目标表中已有的列出现名称冲突将会导致数据同步失败。您需要根据业务需求选择新规则或旧规则。
警告在选择附加列规则前,您需要评估附加列和目标表中已有的列是否会出现名称冲突,否则可能会导致数据丢失或任务失败。关于附加列的规则和定义说明,请参见附加列名称和定义说明。
增量日志表分区定义
根据业务需求,选择分区名称。关于分区的相关介绍请参见分区。
目标库对象名称大小写策略
您可以配置目标实例中同步对象的库名、表名和列名的英文大小写策略。默认情况下选择DTS默认策略,您也可以选择与源库、目标库默认策略保持一致。更多信息,请参见目标库对象名称大小写策略。
源库对象
在源库对象框中单击待同步对象,然后单击
 将其移动至已选择对象框。说明
将其移动至已选择对象框。说明同步对象选择的粒度为表。
已选择对象
如需更改单个同步对象在目标实例中的名称,请右击已选择对象中的同步对象,设置方式,请参见库表列名单个映射。
如需批量更改同步对象在目标实例中的名称,请单击已选择对象方框右上方的批量编辑,设置方式,请参见库表列名批量映射。
说明如需按库或表级别选择同步的SQL操作,请在已选择对象中右击待同步对象,并在弹出的对话框中选择所需同步的SQL操作。
如需设置WHERE条件过滤数据,请在已选择对象中右击待同步的表,在弹出的对话框中设置过滤条件。设置方法请参见通过SQL条件过滤任务数据。
单击下一步高级配置,进行高级参数配置。
配置
说明
选择调度该任务的专属集群
DTS默认将任务调度到共享集群上,您无需选择。若您希望任务更加稳定,可以购买专属集群来运行DTS同步任务。更多信息,请参见什么是DTS专属集群。
源库、目标库无法连接后的重试时间
在同步任务启动后,若源库或目标库连接失败则DTS会报错,并会立即进行持续的重试连接,默认持续重试时间为720分钟,您也可以在取值范围(10~1440分钟)内自定义重试时间,建议设置30分钟以上。如果DTS在设置的重试时间内重新连接上源库、目标库,同步任务将自动恢复。否则,同步任务将会失败。
说明针对同源或者同目标的多个DTS实例,如DTS实例A和DTS实例B,设置网络重试时间时A设置30分钟,B设置60分钟,则重试时间以低的30分钟为准。
由于连接重试期间,DTS将收取任务运行费用,建议您根据业务需要自定义重试时间,或者在源和目标库实例释放后尽快释放DTS实例。
源库、目标库出现其他问题后的重试时间
在同步任务启动后,若源库或目标库出现非连接性的其他问题(如DDL或DML执行异常),则DTS会报错并会立即进行持续的重试操作,默认持续重试时间为10分钟,您也可以在取值范围(1~1440分钟)内自定义重试时间,建议设置10分钟以上。如果DTS在设置的重试时间内相关操作执行成功,同步任务将自动恢复。否则,同步任务将会失败。
重要源库、目标库出现其他问题后的重试时间的值需要小于源库、目标库无法连接后的重试时间的值。
是否限制全量同步速率
在全量同步阶段,DTS将占用源库和目标库一定的读写资源,可能会导致数据库的负载上升。您可以根据实际情况,选择是否对全量同步任务进行限速设置(设置每秒查询源库的速率QPS、每秒全量迁移的行数RPS和每秒全量迁移的数据量(MB)BPS),以缓解目标库的压力。
说明仅当同步类型选择了全量同步,才有此配置项。
您也可以在同步实例运行后,调整全量同步的速率。
是否限制增量同步速率
您也可以根据实际情况,选择是否对增量同步任务进行限速设置(设置每秒增量同步的行数RPS和每秒增量同步的数据量(MB)BPS),以缓解目标库的压力。
是否去除正反向任务的心跳表 SQL
根据业务需求选择是否在DTS实例运行时,在源库中写入心跳SQL信息。
是:不在源库中写入心跳SQL信息,DTS实例可能会显示有延迟。
否:在源库中写入心跳SQL信息,可能会影响源库的物理备份和克隆等功能。
环境标签
您可以根据实际情况,选择用于标识实例的环境标签。本示例无需选择。
配置ETL功能
选择是否配置ETL功能。关于ETL的更多信息,请参见什么是ETL。
是:配置ETL功能,并在文本框中填写数据处理语句,详情请参见在DTS迁移或同步任务中配置ETL。
否:不配置ETL功能。
监控告警
是否设置告警,当同步失败或延迟超过阈值后,将通知告警联系人。
不设置:不设置告警。
设置:设置告警,您还需要设置告警阈值和告警通知。更多信息,请参见在配置任务过程中配置监控告警。
保存任务并进行预检查。
若您需要查看调用API接口配置该实例时的参数信息,请将鼠标光标移动至下一步保存任务并预检查按钮上,然后单击气泡中的预览OpenAPI参数。
若您无需查看或已完成查看API参数,请单击页面下方的下一步保存任务并预检查。
说明在同步作业正式启动之前,会先进行预检查。只有预检查通过后,才能成功启动同步作业。
如果预检查失败,请单击失败检查项后的查看详情,并根据提示修复后重新进行预检查。
如果预检查产生警告:
对于不可以忽略的检查项,请单击失败检查项后的查看详情,并根据提示修复后重新进行预检查。
对于可以忽略无需修复的检查项,您可以依次单击点击确认告警详情、确认屏蔽、确定、重新进行预检查,跳过告警检查项重新进行预检查。如果选择屏蔽告警检查项,可能会导致数据不一致等问题,给业务带来风险。
购买实例。
预检查通过率显示为100%时,单击下一步购买。
在购买页面,选择数据同步实例的计费方式、链路规格,详细说明请参见下表。
类别
参数
说明
信息配置
计费方式
预付费(包年包月):在新建实例时支付费用。适合长期需求,价格比按量付费更实惠,且购买时长越长,折扣越多。
后付费(按量付费):按小时扣费。适合短期需求,用完可立即释放实例,节省费用。
资源组配置
实例所属的资源组,默认为default resource group。更多信息,请参见什么是资源管理。
链路规格
DTS为您提供了不同性能的同步规格,同步链路规格的不同会影响同步速率,您可以根据业务场景进行选择。更多信息,请参见数据同步链路规格说明。
订购时长
在预付费模式下,选择包年包月实例的时长和数量,包月可选择1~9个月,包年可选择1年、2年、3年和5年。
说明该选项仅在付费类型为预付费时出现。
配置完成后,阅读并勾选《数据传输(按量付费)服务条款》。
单击购买并启动,并在弹出的确认对话框,单击确定。
您可在数据同步界面查看具体任务进度。
增量日志表结构定义说明
你需要在MaxCompute中执行set odps.sql.allow.fullscan=true;,设置项目空间属性,允许进行全表扫描。
DTS在将MySQL产生的增量数据同步至MaxCompute的增量日志表时,除了存储增量数据,还会存储一些元信息,示例如下。

示例中的modifytime_year、modifytime_month、modifytime_day、modifytime_hour、modifytime_minute为分区字段,是在配置任务对象步骤中指定的。
结构定义说明
字段 | 说明 |
record_id | 增量日志的记录ID,为该日志唯一标识。 说明
|
operation_flag | 操作类型,取值:
|
utc_timestamp | 操作时间戳,即binlog的时间戳(UTC 时间)。 |
before_flag | 所有列的值是否为更新前的值,取值:Y或N。 |
after_flag | 所有列的值是否为更新后的值,取值:Y或N。 |
关于before_flag和after_flag的补充说明
对于不同的操作类型,增量日志中的before_flag和after_flag定义如下:
INSERT
当操作类型为INSERT时,所有列的值为新插入的记录值,即为更新后的值,所以before_flag取值为N,after_flag取值为Y,示例如下。

UPDATE
当操作类型为UPDATE时,DTS会将UPDATE操作拆为两条增量日志。这两条增量日志的record_id、operation_flag及utc_timestamp对应的值相同。
第一条增量日志记录了更新前的值,所以before_flag取值为Y,after_flag取值为N。第二条增量日志记录了更新后的值,所以before_flag取值为N,after_flag取值为Y,示例如下。

DELETE
当操作类型为DELETE时,增量日志中所有的列值为被删除的值,即列值不变,所以before_flag取值为Y,after_flag取值为N,示例如下。

全量数据合并示例
执行数据同步的操作后,DTS会在MaxCompute中分别创建该表的全量基线表和增量日志表。您可以通过MaxCompute的SQL命令,对这两个表执行合并操作,得到某个时间点的全量数据。
本案例以customer表为例(表结构如下),介绍操作流程。

根据源库中待同步表的结构,在MaxCompute中创建用于存储合并结果的表。
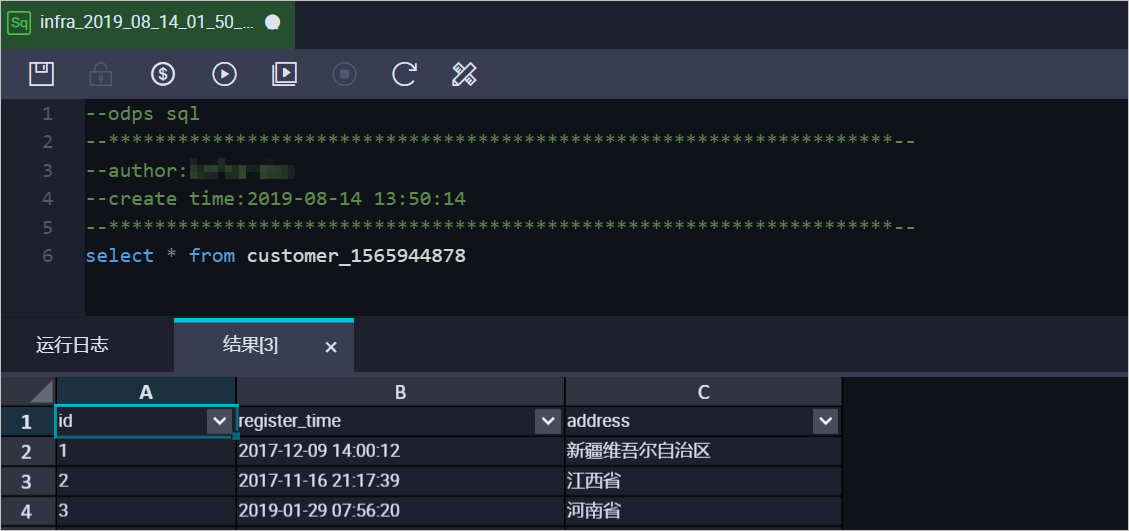
例如,需要获取customer表在
1565944878时间点的全量数据。为方便业务识别,创建如下数据表:CREATE TABLE `customer_1565944878` ( `id` bigint NULL, `register_time` datetime NULL, `address` string);说明您可以在MaxCompute的临时查询中,运行SQL命令。
关于MaxCompute支持的数据类型与相关说明,请参见数据类型。
在MaxCompute中执行如下SQL命令,合并全量基线表和增量日志表,获取该表在某一时间点的全量数据。
set odps.sql.allow.fullscan=true; insert overwrite table <result_storage_table> select <col1>, <col2>, <colN> from( select row_number() over(partition by t.<primary_key_column> order by record_id desc, after_flag desc) as row_number, record_id, operation_flag, after_flag, <col1>, <col2>, <colN> from( select incr.record_id, incr.operation_flag, incr.after_flag, incr.<col1>, incr.<col2>,incr.<colN> from <table_log> incr where utc_timestamp< <timestamp> union all select 0 as record_id, 'I' as operation_flag, 'Y' as after_flag, base.<col1>, base.<col2>,base.<colN> from <table_base> base) t) gt where row_number=1 and after_flag='Y'说明<result_storage_table>:存储全量merge结果集的表名。
<col1>/<col2>/<colN>:同步表中的列名。
<primary_key_column>:同步表中的主键列名。
<table_log>:增量日志表名。
<table_base>:全量基线表名。
<timestamp>:需要获取全量数据的时间点。
合并数据表,获取customer表在
1565944878时间点的全量数据,示例如下:set odps.sql.allow.fullscan=true; insert overwrite table customer_1565944878 select id, register_time, address from( select row_number() over(partition by t.id order by record_id desc, after_flag desc) as row_number, record_id, operation_flag, after_flag, id, register_time, address from( select incr.record_id, incr.operation_flag, incr.after_flag, incr.id, incr.register_time, incr.address from customer_log incr where utc_timestamp< 1565944878 union all select 0 as record_id, 'I' as operation_flag, 'Y' as after_flag, base.id, base.register_time, base.address from customer_base base) t) gt where gt.row_number= 1 and gt.after_flag= 'Y';上述命令执行完成后,可在customer_1565944878表中查询合并后的数据。