MaxCompute Graph是一套面向迭代的图计算处理框架。图计算作业使用图进行建模,图由点(Vertex)和边(Edge)组成,点和边包含权值(Value)。您可以使用MaxCompute Graph提供的接口Java SDK编写图计算程序。
MaxCompute Graph支持以下图编辑操作:
修改点或边的权值。
增加、删除点。
增加、删除边。
编辑点和边时,需要您同时在代码中维护点与边的关系。
通过迭代对图进行编辑、演化,最终求解出结果。典型应用有PageRank、单源最短距离算法、K-均值聚类算法 等。您可以使用MaxCompute Graph提供的接口Java SDK编写图计算程序。
基本概念
图(Graph):是用于表示对象之间关联关系的一种抽象数据结构。使用顶点(Vertex)和边(Edge)进行描述,顶点表示对象,边表示对象之间的关系。可以抽象为用图描述的数据即为图数据。
点(Vertex):在图模型中用于表示对象。
边(Edge):在图模型中用于表示对象之间的关系。由源ID、目标ID和与该边缘关联的数据组成的单个定向边缘。
有向图:即边有方向性的图模型,一条边的两个顶点一般为不同的角色,例如页面A连接向页面B。有向图中的边分为出边和入边。
无向图:即边无方向性的图模型,例如用户组中的普通用户。
出边:指从当前顶点指向其它顶点的边。
入边:其它顶点指向当前顶点的边。
度:度表示一个顶点的所有边的数量。
出度:是一个顶点出边的数量。
入度:是一个顶点入边的数量。
超步(SuperStep):图进行迭代计算时,一次迭代称为一个超步。
Graph数据结构
MaxCompute Graph能够处理的图必须是一个由点(Vertex)和边(Edge)组成的有向图。由于MaxCompute仅提供二维表的存储结构,因此需要您自行将图数据分解为二维表存储在MaxCompute中。您可以根据自身的业务场景进行分解。
在进行图计算分析时,使用自定义的GraphLoader将二维表数据转换为MaxCompute Graph引擎中的点和边。
点的结构为<ID, Value, Halted, Edges>,参数分别表示:
点标识符(ID)
权值(Value)
状态(Halted, 表示是否要停止迭代。)
出边集合(Edges,以该点为起始点的所有边列表。)
边的结构为<DestVertexID,Value>,参数分别为:
目标点(DestVertexID)
权值(Value)
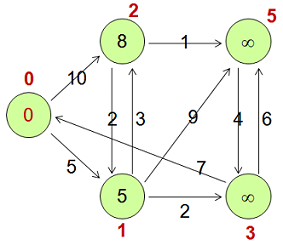 例如,上图可以表述为以下二维表格式。
例如,上图可以表述为以下二维表格式。
Vertex | <ID, Value, Halted, Edges> |
v0 | <0, 0, false, [<1, 5 >, <2, 10 >]> |
v1 | <1, 5, false, [<2, 3>, <3, 2>, <5, 9>]> |
v2 | <2, 8, false, [<1, 2>, <5, 1 >]> |
v3 | <3, Long.MAX_VALUE, false, [<0, 7>, <5, 6>]> |
v5 | <5, Long.MAX_VALUE, false, [<3, 4 >]> |
Graph程序逻辑
Graph程序主要包含图加载、迭代计算、迭代终止等处理步骤。
图加载。
图加载包含两个步骤:
图加载:框架调用您自定义的GraphLoader,将输入表的记录解析为点或边。
分布式化:框架调用您自定义的Partitioner对点进行分片(默认的分片逻辑是,根据点ID的哈希值对Worker个数取模分片),分配到相应的Worker。
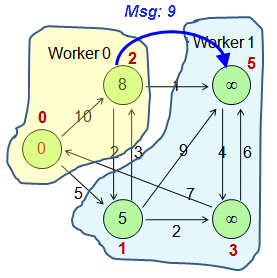 例如,假设上图中Worker数是2,则v0、v2会被分配到Worker0,因为ID对2取模结果为0。而v1、v3、v5将被分配到Worker1,ID对2取模结果为1。
例如,假设上图中Worker数是2,则v0、v2会被分配到Worker0,因为ID对2取模结果为0。而v1、v3、v5将被分配到Worker1,ID对2取模结果为1。迭代计算 。
一次迭代为一个超步(SuperStep),遍历所有非结束状态(Halted值为False)的点或者收到消息的点(处于结束状态的点收到信息会被自动唤醒),并调用其
compute(ComputeContext context, Iterable messages)方法。在您实现的
compute(ComputeContext context, Iterable messages)方法中:处理上一个超步发给当前点的消息(Messages)。
根据需要对图进行编辑:
修改点、边的取值。
发送消息给某些点。
增加、删除点或边。
通过Aggregator汇总信息到全局信息,详情请参见Aggregator机制。
设置当前点状态,结束或非结束状态。
迭代进行过程中,框架会将消息以异步的方式发送到对应Worker,并在下一个超步进行处理,无需人工干预。
迭代终止 。
满足以下任意一条,迭代即终止:
所有点处于结束状态(Halted值为True)且没有新消息产生。
达到最大迭代次数。
某个Aggregator的
terminate方法返回True。
Graph程序的伪代码描述如下所示。
// 1. load for each record in input_table { GraphLoader.load(); } // 2. setup WorkerComputer.setup(); for each aggr in aggregators { aggr.createStartupValue(); } for each v in vertices { v.setup(); } // 3. superstep for (step = 0; step < max; step ++) { for each aggr in aggregators { aggr.createInitialValue(); } for each v in vertices { v.compute(); } } // 4. cleanup for each v in vertices { v.cleanup(); } WorkerComputer.cleanup();