数据湖构建(DLF)可以结合阿里云实时计算Flink版(Flink VVP),以及Flink CDC相关技术,实现灵活定制化的数据入湖。并利用DLF统一元数据管理、权限管理等能力,实现数据湖多引擎分析、数据湖管理等功能。本文为您介绍Flink+DLF数据湖方案具体步骤。
背景信息
阿里云实时计算Flink版是一套基于Apache Flink构建的实时大数据分析平台,支持多种数据源和结果表类型。Flink任务可以利用数据湖统一存储的优势,使用Hudi结果表或Iceberg结果表,将作业的结果输出到数据湖中,实现数据湖分析。在写入数据湖的过程中,Flink可以通过设置DLF Catalog,将表的元数据同步到数据湖构建(DLF)中。依托数据湖构建产品(DLF)提供的企业级统一元数据能力,Flink+DLF方案可以实现写入的数据湖表无缝对接阿里云上的计算引擎,如EMR、MaxCompute、Hologres等。也可以通过DLF提供的丰富的数据湖管理能力,实现数据湖生命周期管理和湖格式的优化。

前提条件
已开通阿里云实时计算Flink版,创建Flink全托管工作空间。
已开通阿里云数据湖构建(DLF)服务。如果您没有开通,则可以在DLF产品首页,单击开通。
本文以MySQL数据源为例,需要创建RDS MySQL,详情请参见创建RDS MySQL实例。如果使用其他数据源入湖可忽略。
创建的RDS MySQL需要和实时计算Flink版在同一个地域同一个VPC内,RDS MySQL须为5.7及以上版本。
操作流程
步骤一:准备MySQL数据
登录准备好的MySQL实例,详情请参见通过DMS登录RDS MySQL。
执行如下命令,创建一张表,并插入若干测试数据。
CREATE DATABASE testdb; CREATE TABLE testdb.student ( `id` bigint(20) NOT NULL, `name` varchar(256) DEFAULT NULL, `age` bigint(20) DEFAULT NULL, PRIMARY KEY (`id`) ); INSERT INTO testdb.student VALUES (1,'name1',10); INSERT INTO testdb.student VALUES (2,'name2',20);
步骤二:Flink创建DLF Catalog
登录实时计算管理控制台。
进入创建Catalog页面。
在Flink全托管页签,单击目标工作空间操作列下的控制台。
在左侧导航栏,单击元数据管理。
单击创建Catalog。
创建DLF Catalog。
在创建Catalog页面,选择DLF,单击下一步。
填写以下参数配置信息,单击确定。详情请参见管理DLF Catalog。

当您成功创建DLF之后,可在元数据管理中看到新增的dlf数据目录,默认链接的是DLF的default数据目录。
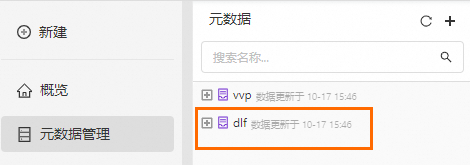
步骤三:创建Flink入湖作业
登录实时计算管理控制台。
在Flink全托管页签,单击目标工作空间操作列下的控制台。
创建数据源表和目标表。
在左侧导航栏,单击。
在SQL编辑区域,输入以下代码,单击运行。
-- 创建数据源表 CREATE TABLE IF NOT EXISTS student_source ( id INT, name VARCHAR (256), age INT, PRIMARY KEY (id) NOT ENFORCED ) WITH ( 'connector' = 'mysql-cdc', -- hostname替换为RDS的连接地址 'hostname' = 'rm-xxxxxxxx.mysql.rds.aliyuncs.com', 'port' = '3306', 'username' = '<RDS user name>', 'password' = '<RDS password>', 'database-name' = '<RDS database>', -- table-name为数据源表,本例中填步骤二创建的student表 'table-name' = 'student' ); -- catalog名为步骤二创建的dlf catalog name,本例中填dlf CREATE DATABASE IF NOT EXISTS dlf.dlf_testdb; -- 创建目标表 CREATE TABLE IF NOT EXISTS dlf.dlf_testdb.student_hudi ( id BIGINT PRIMARY KEY NOT ENFORCED, name STRING, age BIGINT ) WITH( 'connector' = 'hudi' );创建成功后,可在元数据管理中看到新增的数据源表和目标表。

创建Flink SQL入湖作业。
在左侧导航栏,单击。
单击新建后,在新建作业草稿对话框,选择空白的流作业草稿,单击下一步。
填写作业信息,单击创建。
在SQL编辑区域,输入以下代码,创建一个Flink SQL作业。
-- 创建流SQL作业 INSERT INTO dlf.dlf_testdb.student_hudi SELECT * FROM student_source /*+ OPTIONS('server-id'='123456') */;说明关于MySQL源表的参数设置和使用条件,请参见MySQL的CDC源表。
关于Hudi结果表的参数设置,请参见Hudi结果表。
在SQL编辑区域右上方,单击部署。在部署新版本对话框,可根据需要填写或选中相关内容,单击确定。
启动作业。
在左侧导航栏,单击。
单击目标作业名称操作列中的启动。
选择无状态启动后,单击启动。当您看到作业状态变为运行中,则代表作业运行正常。作业启动参数配置,详情请参见作业启动。
步骤四:使用DLF数据湖分析
在左侧导航栏,单击。
在SQL编辑区域,输入以下代码,单击运行。
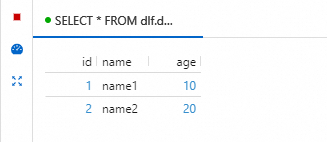
SELECT * FROM dlf.dlf_testdb.student_hudi;查询结果如下图所示,可以直接对Flink写入数据湖的数据进行查询和分析。
如果您购买了EMR集群,并且开启了数据湖DLF元数据,也可以直接通过EMR集群对Flink入湖结果进行数据湖分析,参考Hudi与Spark SQL集成。
相关资料
如果您想要通过EMR DataFlow集群的Flink读写DLF,请参考文章DataFlow集群通过DLF读写Hudi表。