DataWorks的数据集成为您提供MongoDB Writer插件,可从其他数据源中读取数据,并将数据同步至MongoDB。本文以一个具体的示例,为您演示如何通过数据集成将MaxCompute的数据离线同步至MongoDB。
前提条件
本实践进行操作时,需满足以下条件。
已开通DataWorks并创建MaxCompute数据源。
本实践使用独享数据集成资源组进行离线任务运行,因此您需先购买并配置独享数据集成资源组。操作详情请参见新增和使用独享数据集成资源组。
说明您也可以使用新版资源组(通用型资源组),更多信息,请参见新增和使用新版通用型资源组。
准备示例数据表
本实践需准备一个MongoDB数据集合、一个MaxCompute表,用于后续进行离线数据同步。
准备MaxCompute表并构造表数据。
创建一个名称为
test_write_mongo的分区表,分区字段为pt。CREATE TABLE IF NOT EXISTS test_write_mongo( id STRING , col_string STRING, col_int int, col_bigint bigint, col_decimal decimal, col_date DATETIME, col_boolean boolean, col_array string ) PARTITIONED BY (pt STRING) LIFECYCLE 10;添加一个分区取值
20230215。insert into test_write_mongo partition (pt='20230215') values ('11','name11',1,111,1.22,cast('2023-02-15 15:01:01' as datetime),true,'1,2,3');检查分区表是否正确创建。
SELECT * FROM test_write_mongo WHERE pt='20230215';
准备MongoDB数据集合,后续将MaxCompute数据同步至此MongoDB数据集合。
本实践使用阿里云云数据库MongoDB作为示例,创建一个名称为
test_write_mongo的数据集合。db.createCollection('test_write_mongo')
离线任务配置
step1:添加MongoDB数据源
添加一个MongoDB数据源,保障数据源与独享数据集成资源组之间网络连通。操作详情请参见配置MongoDB数据源。
step2:创建离线同步节点,并配置离线同步任务
在DataWorks的DataStudio中创建一个离线同步节点,并配置离线同步的来源与去向等任务配置参数,核心配置要点如下,其他参数可保持默认值即可。详细操作请参见通过向导模式配置离线同步任务。
配置同步网络连接。
选择上述步骤中创建的MongoDB、MaxCompute数据源和对应的独享数据集成资源组,测试完成连通性。
配置任务:选择数据源。
选择上述准备数据步骤中准备的MaxCompute分区表和MongoDB数据集合。任务关键参数配置详细介绍如下。
参数
配置说明
写入模式(是否覆盖)
指定了传输数据时是否覆盖的信息,包括
写入模式和业务主键:写入模式:当设置为否时,每条写入数据执行插入。此选项为默认项。
当设置为是时,需指定
业务主键,表示针对相同的业务主键做覆盖操作。
业务主键:指定了每行记录的业务主键,用来做覆盖时使用(不支持配置为多个业务主键,通常指Mongo中的主键)。
说明当
写入模式设置为是,且将非 _id字段配置为业务主键,任务运行时可能会出现类似以下的报错:After applying the update, the (immutable) field '_id' was found to have been altered to _id: "2"原因是写入数据中,存在 _id与 replaceKey不匹配的数据,详情请参报错:After applying the update, the (immutable) field '_id' was found to have been altered to _id: "2"。导入前准备语句
即前置条件(PreSQL)的配置。配置格式为JSON格式,包含了
type和json两个属性。type:必填项,可取值为:remove、drop(注意为小写字母)。json:当
type为remove时,为必填项,配置语法为MongoDB的标准Query,详情请参见Query Documents。当
type为drop时,无需填写。
配置任务:字段映射。
数据源为MongoDB时,默认使用同行映射。您也可以单击
 图标手动编辑源表字段,手动编辑的示例如下。
图标手动编辑源表字段,手动编辑的示例如下。{"name":"id","type":"string"} {"name":"col_string","type":"string"} {"name":"col_int","type":"long"} {"name":"col_bigint","type":"long"} {"name":"col_decimal","type":"double"} {"name":"col_date","type":"date"} {"name":"col_boolean","type":"bool"} {"name":"col_array","type":"array","splitter":","}手动后,界面可展示来源字段与目标字段的映射关系。
step3:提交发布离线同步节点
如果您使用的是标准模式的DataWorks工作空间,并且希望后续在生产环境中周期性调度此离线同步任务的话,您可以将离线同步节点提交发布到生产环境。操作详情请参见发布任务。
step4:运行离线同步节点,查看同步结果
完成上述配置后,您可以运行同步节点,待运行完成后,查看同步至MongoDB数据集合中的数据。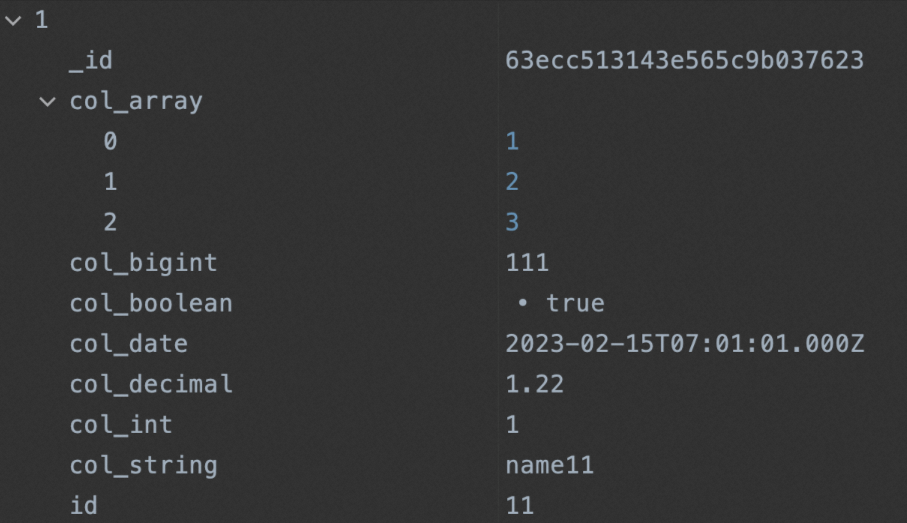
附录:同步过程中的数据格式转换说明
关于type取值
支持的type包括:INT、LONG、DOUBLE、STRING、BOOL、DATE、ARRAY。
关于数组类型
当配置类型为ARRAY时,需配置对应的splitter属性,可以输出到MongoDB的数组类型。如:
源端数据为字符串:
a,b,c。同步任务配置type为
ARRAY,splitter为,。同步任务执行后,写入MongoDB的数据为:
["a","b","c"]。