本文档旨在为您提供一套完整的故障排查与修复方案,帮助您快速定位并解决在使用DataWorks整库全增量同步任务功能时,Merge任务遇到的各类常见问题。
Merge任务说明
基本原理
整库全增量任务运行时会先将源表存量数据通过离线同步至Base表中(目标表),同时启动实时同步任务读取源库增量变更日志,写到增量日志表中(log表)。其后的数据处理逻辑:在T+1日的凌晨,启动Merge任务合并log表T日分区的增量数据和Base表T-1日分区中的全量数据,输出T日的全量分区数据。其过程如下图所示(以分区表为例):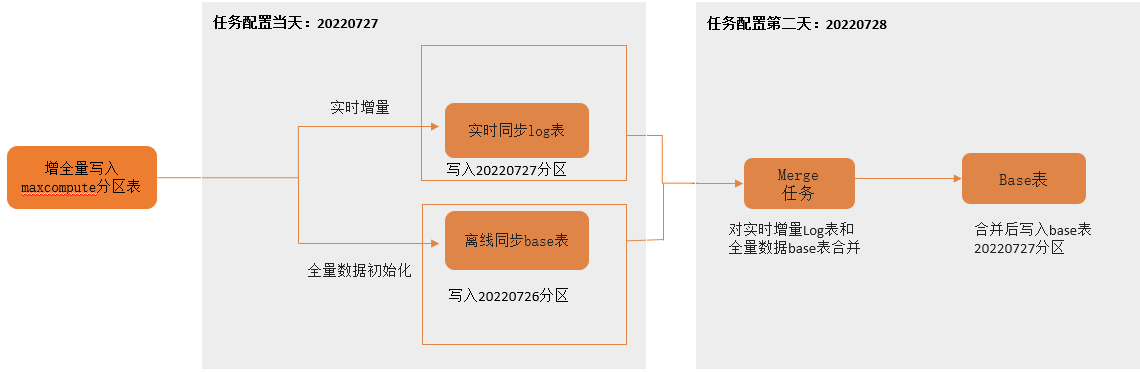
离线任务节点
整库全增量流程执行完成后,数据集成会在运维中心生成若干节点,在DataWorks可以看到节点,如图所示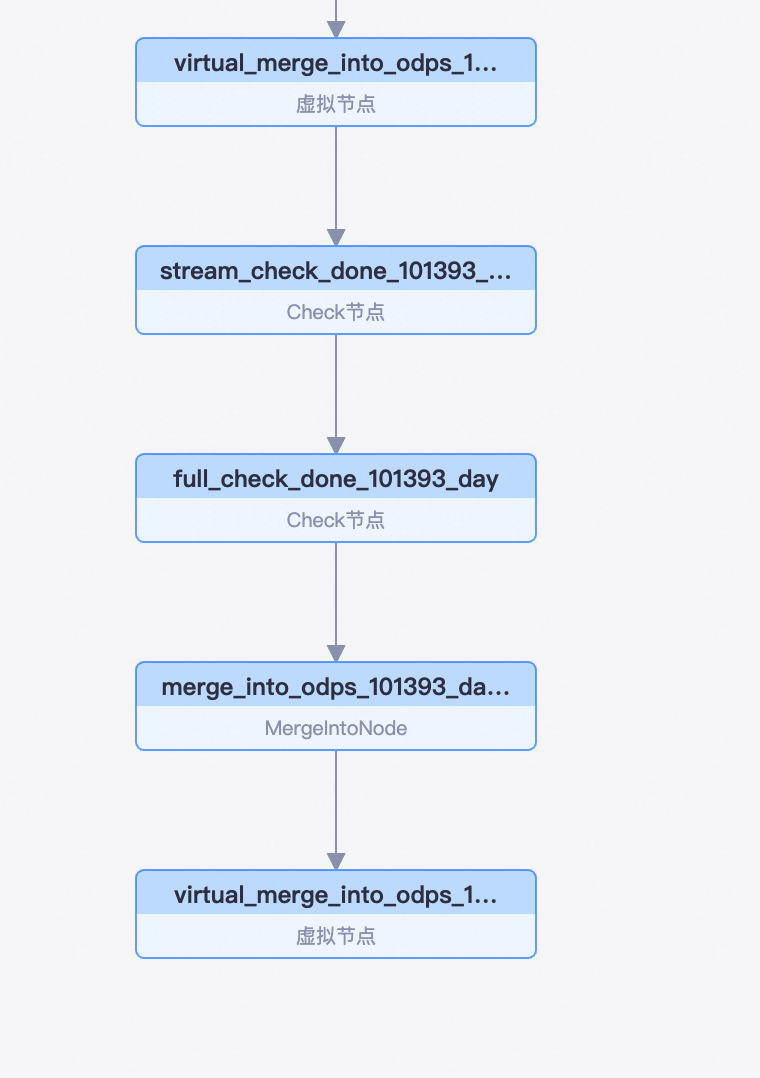
任务根虚拟节点:该任务的所有子任务都会产生在该节点之下
Check 节点(stream_check 开头):检查增量消费位点,确认前一天的增量分区数据是否已经同步完成,只有增量同步完成后才可以启动后续的Merge任务执行增量数据合并。
Check 节点(full_check 开头):检查全量同步是否完成,源表存量数据会在首次执行全增量同步任务或者加表时执行一次全量同步,同步至目标MaxCompute表。主要目的是确保任务首次运行或者新增表后,源表存量数据已经全部同步到目标表分区。
MergeIntoNode:执行增量log表数据与Base表全量数据的合并,输出新的全量(分区)数据。
下游虚拟节点:同步任务配置的表名,会在本节点的输出名中体现,在数据开发SQL任务写表名时,可以很方便地自动解析到该虚拟节点。
任务运行
在DataWorks可以看到各节点的调度依赖情况:
每日任务实例先后执行顺序为:Check 节点(stream_check 开头)、Check 节点(full_check 开头)、MergeIntoNode。
MergeIntoNode是一个自依赖调度节点,其每个周期的执行都依赖于前一个周期的成功完成。
这种自依赖机制是为保障数据的完整性而设计的。具体而言,T日的Merge任务负责加工并产出T-1日的最终数据分区。因此,如果T日的任务运行失败,T-1日的数据分区便无法生成,系统将自动阻塞T+1日的任务实例,从而避免因数据链条中断而引发的计算错误。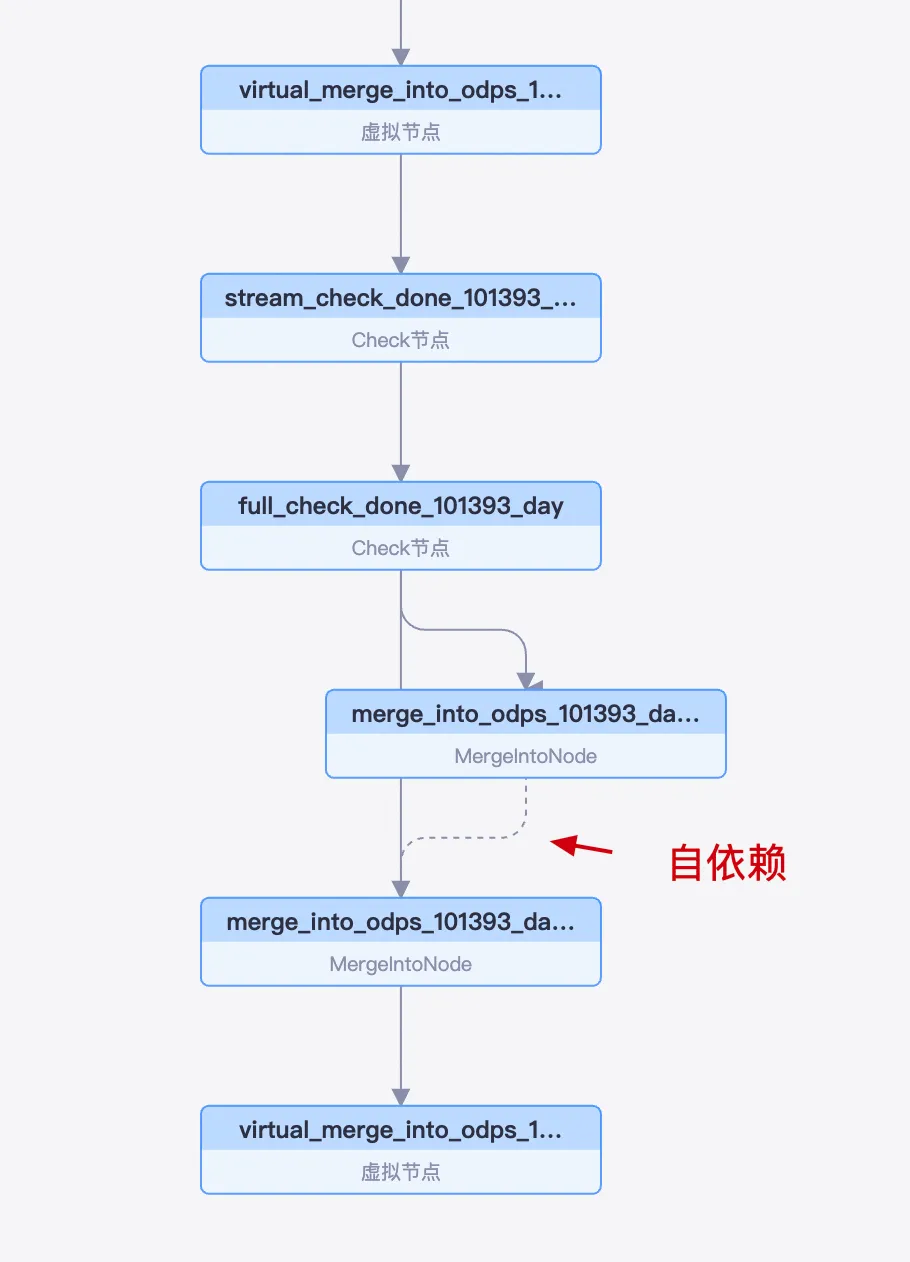
Merge任务运行
Merge任务执行时,会对每张同步表生成一个SQL子任务,读取log表中该表的增量数据,合并该表前一日分区的全量数据,输出截至前一日全量分区数据。
Merge任务的SQL子任务内部以并发方式执行,子任务如果有执行失败,符合条件的会内部执行自动重试,如果最终有子任务执行失败,则Merge节点执行失败。
常见Merge问题排查
Merge任务运行失败
Base table partition not exists.原因:前一日的全量分区没有产生,一般较少出现,可能场景:
手动补数据运行Merge实例,但前一日的Merge实例没有运行。需确保前一日Merge实例正常运行完成。
首次运行时离线全量或者加表后全量同步未执行完成,如果存在同步失败的表,解决方案中通过先减表再加表的方式重新初始化该表。
如果是其他原因,可能是触发了不支持的场景,请联系值班同学进一步排查。
Run job failed,instance:XXXX.原因:有MaxCompute SQL子任务运行失败,搜索instanceId,定位到错误日志,通常日志类似如下:
Instance: XXX, Status: FAILED result: MaxCompute-0110061: Failed to run ddltask - Persist ddl plans failed. , Logview: http://Logview.MaxCompute.aliyun.com/Logview/?h=http://service.ap-southeast-1.maxcompute.aliyun-inc.com/api&p=sgods&i=20220807101011355goyu43wa&token=NFBwc2tzaEpJNGF0OVFINmJuREZrem1OamQ4PSxPRFBTX09CTzo1OTMwMzI1NTY1MTk1MzAzLDE2NjAxMjYyMTEseyJTdGF0ZW1lbnQiOlt7IkFjdGlvbiI6WyJvZHBzOlJlYWQiXSwiRWZmZWN0IjoiQWxsb3ciLCJSZXNvdXJjZSI6WyJhY3M6b2RwczoqOnByb2plY3RzL3Nnb2RzL2luc3RhbmNlcy8yMDIyMDgwNzEwMTAxMTM1NWdveXU0M3dhIl19XSwiVmVyc2lvbiI6IjEifQ== ]出现MaxCompute-XXXX这种错误提示,通常是代表MaxCompute内部执行错误,您可查看SQL错误码(MaxCompute-01CCCCX)文档查询报错以及解决办法,若文档中找不到或有其他问题,可以咨询MaxCompute技术支持人员。
Request rejected by flow control. You have exceeded the limit for the number of tasks you can run concurrently in this project. Please try later.原因:Merge并发提交的SQL子任务过多,触发了MaxCompute对该Project并发限流。
解决方案:参见Merge任务导致MaxCompute资源被耗尽。
分区数据未产生
原因:本次实例运行失败或者未运行完成,请前往,检查Merge实例的执行情况:
实例状态为运行中,等待当日Merge实例执行完成。
实例状态为运行失败,查看Merge任务运行日志,分析失败原因,解决后右键该实例,进行重跑。
实例状态为未运行:
查看实例上游的stream_check节点是否执行完成,如果仍在执行,则需要查看实时任务是否有延迟,如有延迟先解决实时任务的延迟,延迟解决后,Merge任务会触发执行,查看日志内容,示例如下:
2023-01-06 00:15:04,692 INFO [DwcheckStreamXDoneNode.java:168] - 数据当前点位时间: 1672921729000 2023-01-06 00:15:04,692 WARN [DwcheckStreamXDoneNode.java:183] - 进行等待重试。 2023-01-06 00:20:04,873 INFO [DwcheckStreamXDoneNode.java:168] - 数据当前点位时间: 1672921729000 2023-01-06 00:20:04,873 WARN [DwcheckStreamXDoneNode.java:183] - 进行等待重试。上游依赖的前某次Merge实例未完成或者执行失败,运维中心查看该日Merge实例的上游Merge实例,找到最近一次未完成或运行失败Merge实例:
如果该Merge任务执行失败:查看运行日志分析失败原因,解决后右键重跑该实例,以触发正常调度。
如果该Merge任务实例处于未运行状态:检查其上游stream_check实例,确认是否完整,以及实时任务是否有延迟。
之前的流程存在问题,新建或者重跑了一键整库同步流程,但因为Merge节点实例存在自身依赖,导致新Merge实例无法运行。 找到一键流程重新运行后的第一个Merge实例,右键去除依赖解除对上游的Merge节点的依赖,新Merge实例即可触发运行。
Merge任务运行慢或运行长时间不结束
运维中心查看任务运行日志,可以看到当前运行中的SQL任务,日志如下:
2022-08-07 18:10:58,919 INFO [LogUtils.java:20] - Wait instance 20220807101058817gbb6ghx5 to finish...
2022-08-07 18:10:58,938 INFO [LogUtils.java:20] - Wait instance 20220807101058818g46v43wa to finish...在日志中根据instanceId搜索SQL任务的Logview(如instance20220807101058817gbb6ghx5:Logview Portal)可以打开Logview查看SQL任务的执行情况,SQL执行慢的可能性很多:
BASE数据量很大,启动的mapper和reducer过多,可以按项目级别调整相应MaxCompute参数解决。
启动的SQL任务过多,导致提交任务时资源不足,打开Logview,可以看到SQL实例处在Waiting状态,需要优化解决MaxCompute资源问题。如有需要可以联系MaxCompute值班同学支持。
如果未找到上述日志,可能存在提交MaxCompute SQL任务卡顿情况,可以找到最后的一个MaxCompute Logview,查看日志或者联系MaxCompute值班同学支持分析Logview。
Merge任务导致MaxCompute资源被耗尽
为控制资源消耗或优化任务性能,可按以下步骤调整Merge任务的并发数:
进入任务编辑界面,在右侧面板找到并展开高级配置。
在运行时配置中,定位合并任务并发度参数,根据实际需求修改参数值。
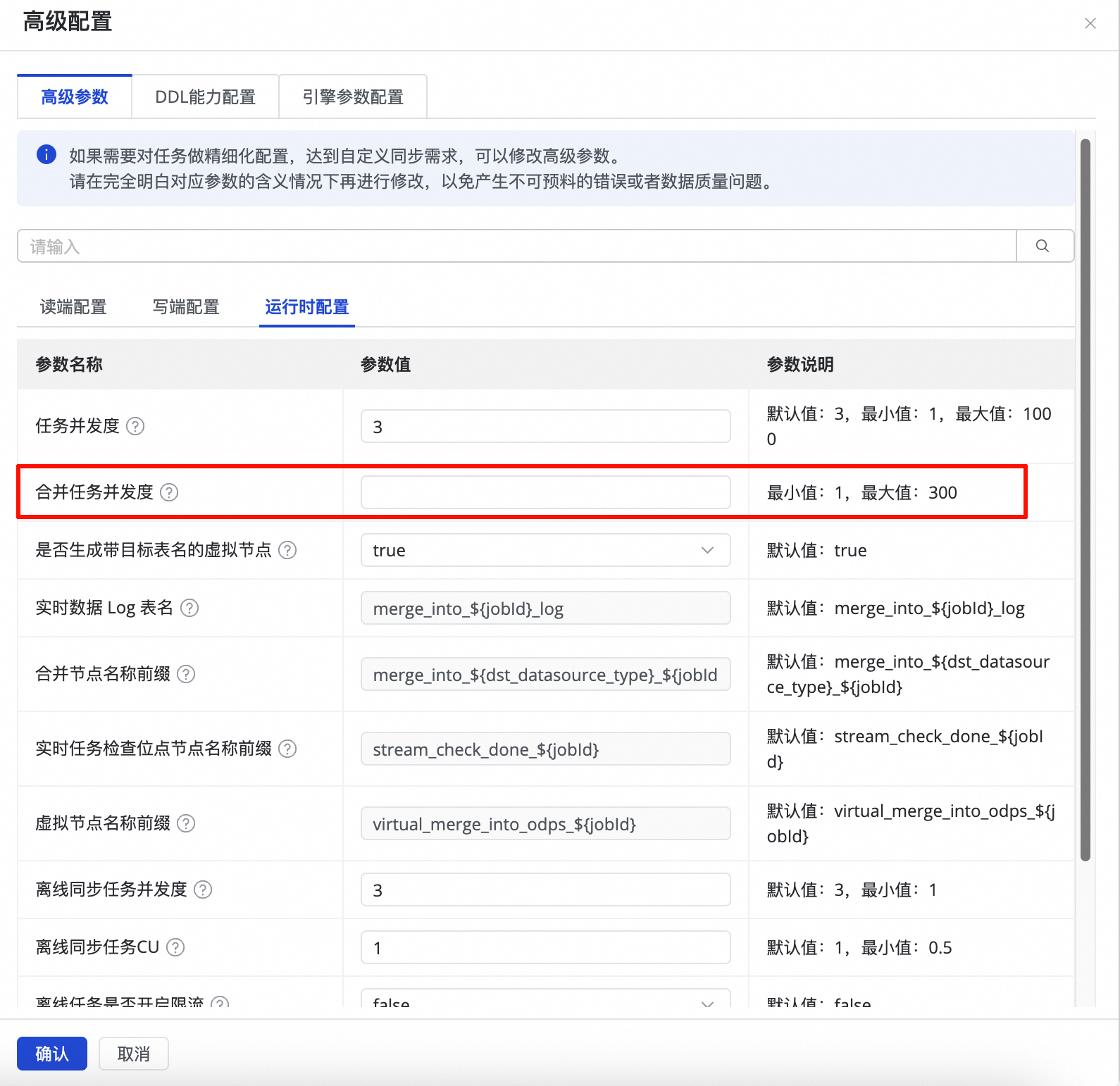
参数说明:
默认值:
300调整建议:当任务因资源不足而报错或为降低资源消耗时,可适当降低此值。
生效方式:配置修改后,需重启任务方可生效。
更改Merge任务调度运行时间设置,错峰运行Merge任务。