本文为您介绍实时同步任务延迟时的自助解决方案。
确认造成延迟问题在同步任务的读端还是写端
如果是在DataStudio创建的实时同步任务,您需要在界面单击运行中的任务名称,弹出任务运行详情对话框。详情请参见实时同步任务运行与管理。
在运行信息详情中,查看窗口等待时间(5 min),该指标表示最近5分钟窗口内,同步任务读取数据或写入数据的等待时间。用于帮助您判断数据同步延迟的瓶颈方,当数据同步发生延迟时,指标数据较大的一般为瓶颈方。
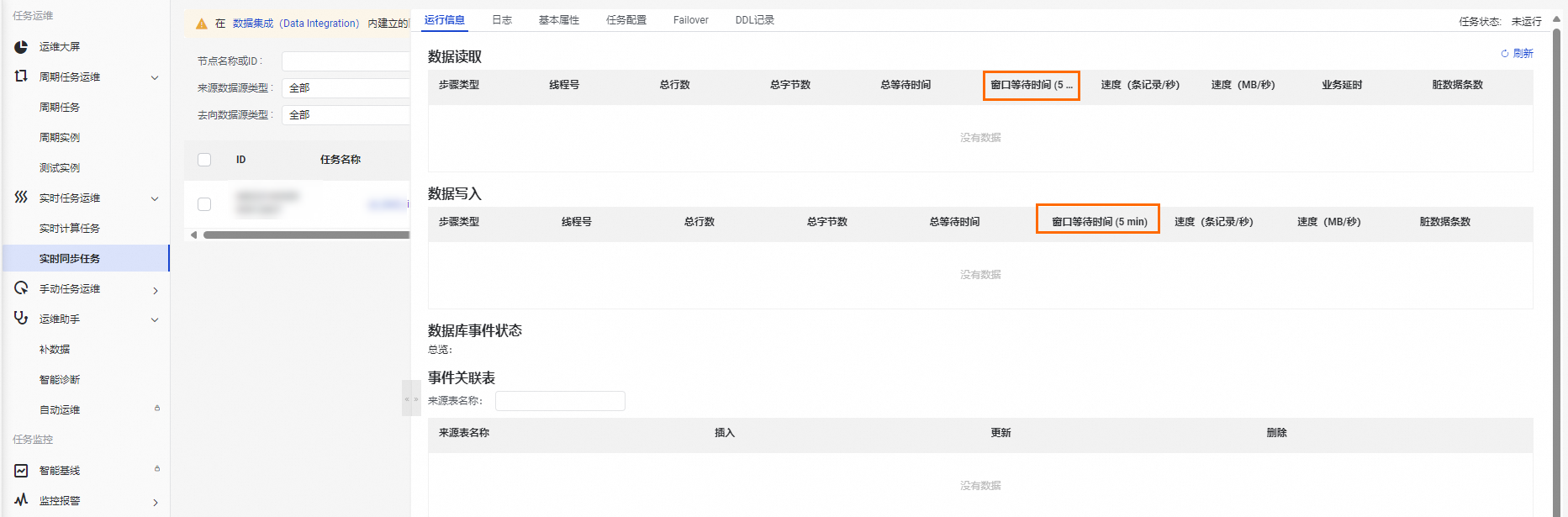
确认造成延迟问题的系统是否有异常
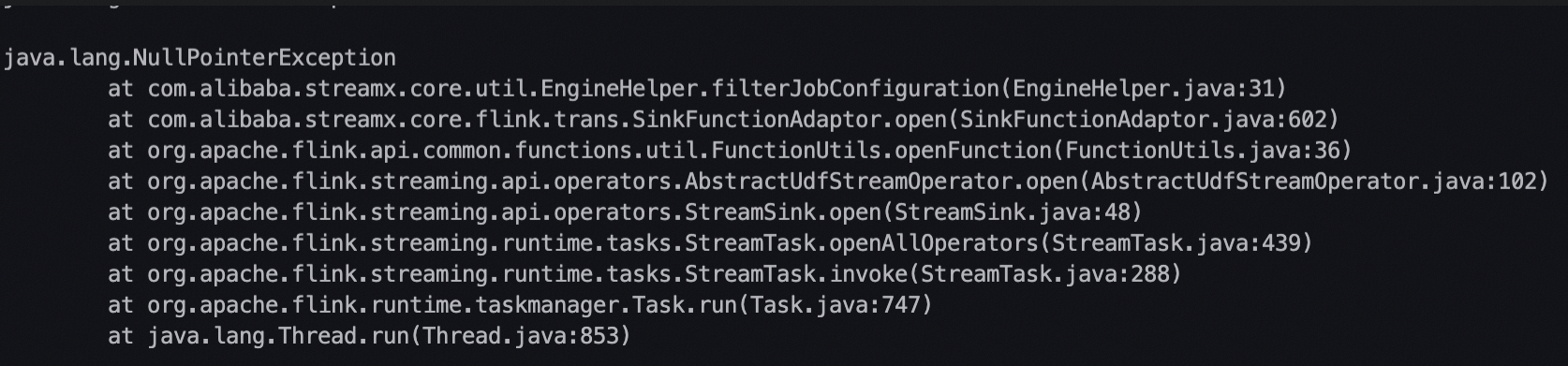
当确认了延迟瓶颈是在同步任务的读端还是写端后,可在上述任务运行详情中切换至日志页签,使用Error/error/Exception/exception/OutOfMemory等关键字搜索,查看在延迟时间段内是否有类似下图所示的相关异常栈,如果有,根据异常信息,参考常见异常处理办法,判断是否可以通过优化任务配置进行解决。
实时同步任务从一个系统读数据,并将数据写入另一个系统,当写数据比读数据慢时,则读数据一侧的系统会受到反压,导致速度变慢。即造成瓶颈的系统可能会由于反压导致另一侧系统的一些异常,此时要优先关注造成瓶颈的系统的异常情况。
确认实时同步任务是否有频繁OOM
您还可以在上述任务运行详情界面中切换到Failover页面,确认任务是否有频繁的Failover(10分钟内发生1一次以上Failover则表示频繁),如果有,可在Failover事件列查看导致Failover的异常信息,并单击查看详情链接查看Failover发生前的完整任务日志,如果在Failover事件列的异常信息或者任务运行日志中能够搜索到OutOfMemory关键字的异常信息,则说明实时同步任务内存设置不足,需要加大任务内存设置。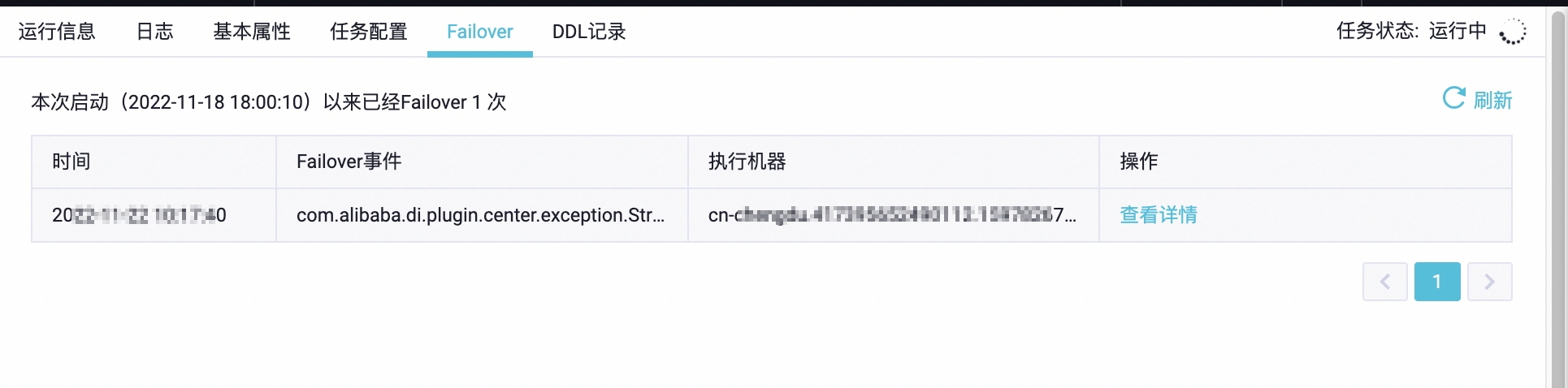
任务内存设置方法如下:
对于DataStudio新建的单表到单表ETL实时同步任务,您可以单击右侧的基本配置设置任务内存。

在DataStudio新建的数据库迁至DataHub等类型实时同步任务,您可以单击右侧的基本配置设置任务内存。
同步解决方案任务,您可以在运行资源设置步骤中设置内存。
确认源端数据是否有倾斜或者是否需要扩展分区或shard的数量
对于源端是Kafka、DataHub和Loghub三种类型的实时同步任务,如果根据上述步骤未发现异常或Failover,则需要检查源端系统数据是否有倾斜或者分区、shard的读取流量是否达到了同步速率的上限。
对于源端是Kafka、DataHub和Loghub三种类型的实时同步任务,每个分区或者shard只能由一个并发消费,如果存在写入源端系统的数据集中在个别分区或者shard,而其他分区或shard数据很少的情况,则很可能导致数据倾斜分区或shard的消费瓶颈,造成延迟。此时将无法通过数据集成任务设置解决延迟问题,需要从Kafka、DataHub和Loghub系统的上游数据生产侧解决数据写入倾斜问题后,延迟问题才能恢复。
您可以通过在上述任务运行详情中切换到运行信息页签,查看不同Reader线程总字节数统计,如果有个别Reader现场总字节数明显大于其他Reader线程,可以判断存在数据倾斜情况。但由于总字节数包括任务从上次指定位点启动开始的数据量,如果任务运行时间已经很长,则可能无法反映出最近的数据倾斜情况,您需要继续通过源端系统的监控指标确认是否存在数据倾斜情况。
如果写入源端系统的单个分区或者shard数据流量已经达到了同步速率的上限,例如,Kafka集群侧可以对分区读取流量配置限流、DataHub单分区的最大读取流量有4MB/s限制、Loghub单shard最大读取流量有10MB/s限制,如果实时同步任务对于单分区的读取速度超过了限制,则可通过扩展源端系统分区或shard数量来解决延迟。
如果有多个实时同步任务消费同一个Kafka Topic、DataHub Topic或者Loghub logstore的情况,您需要注意所有实时同步任务的读取速度之和是否超过限制。
确认MySQL源端是否有提交大事务或者变更过于频繁(如大量的DML和DDL的操作)
对于源端是MySQL的实时同步任务,如果根据上述步骤未发现异常或Failover,则需要检查源端系统是否提交了大事务或者源端系统变更过于频繁(如大量的DML和DDL的操作),导致Binlog增长过快超过同步任务消费速度导致延迟。
例如,更新全表某个字段的值或者删除大量数据等。您可以在任务运行详情中切换到运行信息页签,查看任务同步速度:
当同步速度很大时,说明Binlog增长速度快。
当同步速度不大,您可以在MySQL服务端查看Binlog的统计指标和审计日志确认实际增长速率。
但同步速度可能无法反映当前同步任务消费MySQL源端Binlog的实际速度,因为当事务或者变更涉及的库表没有包含在同步任务的配置中,同步任务会将这部分数据在读取过后过滤掉,也不计入对同步速度和数据量统计。
如果确认是大事务或者临时的大量变更导致了任务延迟,则可以等待大事务或者大量变更包含的变更数据被同步任务处理完成后,任务延迟会逐步被追上。
确认是否有写入动态分区频繁切换问题(uploader map size has reached uploaderMapMaximumSize)
对于写入MaxCompute的实时同步任务,当分区方式选择根据字段内容动态分区时,要特别注意选择对应于MaxCompute表分区列的源端列,在实时同步任务右侧基本配置中配置的Flush间隔内(默认为1分钟)包含的可枚举值个数不能太大。
由于在Flush间隔内待写入MaxCompute表的数据实际是在实时同步任务的一组队列中保存,每个队列会缓存一个MaxCompute的写入数据,队列的默认最大个数是5个,如果对应于MaxCompute表分区列的源端列在配置的Flush间隔内可枚举值个数超过了缓存队列的最大个数,会立即触发对所有写入数据的Flush操作,而频繁的Flush操作将严重影响写入性能。
您需要确认是否存在MaxCompute表分区缓存队列个数耗尽触发频繁Flush操作问题。您可以在实时同步任务的运行详情页切换到日志页签,在日志中搜索是否有uploader map size has reached uploaderMapMaximumSize。
增加并发设置或开启分布式运行模式解决延迟问题
如果根据上述步骤确认非读写异常引发的任务延迟,而是源端业务流量增长导致的延迟,则需要通过提高实时同步任务并发设置缓解延迟。
并发加大后也需要同步增加任务的内存设置,比例关系可以按照并发每增大4,内存增加1GB。
任务并发及内存设置方法如下:
对于DataStudio新建的单表到单表ETL实时同步任务,您可以单击右侧的基本配置设置任务并发和内存。
在DataStudio新建的数据库迁至DataHub等类型实时同步任务,您可以在运行资源设置步骤中设置并发,在右侧的基本配置设置任务内存。
同步解决方案任务,您可以在运行资源设置步骤中设置并发和内存。
在未开启分布式运行模式情况下,任务并发建议不超过32,如果超过20则会由于单机资源瓶颈导致任务延迟,此时特定通道可以通过开启分布式运行模式提升性能,目前支持开启分布式运行模式的通道如下:
任务类型 | 源端 | 目标端 |
DataStudio ETL任务 | Kafka | MaxCompute |
DataStudio ETL任务 | Kafka | Hologres |