Spark是一个通用的大数据分析引擎,具有高性能、易用和普遍性等特点,可用于进行复杂的内存分析,构建大型、低延迟的数据分析应用。DataWorks为您提供EMR Spark节点,便于您在DataWorks上进行Spark任务的开发和周期性调度。本文为您介绍如何创建EMR Spark节点,并通过详细的应用示例,为您介绍EMR Spark节点的功能。
前提条件
开始进行节点开发前,若您需要定制组件环境,此时即可基于官方镜像
dataworks_emr_base_task_pod创建自定义镜像,并在数据开发中使用镜像。例如:在创建自定义镜像时替换Spark Jar包或是依赖特定的
库、文件或jar包。已注册EMR集群至DataWorks。操作详情请参见旧版数据开发:绑定EMR计算资源。
(可选,RAM账号需要)进行任务开发的RAM账号已被添加至对应工作空间中,并具有开发或空间管理员(权限较大,谨慎添加)角色权限,添加成员的操作详情请参见为工作空间添加空间成员。
已购买资源组完成资源组配置。包括绑定工作空间、网络配置等。详情请参见使用Serverless资源组。
已创建业务流程。数据开发(DataStudio)基于业务流程对不同开发引擎进行具体开发操作,所以您创建节点前需要先新建业务流程,操作详情请参见创建业务流程。
如果您在开发任务时,需要特定的开发环境支持,可使用DataWorks提供的自定义镜像功能,定制化构建任务执行所需的组件镜像。更多信息,请参见自定义镜像。
使用限制
仅支持使用Serverless资源组(推荐)或独享调度资源组运行该类型任务,若在数据开发时需使用镜像,则必须使用Serverless资源组。
DataLake或自定义集群若要在DataWorks管理元数据,需先在集群侧配置EMR-HOOK。若未配置,则无法在DataWorks中实时展示元数据、生成审计日志、展示血缘关系、开展EMR相关治理任务。配置EMR-HOOK,详情请参见配置Spark SQL的EMR-HOOK。
EMR on ACK类型的Spark集群不支持查看血缘,EMR Serverless Spark集群支持查看血缘。
EMR on ACK 类型的Spark集群及EMR Serverless Spark集群仅支持通过OSS REF的方式直接引用OSS资源、上传资源到OSS,不支持上传资源到HDFS。
DataLake集群、自定义集群支持通过OSS REF的方式直接引用OSS资源、上传资源到OSS及上传资源到HDFS。
注意事项
若您已为当前工作空间绑定的EMR集群中的Spark开启Ranger权限控制。
使用默认镜像运行Spark任务时,该功能将默认可用。
如需使用自定义镜像运行Spark任务,请提交工单联系技术支持人员,对镜像进行升级以支持该功能。
准备工作:开发Spark任务并获取JAR包
在使用DataWorks调度EMR Spark任务前,您需要先在EMR中开发Spark任务代码并完成任务代码的编译,生成编译后的任务JAR包,EMR Spark任务的开发指导详情请参见Spark概述。
后续您需要将任务JAR包上传至DataWorks,在DataWorks中周期性调度EMR Spark任务。
一、创建EMR Spark节点
进入数据开发页面。
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的,在下拉框中选择对应工作空间后单击进入数据开发。
新建EMR Spark节点。
右键单击目标业务流程,选择。
说明您也可以鼠标悬停至新建,选择。
在新建节点对话框中,输入名称,并选择引擎实例、节点类型及路径。单击确认,进入EMR Spark节点编辑页面。
说明节点名称支持大小写字母、中文、数字、下划线(_)和小数点(.)。
二、开发Spark任务
在EMR Spark节点编辑页面双击已创建的节点,进入任务开发页面,您可以根据不同场景需求选择适合您的操作方案:
(推荐)先从本地上传资源至DataStudio,再引用资源。详情请参见方案一:先上传资源后引用EMR JAR资源。
使用OSS REF方式引用OSS资源,详情请参见方案二:直接引用OSS资源。
方案一:先上传资源后引用EMR JAR资源
DataWorks也支持您从本地先上传资源至DataStudio,再引用资源。EMR Spark任务编译完成后,您需获取编译后的JAR包,建议根据JAR包大小选择不同方式存储JAR包资源。
上传JAR包资源,创建为DataWorks的EMR资源并提交,或直接存储在EMR的HDFS存储中(EMR on ACK 类型的Spark集群及EMR Serverless Spark集群不支持上传资源到HDFS)。
JAR包小于500MB时
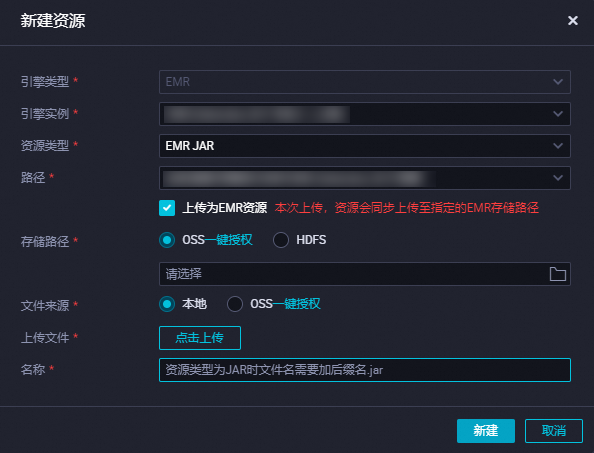
创建EMR JAR资源。
JAR包小于500MB时,可将JAR包通过本地上传的方式上传为DataWorks的EMR JAR资源,便于后续在DataWorks控制台进行可视化管理,创建完成资源后需进行提交,操作详情请参见创建和使用EMR资源。
 说明
说明首次创建EMR资源时,如果您希望JAR包上传后存储在OSS中,您需要先参考界面提示进行授权操作。
引用EMR JAR资源。
双击创建的EMR Spark节点,打开EMR Spark 节点的代码编辑页面。
在节点下,找到上述步骤中已上传的EMR JAR资源,右键选择引用资源。
选择引用资源后,当前打开的EMR Spark节点的编辑页面会自动添加资源引用代码,引用代码示例如下。
##@resource_reference{"spark-examples_2.12-1.0.0-SNAPSHOT-shaded.jar"} spark-examples_2.12-1.0.0-SNAPSHOT-shaded.jar如果成功自动添加上述引用代码,表明资源引用成功。其中,spark-examples_2.12-1.0.0-SNAPSHOT-shaded.jar为您实际上传的EMR JAR资源名称。
改写EMR Spark节点代码,补充spark submit命令,改写后的示例如下。
说明EMR Spark节点编辑代码时不支持注释语句,请务必参考如下示例改写任务代码,不要随意添加注释,否则后续运行节点时会报错。
##@resource_reference{"spark-examples_2.11-2.4.0.jar"} spark-submit --class org.apache.spark.examples.SparkPi --master yarn spark-examples_2.11-2.4.0.jar 100其中:
org.apache.spark.examples.SparkPi:为您实际编译的JAR包中的任务主Class。
spark-examples_2.11-2.4.0.jar:为您实际上传的EMR JAR资源名称。
其他参数可参考以上示例不做修改,您也可执行以下命令查看
spark submit的使用帮助,根据需要修改spark submit命令。说明若您需要在Spark节点中使用
spark submit命令简化的参数,您需要在代码中自行添加,例如,--executor-memory 2G。Spark节点仅支持使用YARN的Cluster模式提交作业。
spark submit方式提交的任务,deploy-mode推荐使用cluster模式,不建议使用client模式。
spark-submit --help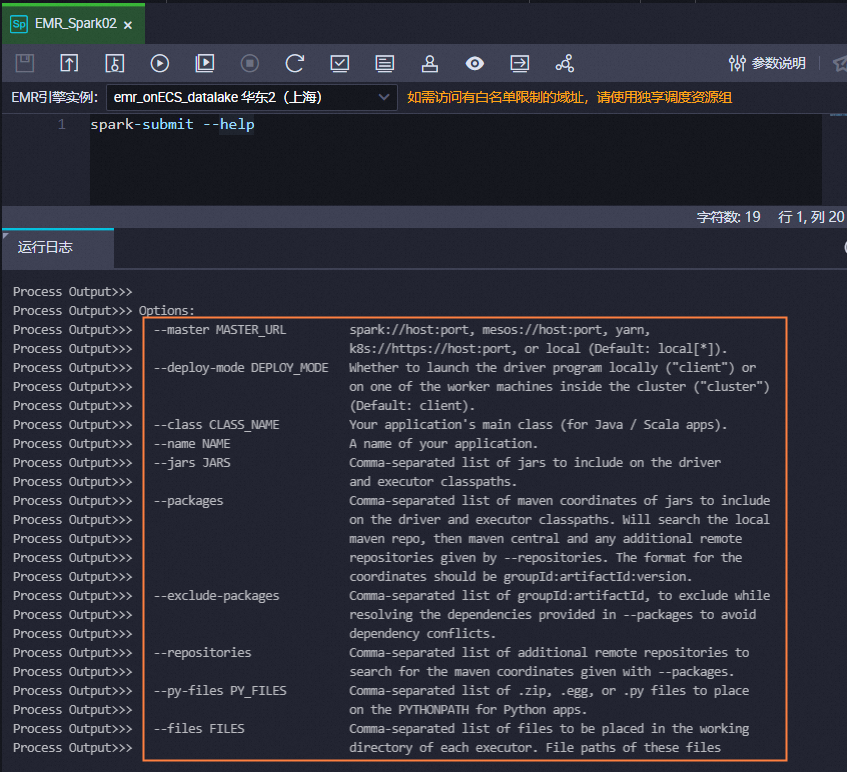
JAR包大于等于500MB时
创建EMR JAR资源。
JAR包大于等于500MB时,无法通过本地上传的方式直接上传为DataWorks的资源,建议直接将JAR包存储在EMR的HDFS中,并记录下JAR包的存储路径,以便后续在DataWorks调度Spark任务时引用该路径。
引用EMR JAR资源。
JAR包存储在HDFS时,您可以直接在EMR Spark节点中通过代码指定JAR包路径的方式引用JAR包。
双击创建的EMR Spark节点,打开EMR Spark 节点的代码编辑页面。
编写spark submit命令,示例如下。
spark-submit --master yarn --deploy-mode cluster --name SparkPi --driver-memory 4G --driver-cores 1 --num-executors 5 --executor-memory 4G --executor-cores 1 --class org.apache.spark.examples.JavaSparkPi hdfs:///tmp/jars/spark-examples_2.11-2.4.8.jar 100其中:
hdfs:///tmp/jars/spark-examples_2.11-2.4.8.jar:为JAR包实际在HDFS中的路径。
org.apache.spark.examples.JavaSparkPi:为您实际编译的JAR包中的任务主class。
其他参数为实际EMR集群的参数,需根据实际情况进行修改配置。您也可以执行以下命令查看spark submit的使用帮助,根据需要修改spark submit命令。
重要若您需要在Spark节点中使用Spark-submit命令简化的参数,您需要在代码中自行添加,例如,
--executor-memory 2G。Spark节点仅支持使用Yarn的Cluster模式提交作业。
spark-submit方式提交的任务,deploy-mode推荐使用cluster模式,不建议使用client模式。
spark-submit --help
方案二:直接引用OSS资源
当前节点可直接通过OSS REF的方式引用OSS资源,在运行EMR节点时,DataWorks会自动加载代码中的OSS资源至本地使用。该方式常用于“需要在EMR任务中运行JAR依赖”、“EMR任务需依赖脚本”等场景。
开发JAR资源。
代码依赖准备。
您可前往EMR集群,在集群Master节点的
/usr/lib/emr/spark-current/jars/路径下查看您所需的代码依赖。下面以Spark3.4.2版本为例,您需在打开已创建的IDEA项目添加pom依赖并引用相关插件。添加pom依赖
<dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.12</artifactId> <version>3.4.2</version> </dependency> <!-- Apache Spark SQL --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.12</artifactId> <version>3.4.2</version> </dependency> </dependencies>引用相关插件
<build> <sourceDirectory>src/main/scala</sourceDirectory> <testSourceDirectory>src/test/scala</testSourceDirectory> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.7.0</version> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> <plugin> <artifactId>maven-assembly-plugin</artifactId> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.2.2</version> <configuration> <recompileMode>incremental</recompileMode> </configuration> <executions> <execution> <goals> <goal>compile</goal> <goal>testCompile</goal> </goals> <configuration> <args> <arg>-dependencyfile</arg> <arg>${project.build.directory}/.scala_dependencies</arg> </args> </configuration> </execution> </executions> </plugin> </plugins> </build>编写代码示例。
package com.aliyun.emr.example.spark import org.apache.spark.sql.SparkSession object SparkMaxComputeDemo { def main(args: Array[String]): Unit = { // 创建 SparkSession val spark = SparkSession.builder() .appName("HelloDataWorks") .getOrCreate() // 打印Spark版本 println(s"Spark version: ${spark.version}") } }将代码打包成JAR文件。
编辑保存Scala代码后,将Scala代码打包成JAR文件。示例生成的JAR包为
SparkWorkOSS-1.0-SNAPSHOT-jar-with-dependencies.jar。
上传JAR资源。
完成代码开发后,您需登录OSS管理控制台,单击所在地域左侧导航栏的Bucket列表。
单击目标Bucket名称,进入文件管理页面。
本文示例使用的Bucket为
onaliyun-bucket-2。单击新建目录,创建JAR资源的存放目录。
配置目录名为
emr/jars,创建JAR资源的存放目录。上传JAR资源至JAR资源的存放目录。
进入存放目录,单击上传文件,在待上传文件区域单击扫描文件,添加
SparkWorkOSS-1.0-SNAPSHOT-jar-with-dependencies.jar文件至Bucket,单击上传文件。
引用JAR资源。
编辑引用JAR资源代码。
在已创建的EMR Spark节点编辑页面,编辑引用JAR资源代码。
spark-submit --class com.aliyun.emr.example.spark.SparkMaxComputeDemo --master yarn ossref://onaliyun-bucket-2/emr/jars/SparkWorkOSS-1.0-SNAPSHOT-jar-with-dependencies.jar引用参数说明:
参数
参数说明
class运行的主类全名称。
masterSpark应用程序的运行模式。
ossref文件路径格式为
ossref://{endpoint}/{bucket}/{object}endpoint:OSS对外服务的访问域名。Endpoint为空时,仅支持使用与当前访问的EMR集群同地域的OSS,即OSS的Bucket需要与EMR集群所在地域相同。
Bucket:OSS用于存储对象的容器,每一个Bucket有唯一的名称,登录OSS管理控制台,可查看当前登录账号下所有Bucket。
object:存储在Bucket中的一个具体的对象(文件名称或路径)。
运行EMR Spark节点任务。
编辑完成后您可单击
 图标,选择您所创建的Serverless资源组运行EMR Spark节点。待任务执行完成后,记录控制台打印的
图标,选择您所创建的Serverless资源组运行EMR Spark节点。待任务执行完成后,记录控制台打印的applicationIds,例如application_1730367929285_xxxx。结果查看。
创建EMR Shell节点并在EMR Shell节点执行
yarn logs -applicationId application_1730367929285_xxxx命令查看运行结果:
(可选)配置高级参数
您可在节点高级设置处配置Spark特有属性参数。更多Spark属性参数设置,请参考Spark Configuration。不同类型EMR集群可配置的高级参数存在部分差异,具体如下表。
DataLake集群/自定义集群:EMR on ECS
高级参数 | 配置说明 |
queue | 提交作业的调度队列,默认为default队列。 如果您在注册EMR集群至DataWorks工作空间时,配置了工作空间级的YARN资源队列:
关于EMR YARN说明,详情请参见队列基础配置,注册EMR集群时的队列配置详情请参见设置全局YARN资源队列。 |
priority | 优先级,默认为1。 |
FLOW_SKIP_SQL_ANALYZE | SQL语句执行方式。取值如下:
说明 该参数仅支持用于数据开发环境测试运行流程。 |
其他 |
|
EMR Serverless Spark集群
相关参数设置请参见提交Spark任务参数设置。
高级参数 | 配置说明 |
queue | 提交作业的调度队列,默认为dev_queue队列。 |
priority | 优先级,默认为1。 |
FLOW_SKIP_SQL_ANALYZE | SQL语句执行方式。取值如下:
说明 该参数仅支持用于数据开发环境测试运行流程。 |
SERVERLESS_RELEASE_VERSION | Spark引擎版本,默认使用管理中心的集群管理中集群配置的默认引擎版本。如需为不同任务设置不同的引擎版本,您可在此进行设置。 |
SERVERLESS_QUEUE_NAME | 指定资源队列,默认使用管理中心的集群管理中集群配置的默认资源队列。如有资源隔离和管理需求,可通过添加队列实现。详情请参见管理资源队列。 |
其他 |
|
Spark集群:EMR ON ACK
高级参数 | 配置说明 |
queue | 不支持。 |
priority | 不支持。 |
FLOW_SKIP_SQL_ANALYZE | SQL语句执行方式。取值如下:
说明 该参数仅支持用于数据开发环境测试运行流程。 |
其他 |
|
Hadoop集群:EMR on ECS
高级参数 | 配置说明 |
queue | 提交作业的调度队列,默认为default队列。 如果您在注册EMR集群至DataWorks工作空间时,配置了工作空间级的YARN资源队列:
关于EMR YARN说明,详情请参见队列基础配置,注册EMR集群时的队列配置详情请参见设置全局YARN资源队列。 |
priority | 优先级,默认为1。 |
FLOW_SKIP_SQL_ANALYZE | SQL语句执行方式。取值如下:
说明 该参数仅支持用于数据开发环境测试运行流程。 |
USE_GATEWAY | 设置本节点提交作业时,是否通过Gateway集群提交。取值如下:
说明 如果本节点所在的集群未关联Gateway集群,此处手动设置参数取值为 |
其他 |
|
执行SQL任务
三、配置节点调度
如您需要周期性执行创建的节点任务,可单击节点编辑页面右侧的调度配置,根据业务需求配置该节点任务的调度信息。配置详情请参见任务调度属性配置概述。
四、发布节点任务
节点任务配置完成后,需执行提交发布操作,提交发布后节点即会根据调度配置内容进行周期性运行。
单击工具栏中的
 图标,保存节点。
图标,保存节点。单击工具栏中的
 图标,提交节点任务。
图标,提交节点任务。提交时需在提交对话框中输入变更描述,并根据需要选择是否在节点提交后执行代码评审。
说明您需设置节点的重跑属性和依赖的上游节点,才可提交节点。
代码评审可对任务的代码质量进行把控,防止由于任务代码有误,未经审核直接发布上线后出现任务报错。如进行代码评审,则提交的节点代码必须通过评审人员的审核才可发布,详情请参见代码评审。
如您使用的是标准模式的工作空间,任务提交成功后,需单击节点编辑页面右上方的发布,将该任务发布至生产环境执行,操作请参见发布任务。
后续步骤
任务提交发布后,会基于节点的配置周期性运行,您可单击节点编辑界面右上角的运维,进入运维中心查看周期任务的调度运行情况。详情请参见管理周期任务。
常见问题
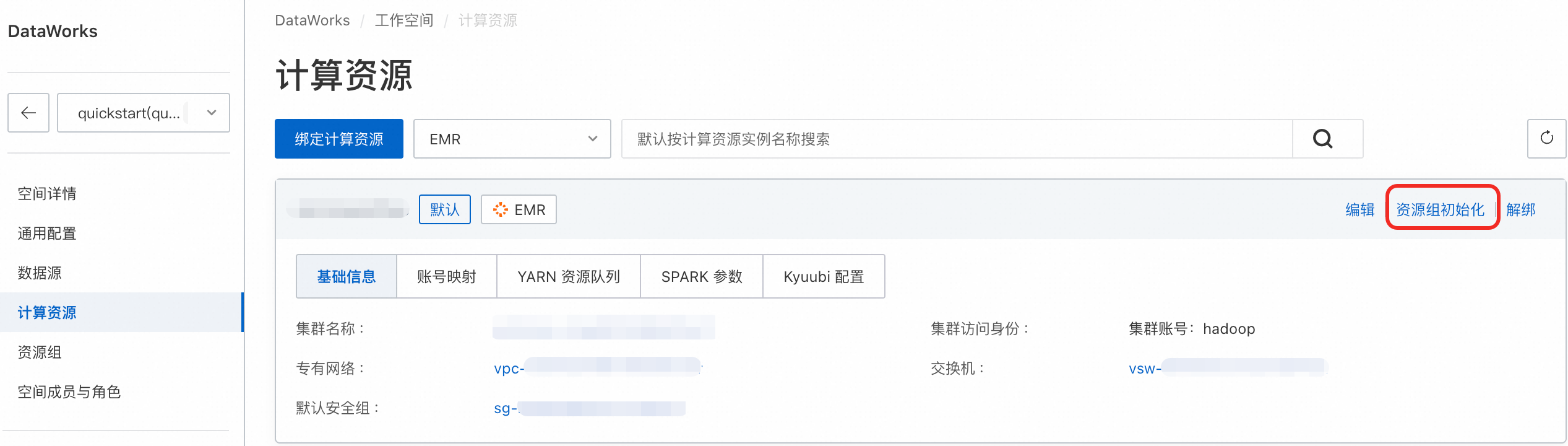
Q:节点运行出现连接超时?
A:请确保资源组和集群的网络联通。请进入计算资源的列表页,单击资源初始化,在弹窗中单击再次初始化,确保成功初始化。