整库实时同步功能通过一次性全量迁移与持续增量捕获相结合,将源数据库(如MySQL、Oracle)完整、低延迟地同步至目标系统。整库实时同步任务支持对源库历史数据进行全量同步,自动初始化目标端表结构与数据;随后,自动转为实时增量模式,利用CDC等技术持续捕获并同步后续的数据变更。此能力适用于实时数仓、数据湖构建等场景。本文以MySQL数据整库实时同步至MaxCompute为例,讲述任务配置方式。
准备工作
-
数据源准备
-
已创建来源与去向数据源,数据源配置详见:数据源管理。
-
确保数据源支持整库实时同步能力,参见:支持的数据源及同步方案。
-
部分数据源需要开启日志,如Hologres、Oracle等。不同的数据源开启方式不同,详见数据源配置:数据源列表。
-
-
资源组:已购买并配置Serverless资源组。
-
网络连通:资源组与数据源之间需完成网络连通配置。
适用范围
-
DataWorks支持整库实时和整库全增量两种类型。两者均可实现对源库的历史数据进行全量同步,随后自动转为实时增量模式,但两者的时效性和对目标表要求有一定差异:
-
整库实时同步任务支持在数据开发 (Data Studio) 与数据集成两大模块中进行配置,两者在功能上互通。
-
配置一致:无论是数据开发还是在数据集成模块中创建任务,其配置界面、参数设置和底层功能完全一致。
-
双向同步:在数据集成模块中创建的任务,会自动同步并显示在数据开发模块的
data_integration_jobs目录下。这些任务会按照源端类型-目的端类型的通道进行归类,便于统一管理。
-
配置任务
步骤一:新建同步任务
-
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的,在下拉框中选择对应工作空间后单击进入数据集成。
-
在左侧导航栏单击同步任务,然后在页面顶部单击新建同步任务,并配置任务信息:
-
数据来源类型:
MySQL。 -
数据去向类型:
MaxCompute。 -
具体类型:
整库实时。 -
同步步骤:
-
结构迁移:自动在目标端创建与源端匹配的数据库对象(如表、字段、数据类型等),但不包含数据。
-
全量同步(可选):一次性将源端指定对象(如表)中的所有历史数据完整地复制到目标端。通常用于首次数据迁移或数据初始化。
-
增量同步(可选):在全量同步完成后,持续地捕获源端发生的变更数据(新增、修改、删除),并将其同步至目标端。
-
-
步骤二:配置数据源与运行资源
-
在来源数据源区域选择已添加至工作空间的
MySQL数据源,在去向数据源区域选择已添加的MaxCompute数据源。 -
在运行资源区域,选择同步任务所使用的资源组,并为该任务分配资源组CU。
说明当任务日志中出现
Please confirm whether there are enough resources...等资源不足的提示时,说明当前资源组的可用计算单元(CU)已无法满足任务启动或运行的需求。可在资源组配置面板中,适当调高任务占用的CU数量,以分配更多计算资源。资源设置大小推荐值详见:数据集成推荐CU,实际使用时需根据实际情况进行调整。
-
并确保来源数据源与去向数据源均通过连通性检查。
步骤三:同步方案配置
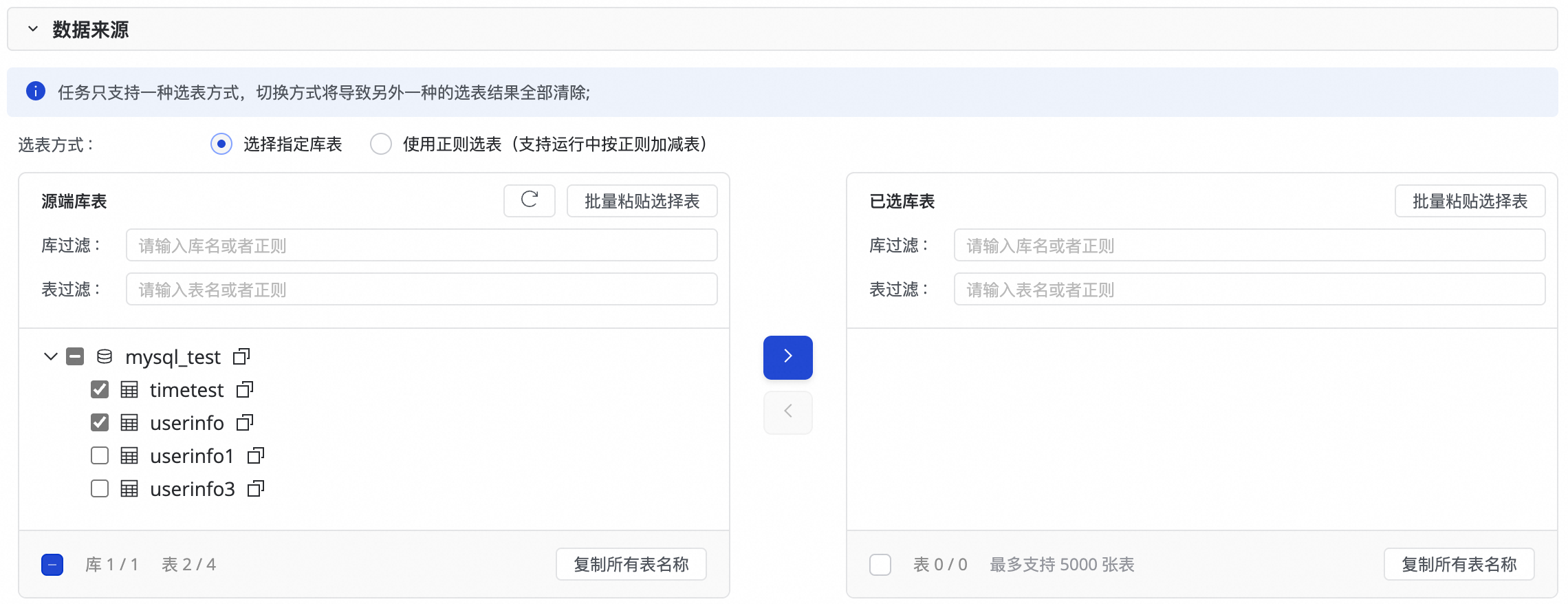
1. 配置数据来源
此步骤中,您可以在源端库表区域选择源端数据源下需要同步的表,并单击![]() 图标,将其移动至右侧已选库表。若库表数较多,可以使用库过滤或者表过滤,通过配置正则表达式来选择需要同步的表。
图标,将其移动至右侧已选库表。若库表数较多,可以使用库过滤或者表过滤,通过配置正则表达式来选择需要同步的表。
当需要将多个分库分表(结构相同)写入同一目标表时,可使用正则选表。
在源表配置中填写正则表达式,DataWorks 将自动识别并采集所有匹配的源表,并将其数据统一写入该表达式映射的目标表中。
此方式适用于分片表合并同步场景,提升配置效率,避免重复添加多对一同步规则。
2. 配置数据去向
若整库实时同步任务仅选择增量同步,可配置写入目的表时的增量同步模式。
-
重放:仅支持PK Delta Table,与正常同步类似,仅同步数据字段。
-
增量流水:支持普通表和Append Delta Table,将源表实时数据附加增删改等元信息后,写入至目的表。增量流水表格式可参见:增量流水表格式。
3. 目标表映射
在此步骤,您需要定义源表与目标表的映射规则,并指定主键、动态分区、DDL/DML配置等规则,以确定数据写入方式。
|
操作 |
说明 |
||||||||||||
|
刷新映射 |
系统会自动列出您选择的源端表,但目标表的具体属性需要您刷新确认后才能生效。
|
||||||||||||
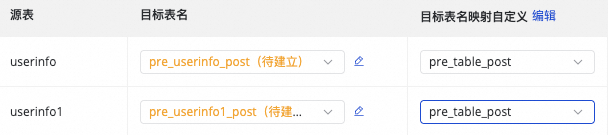
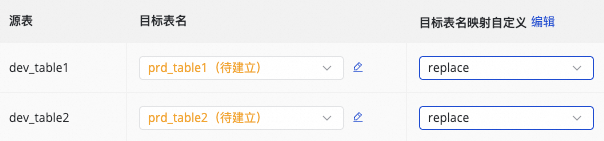
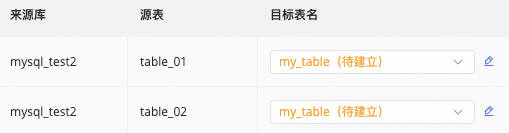
|
目标表名映射自定义(可选) |
系统存在默认的表名生成规则:
可实现如下场景:
|
||||||||||||
|
编辑字段类型映射(可选) |
系统存在默认的源端字段类型与目标端字段类型映射,您可以单击表格右上角的编辑字段类型映射,自定义源端表与目标端表字段类型映射关系,配置完后单击应用并刷新映射。 编辑字段类型映射时,需要注意字段类型转换规则是否正确,否则会导致类型转换失败而产生脏数据,影响任务运行。 |
||||||||||||
|
编辑目标表结构(可选) |
系统会根据自定义的表名映射规则,自动创建尚不存在的目标表,或复用已存在的同名表。 DataWorks将基于源端表结构自动生成目标表结构,常规场景下无需人工干预。您也可以通过以下方式,修改表的表结构:
已存在的表仅支持添加字段;新建表添加字段、分区字段,设置表类型或表属性等。详见界面开放编辑区域。 |
||||||||||||
|
目标表字段赋值 |
原生字段会根据源端表和目标表的同名字段进行自动映射,上述步骤中的新增字段和分区字段需要手动赋值。操作如下:
在赋值时支持赋值常量与变量,可在赋值方式中进行切换类型,支持方式如下:
说明
注意,分区个数过多会影响同步效率,单日新增分区超过1000个,分区创建失败并终止任务。因此,定义分区字段赋值方式时,需要预估分区可能产生的个数。谨慎使用秒级、毫秒级的分区创建方式。 |
||||||||||||
|
设置源端切分列 |
您可以在源端切分列中下拉选择源端表中的字段或选择不切分。同步任务执行时将根据该字段切分为多个task,以便并发、分批读取数据。 推荐使用表主键作为源端切分列,不支持字符串、浮点和日期等其他类型。 目前仅源端为MySQL时支持源端切分列。 |
||||||||||||
|
是否执行全量同步 |
若已在步骤三配置全量同步,可以单独取消同步某个表的全量数据同步。适用于已经通过其他方式将全量数据同步至目标端的场景。 |
||||||||||||
|
全量条件 |
在全量阶段对源端进行条件过滤。此处只需写where子句,不需要写出where关键字。 |
||||||||||||
|
DML规则配置 |
DML消息处理用于在数据写入目标端之前,对源端捕获的变更数据( |
||||||||||||
|
其他 |
表类型:MaxCompute支持普通表、
Delta Table详细介绍参见:Delta Table。 |
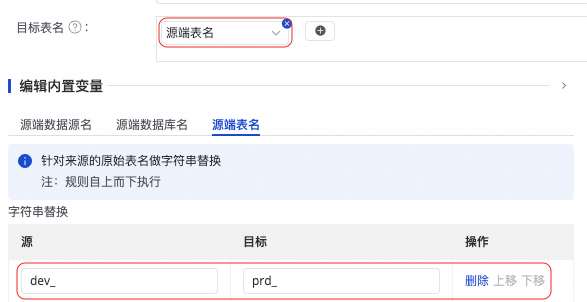
 按钮,选择手动输入和内置变量进行拼接,生成目标表名。其中变量支持源端数据源名,源端数据库名和源端表名。
按钮,选择手动输入和内置变量进行拼接,生成目标表名。其中变量支持源端数据源名,源端数据库名和源端表名。

 按钮添加字段。
按钮添加字段。 提示中查看变量的具体含义。
提示中查看变量的具体含义。步骤四:高级配置
高级参数配置
如果需要对任务做精细化配置,达到自定义同步需求,可以进入高级参数页签,修改高级参数。
-
单击界面右上方的高级配置,进入高级参数配置页面。
-
根据参数提示,修改参数值,参数含义见参数名称后的解释。
-
也支持使用AI配置,输入自然语言修改指令,如调整任务并发数,由大模型生成参数推荐值,您可以根据实际情况选择是否接受AI生成的参数。
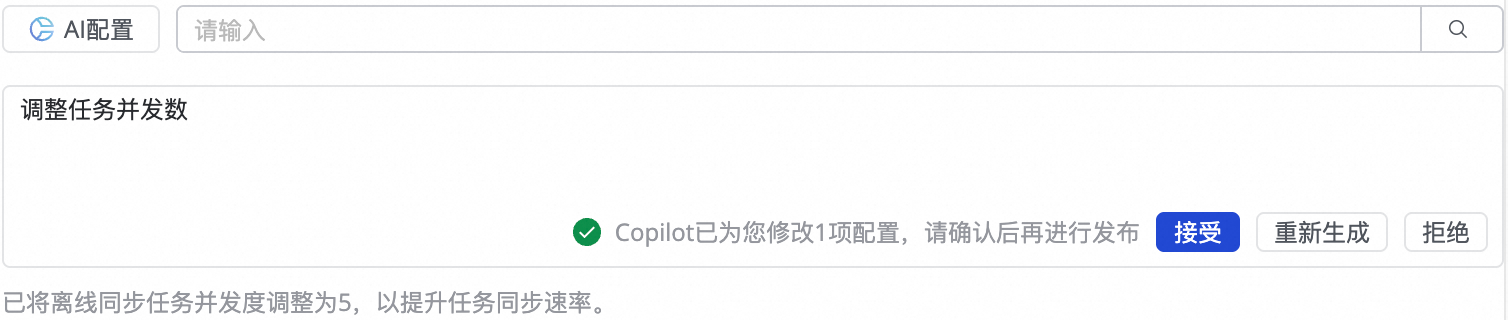
请在完全明白对应参数的含义情况下再进行修改,避免产生任务延时、资源占用过大导致阻塞其他任务、数据丢失等不可预料的问题。
DDL能力配置
实时同步部分链路可以感知源端表结构的元数据变更,并且通知目标端,使目标端同步更新,或采取其他诸如告警、忽略或终止运行等处理策略。
您可以单击界面右上角的DDL能力配置,针对每一种变更类型设置对应的处理策略,不同的通道支持的处理策略不同。
-
正常处理:由目标端处理源端的DDL变更信息。
-
忽略:忽略变更消息,目标端不做修改。
-
出错:终止整库实时同步任务,状态置为出错。
-
告警:当源端出现此类变更时,向用户告警。需在报警配置中配置DDL通知规则。
当源端新增列并通过DDL同步在目标端也创建了该列后,系统不会对目标表中的存量数据进行数据回填。
步骤五:发布并执行任务
-
完成所有配置后,单击页面底部的保存,完成任务配置。
-
整库同步任务不支持直接调试,需要发布至运维中心运行。因此新建或者编辑任务均需执行发布操作后方可生效。
-
发布时,若勾选发布后直接启动运行,则在发布时会同步启动任务。否则,发布完成后,需要进入界面,在目标任务的操作列,手动启动任务。
-
单击任务列表中对应任务的名称/ID,查看任务的详细执行过程。
步骤六:报警配置
1.新增报警
在列表,找到对应的整库实时任务,单击操作列的,可为任务配置告警策略。
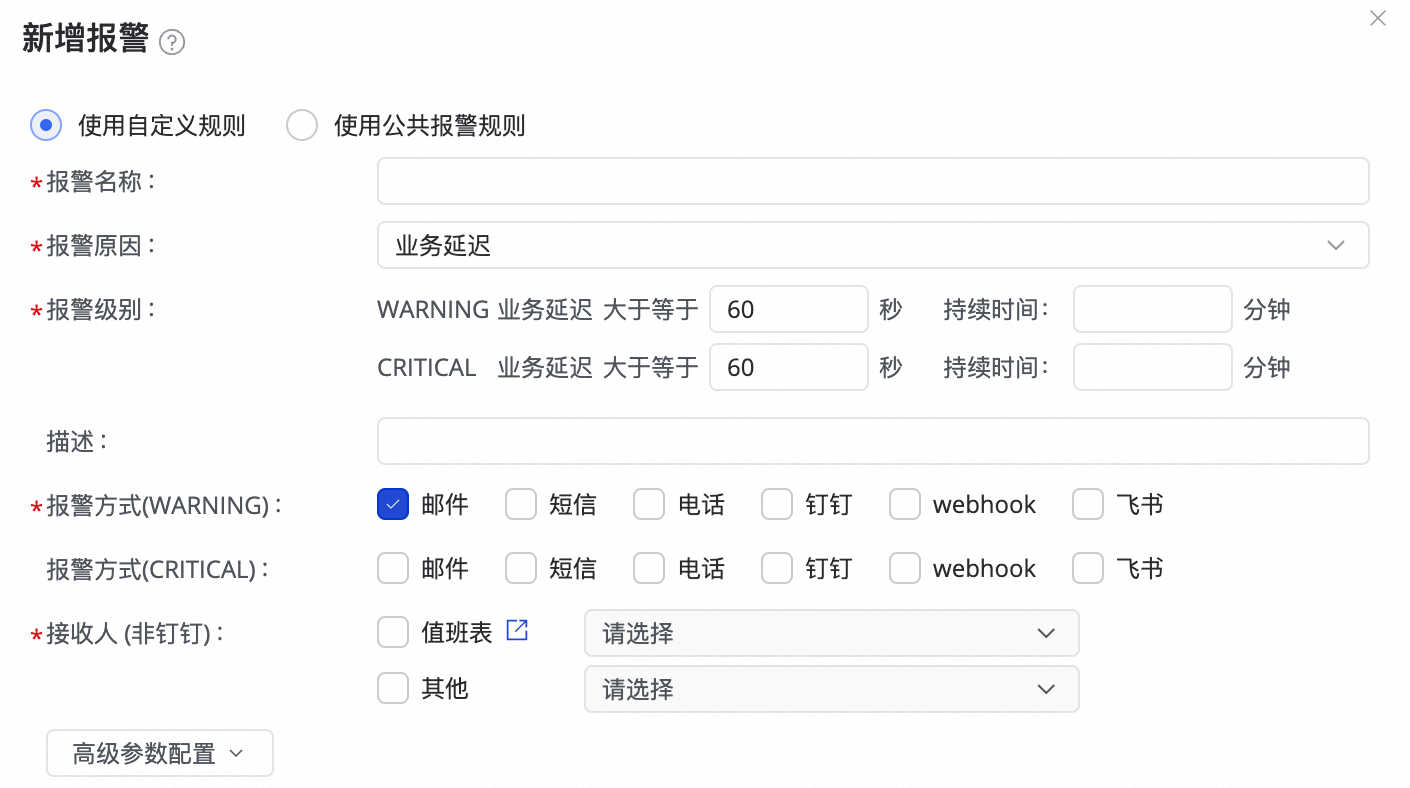
(1) 单击新建规则,配置报警规则。
您可以通过设置报警原因,对任务的业务延迟、Failover、任务状态、DDL通知、任务资源利用率等指标进行监控,并根据指定的阈值设置CRITICAL或WARNING两种不同级别的告警方式。
-
通过设置高级参数配置,可以控制报警信息发送的时间间隔,防止一次性发送信息太多,造成浪费和消息堆积。
-
若报警原因选择业务延迟、任务状态和任务资源利用率,也支持开启恢复通知,方便任务恢复正常后,通知接收人。
(2) 管理报警规则。
对于已创建的报警规则,您可以通过报警开关控制报警规则是否开启,同时,您可以根据报警级别将报警发送给不同的人员。
2.查看报警
单击展开任务列表的,进入报警事件,可以查看已经发生的告警信息。
管理任务
编辑任务
-
在界面,找到已创建的同步任务,单击操作列的更多,单击编辑,可以修改任务信息,操作步骤同任务配置。
-
对于非运行状态的任务,您可以直接修改配置并保存,然后将任务发布至生产环境使其生效。
-
对于运行中的任务,编辑任务并发布时,若未选择发布后直接启动运行,原有的操作按钮将变为应用更新。您须单击此按钮,变更才会在线上环境中生效。
-
单击应用更新后,系统会对变更内容执行“停止,发布,重启”三个步骤。
-
若变更方式为新增表或切换已有表:
更新应用时不支持选择位点,单击确认后,执行新表的结构迁移和全量初始化,待全量初始化完成后,开始与其他原有表一起执行增量操作。
-
若修改其他信息:
更新应用时支持选择位点,单击确认后,从指定位点继续运行。若不指定,从上次停止的时间位点开始运行。
未修改的表均不受影响,在更新重启后,会从上次停止的时间点继续运行。
-
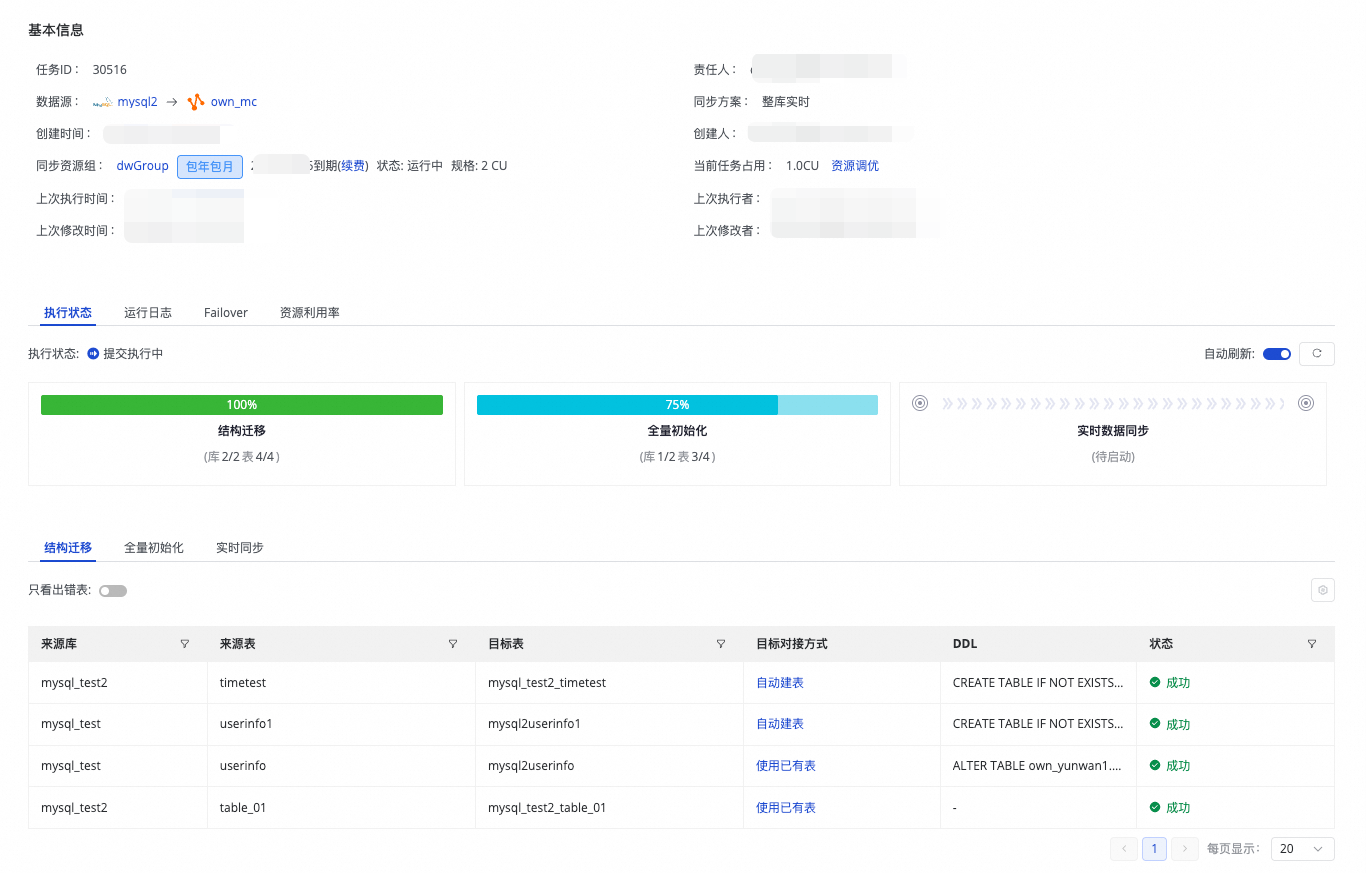
查看任务
创建完成同步任务后,您可以在同步任务页面查看当前已创建的同步任务列表及各个同步任务的基本信息。

-
您可以在操作列启动或停止同步任务,在更多中可以对同步任务进行编辑、查看等操作。
-
已启动的任务您可以在执行概况中看到任务运行的基本情况,也可以单击对应的概况区域查看执行详情。
断点续传
适用场景
在任务启动或重启时,手动重置位点主要适用于以下场景:
-
任务恢复与数据续传:当任务因故中断后,为确保数据从准确的断点处恢复,可能需要手动指定一个中断时间点作为新的启动位点。
-
数据问题排查与回溯:若发现同步后的数据存在丢失或异常,可将位点回溯至问题发生前的时间点,对问题数据进行重放和修复。
-
任务配置重大变更:在对任务配置(如目标表结构、字段映射等)进行重大调整后,建议重置位点从一个明确的时间点开始同步,以保证新配置下的数据准确性。
操作说明
单击启动,在弹窗中选择是否重置位点:

-
不勾选重置位点,直接运行:继续从上次停止的时间位点(最后一次checkpoint)运行。
-
重置位点,并选择时间:从指定的时间位点开始运行,注意选择的时间不要超过源端的Binlog支持的最早时间位点。
如果您在执行同步任务时提示位点错误或不存在,请按如下方式尝试解决:
-
重置位点:在启动实时同步任务时,重置位点并选择源库可用的最早位点。
-
调整日志保留时间:如果数据库位点过期,可以考虑在数据库中调整日志的保留时间,例如设置为7天。
-
数据同步:如果数据已经丢失,可以考虑重新全量同步,或者配置一个离线同步任务来手动同步丢失的数据。
常见问题
整库实时常见问题参见:实时同步常见问题、全增量同步任务常见问题。
附录:增量流水表格式
源表字段平铺
|
字段名称 |
说明 |
|
sequence_id |
增量事件的记录 ID,值唯一且递增。 |
|
operation_type |
操作类型(I/D/U) |
|
execute_time |
数据对应的时间戳 |
|
before_image |
是否是变更前(Y/N) |
|
after_image |
是否是变更后(Y/N) |
|
src_datasource |
数据来源的数据源 |
|
src_database |
数据来源的数据库 |
|
src_table |
数据来源的表 |
|
字段1 |
真实数据字段1 |
|
字段2 |
真实数据字段2 |
|
字段3 |
真实数据字段3 |
源表字段合并为 JSON
|
字段名称 |
说明 |
|
sequence_id |
增量事件的记录 ID,值唯一且递增。 |
|
operation_type |
操作类型(I/D/U) |
|
execute_time |
数据对应的时间戳 |
|
before_image |
是否是变更前(Y/N) |
|
after_image |
是否是变更后(Y/N) |
|
src_datasource |
数据来源的数据源 |
|
src_database |
数据来源的数据库 |
|
src_table |
数据来源的表 |
|
ddl_sql |
当操作为 DDL 类型时,DDL 语句写入本字段 |
|
data_columns |
真实数据字段合并为 JSON |