本文为您介绍如何将同步至MaxCompute的用户信息表ods_user_info_d_odps及访问日志数据ods_raw_log_d_odps,通过DataWorks的MaxCompute节点加工得到目标用户画像数据,阅读本文后,您可以了解如何通过DataWorks+MaxCompute产品组合来计算和分析已同步的数据,完成数仓简单数据加工场景。
前提条件
开始本案例前,请首先完成同步数据中的操作。
已通过数据集成将存储于MySQL的用户基本信息
ods_user_info_d同步至MaxCompute的ods_user_info_d_odps表。已通过数据集成将存储于OSS的网站访问日志
user_log.txt同步至MaxCompute的ods_raw_log_d_odps表。
章节目标
本小节将对同步到MaxCompute上的ods_user_info_d_odps和ods_raw_log_d_odps进行加工处理,并生成基本用户画像表。
将同步至MaxCompute的日志表
ods_raw_log_d_odps将日志信息字段拆分为多个字段,并生成新的明细日志表dwd_log_info_di_odps。利用明细日志表
dwd_log_info_di_odps和用户表ods_user_info_d_odps的uid字段进行关联,生成汇总用户日志表dws_user_info_all_di_odps。dws_user_info_all_di_odps表字段较多,直接应用于数据消费,表数据较多,所以将其进一步加工为ads_user_info_1d_odps表。
进入数据开发
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的,在下拉框中选择对应工作空间后单击进入数据开发。
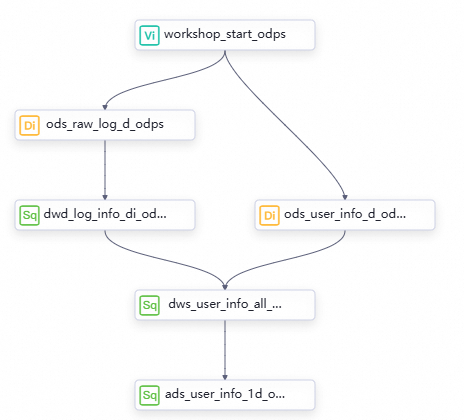
一、设计工作流程
在同步数据阶段,已经成功将数据同步至MaxCompute,接下来的流程的目标是对数据进行进一步加工,以输出基本用户画像数据。
各层级节点以及工作逻辑。
在业务流程画布中单击新建节点,创建以下节点,以供加工数据使用。
节点分类
节点类型
节点名称
(以最终产出表命名)
代码逻辑
MaxCompute
ODPS SQL
dwd_log_info_di_odps使用内置函数,自定义函数等完成原始日志
ods_raw_log_d_odps数据拆分写入dwd_log_info_di_odps表多个字段。MaxCompute
ODPS SQL
dws_user_info_all_di_odps将用户基本信息和初步加工后的日志数据进行汇总,合并为一张表。
MaxCompute
ODPS SQL
ads_user_info_1d_odps进一步加工产出基本用户画像。
流程DAG图。
将节点组件拖拽至业务流程画布,并通过拉线设置节点上下游依赖的方式,设计数据加工阶段的业务流程。
二、配置业务流程
创建MaxCompute表
提前新建dwd_log_info_di_odps、dws_user_info_all_di_odps、ads_user_info_1d_odps表,用于存放每层加工后的数据。以下仅快速创建相关表,更多MaxCompute表相关操作,请参见创建并使用MaxCompute表。
进入新建表入口。
在数据开发页面,打开同步数据阶段创建的业务流程WorkShop。右键单击MaxCompute,选择新建表。
定义MaxCompute表结构。
在新建表对话框中,输入表名,单击新建。此处需要创建三张表,表名分别为
dwd_log_info_di_odps、dws_user_info_all_di_odps、ads_user_info_1d_odps。选择DDL方式建表,三张表建表命令请参考下文。提交至引擎生效。
表结构定义完成后,分别单击提交到开发环境和提交到生产环境,系统将根据您的配置在开发环境与生产环境对应计算引擎项目中分别创建目标引擎物理表。
提交表至DataWorks的开发环境,即在开发环境的MaxCompute引擎中创建当前表。
提交表至DataWorks的生产环境,即在生产环境的MaxCompute引擎中创建当前表。
说明若使用简单模式的工作空间,仅需将表提交至生产环境。简单模式与标准模式工作空间的介绍,详情请参见必读:简单模式和标准模式的区别。
DataWorks与MaxCompute关系及对应环境的MaxCompute引擎,详情请参见:DataWorks On MaxCompute使用说明。
新建dwd_log_info_di_odps表
双击dwd_log_info_di_odps表,在右侧的编辑页面单击DDL,输入下述建表语句。
CREATE TABLE IF NOT EXISTS dwd_log_info_di_odps (
ip STRING COMMENT 'ip地址',
uid STRING COMMENT '用户ID',
time STRING COMMENT '时间yyyymmddhh:mi:ss',
status STRING COMMENT '服务器返回状态码',
bytes STRING COMMENT '返回给客户端的字节数',
region STRING COMMENT '地域,根据ip得到',
method STRING COMMENT 'http请求类型',
url STRING COMMENT 'url',
protocol STRING COMMENT 'http协议版本号',
referer STRING COMMENT '来源url',
device STRING COMMENT '终端类型 ',
identity STRING COMMENT '访问类型 crawler feed user unknown'
)
PARTITIONED BY (
dt STRING
)
LIFECYCLE 14;新建dws_user_info_all_di_odps表
双击dws_user_info_all_di_odps表,在右侧的编辑页面单击DDL,输入下述建表语句。
CREATE TABLE IF NOT EXISTS dws_user_info_all_di_odps (
uid STRING COMMENT '用户ID',
gender STRING COMMENT '性别',
age_range STRING COMMENT '年龄段',
zodiac STRING COMMENT '星座',
region STRING COMMENT '地域,根据ip得到',
device STRING COMMENT '终端类型 ',
identity STRING COMMENT '访问类型 crawler feed user unknown',
method STRING COMMENT 'http请求类型',
url STRING COMMENT 'url',
referer STRING COMMENT '来源url',
time STRING COMMENT '时间yyyymmddhh:mi:ss'
)
PARTITIONED BY (
dt STRING
)
LIFECYCLE 14;新建ads_user_info_1d_odps表
双击ads_user_info_1d_odps表,在右侧的编辑页面单击DDL,输入下述建表语句。
CREATE TABLE IF NOT EXISTS ads_user_info_1d_odps (
uid STRING COMMENT '用户ID',
region STRING COMMENT '地域,根据ip得到',
device STRING COMMENT '终端类型 ',
pv BIGINT COMMENT 'pv',
gender STRING COMMENT '性别',
age_range STRING COMMENT '年龄段',
zodiac STRING COMMENT '星座'
)
PARTITIONED BY (
dt STRING
)
LIFECYCLE 14; 创建函数(getregion)
根据同步的实验日志数据结构,我们需要通过函数等方式将其拆解成表格。本案例已为您提供用于将IP解析为地域的函数所需资源,您仅需将其下载至本地,并在DataWorks注册函数前,将函数涉及的资源上传至DataWorks空间即可。
该函数仅为本教程使用(IP资源样例),若需在正式业务中实现IP到地理位置的映射功能,需前往专业IP网站获取相关IP转换服务。
上传资源(ip2region.jar)。
- 说明
ip2region.jar此资源样例仅为教程使用。 在数据开发页面打开WorkShop业务流程。右键单击MaxCompute,选择。
单击上传,选择已下载至本地的ip2region.jar,单击打开。
说明请选中上传为ODPS资源。
资源名称无需与上传的文件名保持一致。
单击工具栏
 按钮,将资源提交至开发环境对应的MaxCompute引擎项目。
按钮,将资源提交至开发环境对应的MaxCompute引擎项目。
注册函数(getregion)。
进入函数注册页。
在数据开发页面打开业务流程,右键单击MaxCompute,选择新建函数。
填写函数名称。
在新建函数对话框中,输入函数名称
getregion,单击新建。在注册函数对话框中,配置各项参数。
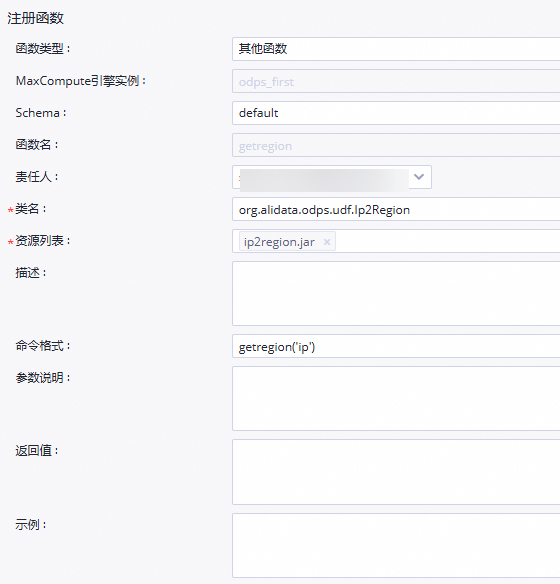
参数
描述
函数类型
选择函数类型。
MaxCompute引擎实例
默认不可以修改。
函数名
新建函数时输入的函数名称。
责任人
选择责任人。
类名
输入
org.alidata.odps.udf.Ip2Region。资源列表
输入
ip2region.jar。描述
输入IP地址转换地域。
命令格式
输入
getregion('ip')。参数说明
输入IP地址。
单击
按钮,将函数提交至开发环境对应的引擎。
配置MaxCompute数据加工节点
本案例需要将每层加工逻辑通过ODPS SQL调度实现,由于各层节点间存在强血缘依赖,并且在数据同步阶段已将同步任务产出表手动添加为节点的输出,所以本案例数据加工类的任务依赖关系通过DataWorks自动解析机制根据血缘自动配置。
配置dwd_log_info_di_odps节点
在业务流程面板,双击dwd_log_info_di_odps节点,利用创建的函数处理上游表ods_raw_log_d_odps字段的SQL代码,并将其写入dwd_log_info_di_odps表中,数据加工展示可参考:附录:加工示例。
编辑代码。
-- 场景:以下SQL使用函数getregion对原始日志数据中的ip进行解析,并通过正则等方式,将原始数据拆解为可分析字段写入并写入dwd_log_info_di_odps表。 -- 本案例已为您准备好用于将IP解析为地域的函数getregion。 -- 补充: -- 1. 在DataWorks节点中使用函数前,您需要先将注册函数所需资源上传至DataWorks,再通过可视化方式使用该资源注册函数。 -- 本案例注册函数getregion所用的资源为ip2region.jar。 -- 2. DataWorks提供调度参数,可实现调度场景下,将每日增量数据写入目标表对应业务分区。 -- 在实际开发场景下,您可通过${变量名}格式定义代码变量,并在调度配置页面通过为变量赋值调度参数的方式,实现调度场景下代码动态入参。 INSERT OVERWRITE TABLE dwd_log_info_di_odps PARTITION (dt='${bizdate}') SELECT ip , uid , time , status , bytes , getregion(ip) AS region --使用自定义UDF通过IP得到地域。 , regexp_substr(request, '(^[^ ]+ )') AS method --通过正则把request差分为3个字段。 , regexp_extract(request, '^[^ ]+ (.*) [^ ]+$') AS url , regexp_substr(request, '([^ ]+$)') AS protocol , regexp_extract(referer, '^[^/]+://([^/]+){1}') AS referer --通过正则清晰refer,得到更精准的URL。 , CASE WHEN TOLOWER(agent) RLIKE 'android' THEN 'android' --通过agent得到终端信息和访问形式。 WHEN TOLOWER(agent) RLIKE 'iphone' THEN 'iphone' WHEN TOLOWER(agent) RLIKE 'ipad' THEN 'ipad' WHEN TOLOWER(agent) RLIKE 'macintosh' THEN 'macintosh' WHEN TOLOWER(agent) RLIKE 'windows phone' THEN 'windows_phone' WHEN TOLOWER(agent) RLIKE 'windows' THEN 'windows_pc' ELSE 'unknown' END AS device , CASE WHEN TOLOWER(agent) RLIKE '(bot|spider|crawler|slurp)' THEN 'crawler' WHEN TOLOWER(agent) RLIKE 'feed' OR regexp_extract(request, '^[^ ]+ (.*) [^ ]+$') RLIKE 'feed' THEN 'feed' WHEN TOLOWER(agent) NOT RLIKE '(bot|spider|crawler|feed|slurp)' AND agent RLIKE '^[Mozilla|Opera]' AND regexp_extract(request, '^[^ ]+ (.*) [^ ]+$') NOT RLIKE 'feed' THEN 'user' ELSE 'unknown' END AS identity FROM ( SELECT SPLIT(col, '##@@')[0] AS ip , SPLIT(col, '##@@')[1] AS uid , SPLIT(col, '##@@')[2] AS time , SPLIT(col, '##@@')[3] AS request , SPLIT(col, '##@@')[4] AS status , SPLIT(col, '##@@')[5] AS bytes , SPLIT(col, '##@@')[6] AS referer , SPLIT(col, '##@@')[7] AS agent FROM ods_raw_log_d_odps WHERE dt ='${bizdate}' ) a;配置调度属性。
配置页面单击右侧调度配置,可进入调度配置面板配置调度与节点信息,详情可参见节点调度配置。以下为配置的内容:
配置项
配置内容
图示
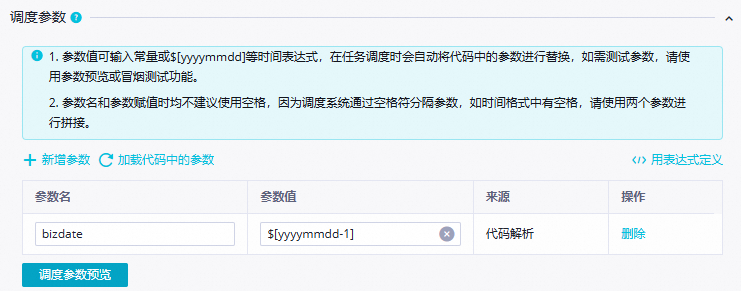
调度参数
在调度参数配置参数:
参数名:
bizdate。参数值:
$[yyyymmdd-1]。
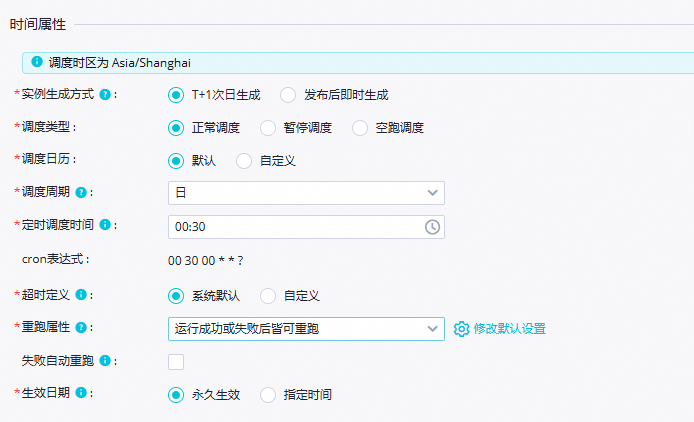
时间属性
调度周期:
日。定时调度时间:
00:30。重跑属性:运行成功或失败后皆可重跑。
其余参数保持默认即可。
说明当前节点每日起调时间由业务流程虚拟节点workshop_start的定时调度时间控制,即每日00:30后才会调度。
资源属性
选择准备环境阶段创建的Serverless资源组。

调度依赖
通过代码自动解析自动将产出
ods_raw_log_d_odps表数据的ods_raw_log_d_odps节点设置为当前节点dwd_log_info_di_odps的上游依赖。将dwd_log_info_di_odps表作为节点输出,方便下游查询该表数据时自动挂上当前节点依赖。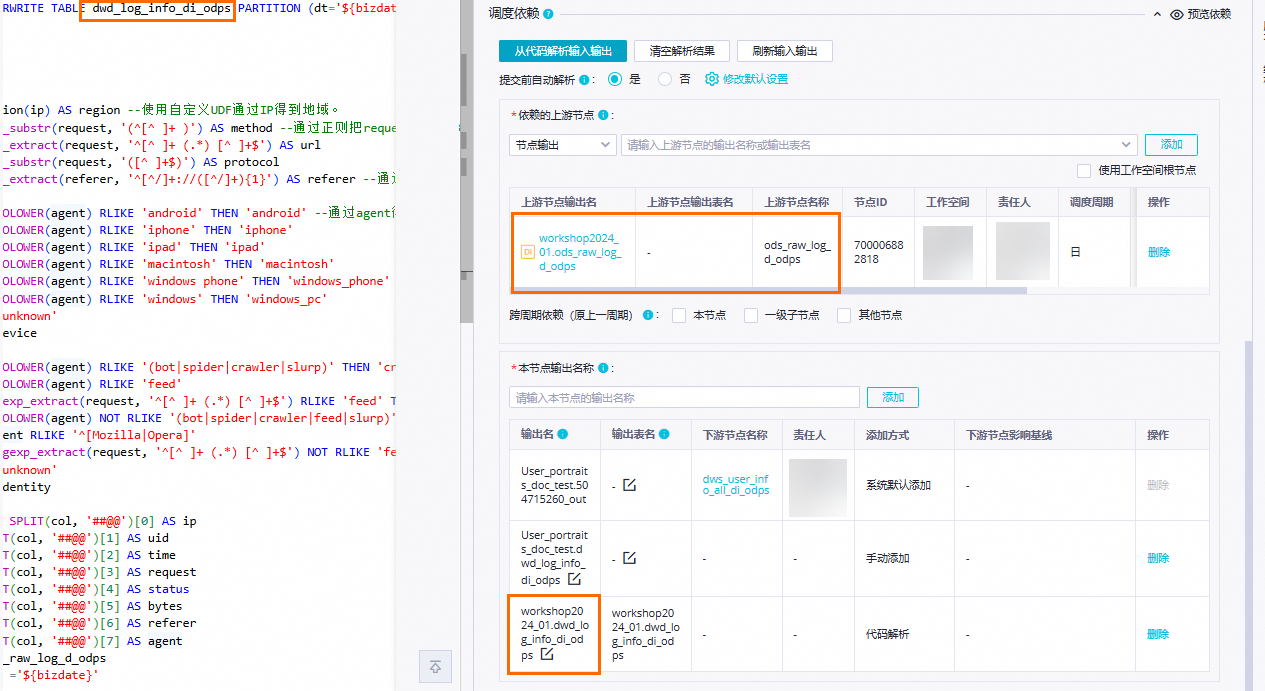 说明
说明依赖的上游节点:单击代码解析输入输出按钮,会根据代码中的表名解析到上游节点配置的
MaxCompute生产项目名称.表名的输出节点名作为上游节点输出名。本节点输出名称:单击代码解析输入输出按钮,会根据代码中的表名解析生成本节点生成
MaxCompute生产项目名称.表名格式的输出名,输出给下游节点。本案例其他必填配置项,您可按需自行配置,配置完成后,在节点代码编辑页面,单击工具栏中的
 按钮,保存当前配置。
按钮,保存当前配置。
配置dws_user_info_all_di_odps节点
在业务流程面板中,双击dws_user_info_all_di_odps节点,编写合并上游表dwd_log_info_di_odps和ods_user_info_d_odps的SQL代码,写入dws_user_info_all_di_odps表中。
编辑代码。
-- 场景:将加工后的日志数据dwd_log_info_di_odps与用户基本信息数据ods_user_info_d_odps汇总写入dws_user_info_all_di_odps表。 -- 补充:DataWorks提供调度参数,可实现调度场景下,将每日增量数据写入目标表对应业务分区。 -- 在实际开发场景下,您可通过${变量名}格式定义代码变量,并在调度配置页面通过为变量赋值调度参数的方式,实现调度场景下代码动态入参。 INSERT OVERWRITE TABLE dws_user_info_all_di_odps PARTITION (dt='${bizdate}') SELECT COALESCE(a.uid, b.uid) AS uid , b.gender , b.age_range , b.zodiac , a.region , a.device , a.identity , a.method , a.url , a.referer , a.time FROM ( SELECT * FROM dwd_log_info_di_odps WHERE dt = '${bizdate}' ) a LEFT OUTER JOIN ( SELECT * FROM ods_user_info_d_odps WHERE dt = '${bizdate}' ) b ON a.uid = b.uid;配置调度属性。
配置页面单击右侧调度配置,可进入调度配置面板配置调度与节点信息,详情可参见节点调度配置。以下为配置的内容:
配置项
配置内容
图示
调度参数
在调度参数配置参数:
参数名:
bizdate参数值:
$[yyyymmdd-1]
时间属性
调度周期:
日。定时调度时间:
00:30。重跑属性:运行成功或失败后皆可重跑。
其余参数保持默认即可。
说明当前节点每日起调时间由业务流程虚拟节点workshop_start的定时调度时间控制,即每日00:30后才会调度。
资源属性
选择准备环境阶段创建的Serverless资源组。
调度依赖
通过代码自动解析自动将产出
dwd_log_info_di_odps和ods_user_info_d_odps表数据的节点dwd_log_info_di_odps、ods_user_info_d_odps作为当前节点dws_user_info_all_di_odps的上游依赖。将节点产出表dws_user_info_all_di_odps作为节点输出,方便下游查询该表数据时自动挂上当前节点依赖。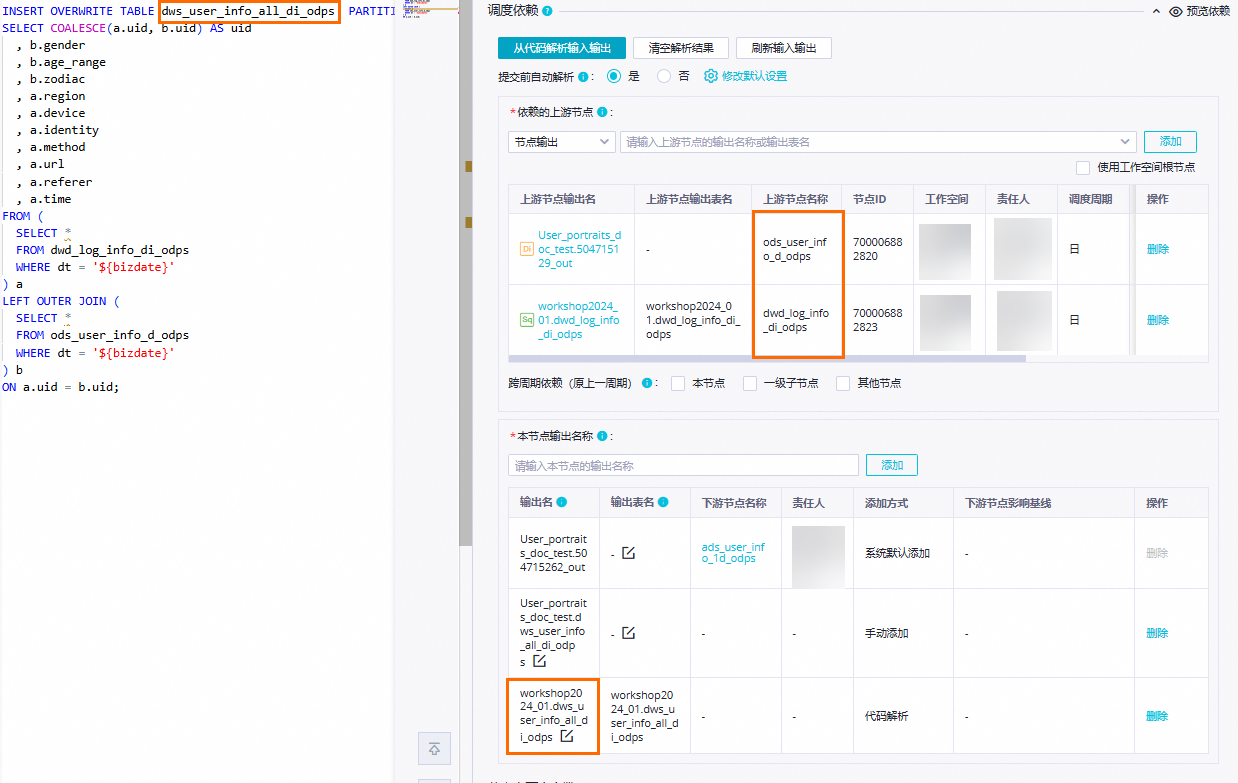 说明
说明依赖的上游节点:单击代码解析输入输出按钮,会根据代码中的表名解析到上游节点配置的
MaxCompute生产项目名称.表名的输出节点名作为上游节点输出名。本节点输出名称:单击代码解析输入输出按钮,会根据代码中的表名解析生成本节点生成
MaxCompute生产项目名称.表名格式的输出名,输出给下游节点。本案例其他必填配置项,您可按需自行配置,配置完成后,在节点代码编辑页面,单击工具栏中的
按钮,保存当前配置。
配置ads_user_info_1d_odps节点
在业务流程面板中,双击ads_user_info_1d_odps节点,编写SQL代码,对上游的dws_user_info_all_di_odps表进行加工处理,并将结果写入ads_user_info_1d_odps表中。
编辑代码。
-- 场景:以下SQL用于对用户访问信息宽表dws_user_info_all_di_odps进一步加工产出基本的用户画像数据写入ads_user_info_1d_odps表。 -- 补充:DataWorks提供调度参数,可实现调度场景下,将每日增量数据写入目标表对应业务分区。 -- 在实际开发场景下,您可通过${变量名}格式定义代码变量,并在调度配置页面通过为变量赋值调度参数的方式,实现调度场景下代码动态入参。 INSERT OVERWRITE TABLE ads_user_info_1d_odps PARTITION (dt='${bizdate}') SELECT uid , MAX(region) , MAX(device) , COUNT(0) AS pv , MAX(gender) , MAX(age_range) , MAX(zodiac) FROM dws_user_info_all_di_odps WHERE dt = '${bizdate}' GROUP BY uid;配置调度属性。
配置页面单击右侧调度配置,可进入调度配置面板配置调度与节点信息,详情可参见节点调度配置。以下为配置的内容:
配置项
配置内容
图示
调度参数
在调度参数配置参数:
参数名:
bizdate。参数值:
$[yyyymmdd-1]。
时间属性
调度周期:
日。定时调度时间:
00:30。重跑属性:运行成功或失败后皆可重跑。
其余参数保持默认即可。
说明当前节点每日起调时间由业务流程虚拟节点workshop_start的定时调度时间控制,即每日00:30后才会调度。
资源属性
选择准备环境阶段创建的Serverless资源组。
调度依赖
通过代码自动解析自动根据节点血缘关系配置节点上下游依赖关系,即将产出
dws_user_info_all_1d_odps表数据的dws_user_info_all_1d_odps节点设置为当前节点ads_user_info_1d_odps的上游。将节点产出表ads_user_info_1d作为节点输出,方便下游查询该表数据时自动挂上当前节点依赖。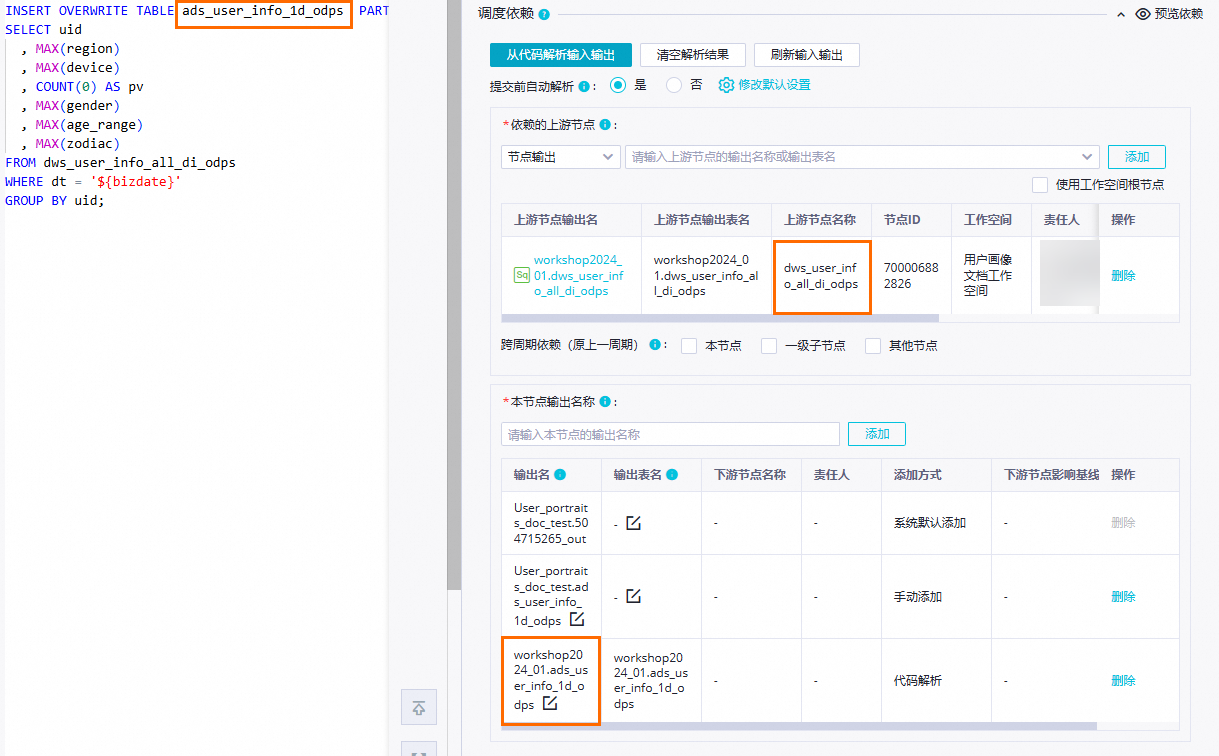 说明
说明依赖的上游节点:单击代码解析输入输出按钮,会根据代码中的表名解析到上游节点配置的
MaxCompute生产项目名称.表名的输出节点名作为上游节点输出名。本节点输出名称:单击代码解析输入输出按钮,会根据代码中的表名解析生成本节点生成
MaxCompute生产项目名称.表名格式的输出名,输出给下游节点。本案例其他必填配置项,您可按需自行配置,配置完成后,在节点代码编辑页面,单击工具栏中的
按钮,保存当前配置。
三、运行业务流程
运行业务流程
在数据开发页面,双击业务流程下的
用户画像分析_MaxCompute,打开Workflow业务流程面板后,单击工具栏中的 图标,按照上下游依赖关系运行业务流程。
图标,按照上下游依赖关系运行业务流程。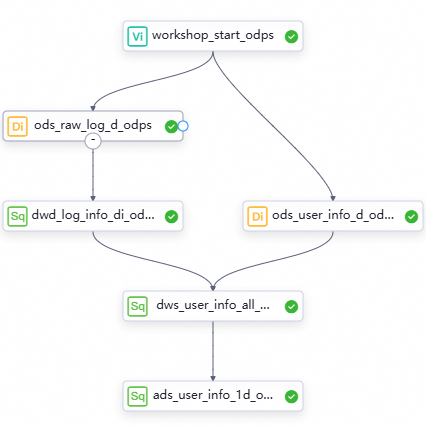
确认执行情况:
查看任务运行状态:节点处于
 状态,即代表同步执行过程无问题。
状态,即代表同步执行过程无问题。查看任务执行日志:右键单击节点,选择查看日志,即可查看开发环境下整个用户画像分析流程的各个节点日志。
查看同步结果
待所有任务处于![]() 状态后,查询最终加工的结果表。
状态后,查询最终加工的结果表。
您可在数据开发页面的左侧导航栏,单击
 ,进入临时查询面板。
,进入临时查询面板。右键单击临时查询,选择新建节点 > ODPS SQL。
在ODPS SQL节点中执行如下SQL语句,确认本案例最终的结果表。
//您需要将分区过滤条件更新为您当前操作的实际业务日期。例如,任务运行的日期为20230222,则业务日期为20230221,即任务运行日期的前一天。 select count(*) from ads_user_info_1d_odps where dt='业务日期';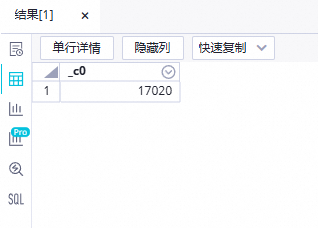 说明
说明本教程由于在DataStudio(开发环境)执行,所以该数据将默认写入开发环境对应的引擎项目workshop2024_01_dev的指定表中。
四、发布业务流程
任务需要发布至生产环境后才可自动调度运行,请参见以下内容。
提交至开发环境
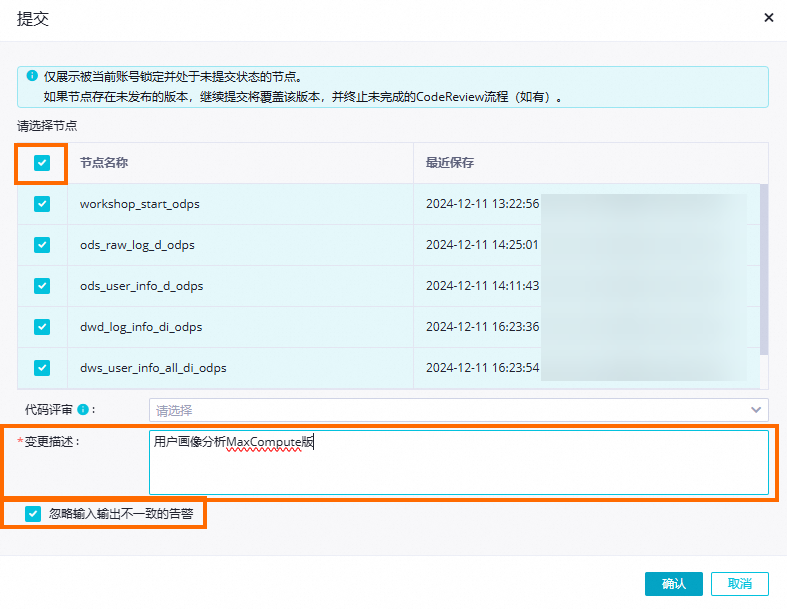
在业务流程面板工具栏中,单击 提交按钮,提交整个业务流程中的任务,请按照图示配置,并单击确认。
提交按钮,提交整个业务流程中的任务,请按照图示配置,并单击确认。
发布至生产环境
提交业务流程后,表示任务已进入开发环境。由于开发环境的任务不会自动调度,您需要将任务发布至生产环境。
在业务流程面板,单击工具栏中的
 图标,或单击数据开发页面任务发布按钮,进入创建发布包页面。
图标,或单击数据开发页面任务发布按钮,进入创建发布包页面。批量发布目标任务,包括该业务流程涉及的资源、函数。
五、运维调度
在实际开发场景下,您可通过在生产环境执行补数据操作实现历史数据回刷。本教程以补数据为例,为您展示运维调度操作,更多运维能力请参见:运维中心。
进入运维中心。
任务发布成功后,单击右上角的运维中心。
您也可以进入业务流程的编辑页面,单击工具栏中的前往运维,进入运维中心页面。
针对周期任务执行补数据操作。
在左侧导航栏,单击,进入周期任务页面,单击起始根节点
workshop_start_odps。右键单击
workshop_start_odps节点,选择。选
workshop_start_odps节点的所有下游节点,输入业务日期,单击确定,自动跳转至补数据页面。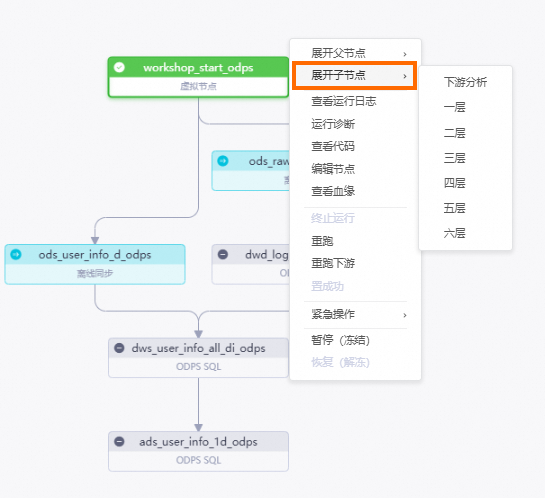
单击刷新,直至SQL任务全部运行成功即可。
后续步骤
在完成任务发布后,整个业务流程已经完成,即可查看已创建表详情或消费对应数据表,以及对数据配置质量监控,详情可参见:管理数据、API数据服务、数据可视化展现和监控数据质量。
附录:加工示例
加工前
58.246.10.82##@@2d24d94f14784##@@2014-02-12 13:12:25##@@GET /wp-content/themes/inove/img/feeds.gif HTTP/1.1##@@200##@@2572##@@http://coolshell.cn/articles/10975.html##@@Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.107 Safari/537.36加工后
