本文介绍如何通过控制台或手动迁移方式将自建ClickHouse迁移到云数据库 ClickHouse 企业版集群。
前提条件
自建集群:已创建数据库账号和密码,且账号权限需具备库表读权限、SYSTEM命令执行权限(如果需要迁移涉及账户密码的外表,要求账户有
displaySecretsInShowAndSelect权限)。网络连通性
如果自建集群和目标集群位于同一个VPC下,您还需要将目标集群所有节点的IP地址以及其交换机的IPv4网段,添加到自建集群的白名单中。
云数据库ClickHouse中如何添加白名单,请参见设置白名单。
自建集群如何添加白名单,请参见自身产品文档。
可通过
SELECT * FROM system.clusters WHERE internal_replication = 1;查看云数据库ClickHouse集群所有节点的IP地址。
如果自建集群和目标集群位于不同VPC,或自建集群位于本地IDC或其他云厂商时,请先解决网络问题,具体操作请参见如何解决目标集群与数据源网络互通问题?。
说明在此情况下,为避免不同VPC之间的网段冲突问题,可能会出现IP映射的情况,若您做了IP映射相关的操作,则映射后的IP也需要添加到两端集群的白名单中。
迁移验证
在您正式开始迁移数据前,强烈建议您创建一个测试环境,以验证业务的兼容性、性能以及迁移是否能够顺利完成。在迁移验证完成后,再在生产环境中进行数据迁移。这一步骤至关重要,它可以帮助您提前识别并解决潜在问题,确保迁移过程顺利,并且避免对生产环境造成不必要的影响。
创建迁移任务,进行数据迁移。
性能瓶颈分析以及是否能完成迁移。
上云兼容性验证提供两种方式:
手工验证,请参见兼容性分析与解决。
控制台验证,请参见(可选)检查SQL兼容性。
选择方案
迁移方案 | 优点 | 缺点 | 适用场景 |
控制台迁移 | 可视化操作,无需手动迁移元数据。 | 只能进行整集群数据的全量和增量迁移,无法仅迁移指定的部分库表或部分历史数据。 | 整个集群数据迁移。 |
手动迁移 | 可自主控制迁移哪些库表数据。 | 操作繁杂,需要手动迁移元数据。 |
|
操作步骤
控制台迁移
注意事项
迁移过程中
目标集群进行迁移的库表会暂停合并(Merge),但自建集群不会。
说明迁移数据时间过长,将会导致目标集群的元数据积累过多,建议迁移任务的持续时长不要超过5天。超过5天,任务将自动取消。
目标集群必须使用default集群。如果您自建集群的命名使用了其他名字,则会自动将分布式表中的cluster定义转化为default。
支持迁移的内容
部分引擎的库表结构在迁移时,会发生转换,迁移后的引擎信息请参见下方。
库结构:支持迁移的库引擎如下表所示。
引擎名
引擎转换说明
Atomic
Replaced with Replicated database
Replicated
无变化
Ordinary
Replaced with Replicated database
表结构:支持迁移的表引擎如下表所示。
引擎名
引擎转换说明
MaterializedView
无变化
View
GenerateRandom
Buffer
URL
Null
Merge
SharedMergeTree
SharedVersionedCollapsingMergeTree
SharedSummingMergeTree
SharedReplacingMergeTree
SharedAggregatingMergeTree
SharedCollapsingMergeTree
SharedGraphiteMergeTree
MergeTree
It will be replaced with SharedMergeTree
ReplicatedMergeTree
VersionedCollapsingMergeTree
It will be replaced with SharedVersionedCollapsingMergeTree
ReplicatedVersionedCollapsingMergeTree
SummingMergeTree
It will be replaced with SharedSummingMergeTree
ReplicatedSummingMergeTree
ReplacingMergeTree
It will be replaced with SharedReplacingMergeTree
ReplicatedReplacingMergeTree
AggregatingMergeTree
It will be replaced with SharedAggregatingMergeTree
ReplicatedAggregatingMergeTree
ReplicatedCollapsingMergeTree
It will be replaced with SharedCollapsingMergeTree
CollapsingMergeTree
GraphiteMergeTree
It will be replaced with SharedGraphiteMergeTree
ReplicatedGraphiteMergeTree
数据:增量迁移MergeTree族表的数据。
以上所示的库表结构能够正常迁移,其余库表结构需根据迁移过程中的警告、错误信息手动处理。
如果数据不满足以上条件,可选择手动迁移。
集群影响
自建集群
读取自建集群过程中,自建集群的CPU和内存使用率会升高。
不允许进行DDL操作。
目标集群
写入数据过程中,目标集群的CPU和内存使用率会升高。
迁移的库表不允许进行DDL操作,不需要迁移的库表没有此限制。
迁移中的库表停止merge,不需要迁移的库表不会停止merge。
迁移结束后,集群会持续一段时间高频merge操作,这会导致IO使用率上升,从而引起业务请求的延迟增加。建议您计算迁移结束后的merge时间,提前规划以应对业务请求延迟的潜在影响。
步骤一:检查自建集群并开启使用系统表system
在数据迁移之前,需要根据自建集群是否已启用system.part_log和system.query_log,对config.xml文件进行修改配置,以实现增量迁移。
未启用system.part_log和system.query_log
如果您未启用system.part_log和system.query_log,您需在config.xml文件中增加以下内容。
system.part_log
<part_log>
<database>system</database>
<table>part_log</table>
<partition_by>event_date</partition_by>
<order_by>event_time</order_by>
<ttl>event_date + INTERVAL 15 DAY DELETE</ttl>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
</part_log>system.query_log
<query_log>
<database>system</database>
<table>query_log</table>
<partition_by>event_date</partition_by>
<order_by>event_time</order_by>
<ttl>event_date + INTERVAL 15 DAY DELETE</ttl>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
</query_log>已启用system.part_log和system.query_log
您需根据下述内容,检查config.xml中
system.part_log和system.query_log的配置,如果存在不一致之处,需将其修改为以下配置,否则可能会导致迁移失败或迁移速度缓慢。system.part_log
<part_log> <database>system</database> <table>part_log</table> <partition_by>event_date</partition_by> <order_by>event_time</order_by> <ttl>event_date + INTERVAL 15 DAY DELETE</ttl> <flush_interval_milliseconds>7500</flush_interval_milliseconds> </part_log>system.query_log
<query_log> <database>system</database> <table>query_log</table> <partition_by>event_date</partition_by> <order_by>event_time</order_by> <ttl>event_date + INTERVAL 15 DAY DELETE</ttl> <flush_interval_milliseconds>7500</flush_interval_milliseconds> </query_log>修改配置后,您还需执行语句
drop table system.part_log和drop table system.query_log,在业务表插入数据后,会重新触发创建system.part_log和system.query_log。
步骤二:配置目标集群兼容自建集群版本
为确保目标集群与自建集群的行为尽可能兼容,需连接目标集群,修改compatibility参数,使目标集群与自建集群的版本号一致。
若将compatibility设置到低版本,会导致ParallelRepica等部分新特性失效。
示例如下:
SELECT currentProfiles(); //获取用户使用的profile
SELECT
profile_name,
setting_name,
value
FROM system.settings_profile_elements
WHERE (setting_name = 'compatibility') AND (profile_name = 'xxxx'); // 查询compatibility配置值
ALTER PROFILE XXXX SETTINGS compatibility = '23.8'; // 修改profile步骤三:创建迁移任务
登录云数据库ClickHouse控制台,在集群列表页面,选择企业版实例列表,并单击目标集群ID。
在左侧导航栏,单击。
单击创建迁移任务。
选择源及目标实例。
配置项
说明
示例
任务名称
迁移任务名称,只能由大小写英文字母和数字组成,且不允许重复,大小写不敏感。
MigrationTask1229
源实例cluster名称
通过
SELECT * FROM system.clusters;获取自建实例cluster名称。default
VPC IP地址
集群每个shard的IP和PORT地址,使用英文逗号隔开。格式:
IP:PORT,IP:PORT,....您可以使用以下SQL获取自建集群的IP和PORT:
SELECT shard_num, replica_num, host_address as ip, port FROM system.clusters WHERE cluster = '<cluster_name>' and replica_num = 1;参数说明:
cluster_name:目标集群的名字。
replica_num=1表示选择第一个副本集,也可以选择其他副本集或者自行挑选每个shard的一个副本组成。
重要不能使用ClickHouse的VPC域名地址或者SLB地址。
如果IP和端口发生转换后映射到阿里云,则需要根据网络打通情况配置对应的IP和PORT。
192.168.0.5:9000,192.168.0.6:9000
数据库账号
自建集群数据库账号。
test
数据库密码
自建集群数据库账号密码。
test******
源实例内核版本
单击获取版本。
22.8.5.29
根据获取到的源实例版本信息,执行对应操作:
源实例版本大于等于22.10:单击下一步。
源实例版本小于22.10:根据提示填写目标实例信息,单击下一步。
获取版本失败:源实例信息填写错误、网络未打通等情况会导致获取版本失败,请根据提示信息处理后,重新单击获取版本。
说明由于低版本社区版与企业版之间存在参数不兼容的问题,当源实例版本低于22.10时,需要通过源端向目的端推送数据的方式进行同步。在这种情况下,需要将目的端的IP映射至自建网络。如果自建网络与企业版实例处于同一 VPC,或双方网络已通过VPC对等连接连通,则可直接使用原有IP地址进行连接。
检查连通性和配置。
单击开始检查。
检查过程中可以单击右上角的
 实时查看检查进度。
实时查看检查进度。检查完成后,请根据检查结果,完成后续操作。
您可以选择结果级别与检查项,然后单击
按钮,查看对应的检查结果,检查结果说明如下。成功:若所有检查项均通过,单击下一步继续操作。
警告:非强制卡点项,需自行确认该警告项是否会对业务和迁移任务造成影响。您可选择忽略告警,或根据告警内容处理对应的告警项后,再次单击开始检查,重新检查连通性与配置。
错误:强制卡点项,需根据错误内容处理对应的错误项后,再次单击开始检查,重新检查连通性与配置。
检测报错信息以及解决方案,请参见常见问题。
检查库表结构。
单击开始检查。
检查过程中可以单击右上角的
实时查看检查进度。检查完成后,请根据检查结果,完成后续操作。
检查结果说明请参见步骤5。
库表结构迁移。
单击开始迁移。
迁移过程中可以单击右上角的
实时查看迁移进度。检查完成后,请根据检查结果,完成后续操作。
检查结果说明请参见步骤5。
(可选)检查SQL兼容性。
SQL兼容性检查通过在目标实例上对自建实例的SQL语句进行回放,来验证不同内核版本的语法兼容性,请您根据自身需求,决定是否需要执行此步骤。
无需执行,则单击跳过。
若需要执行,需选择请求重放时间后,再单击开始检查。检查通过后单击下一步,检查不通过时的处理方法请参见步骤5。
重要实例库表无数据,仅提供验证语法兼容性的能力。如果需要有数据,可先执行下一步骤迁移部分数据。
由于回放SQL的客户端版本和目标实例不匹配,可能存在误报。针对异常情况,您可以自行执行SQL验证。
启动同步。
单击开始同步。
同步过程中可以单击右上角的
实时查看同步进度。当执行到迁移数据时,切换到迁移数据页签,单击
按钮查看迁移进度及预估剩余时间。重要您需重点监控目标任务的迁移进度,根据预估剩余时间,主动停写自建集群并处理Kafka和RabbitMQ引擎表。
当迁移进度为100%,且确认源端实例已经进入停写状态后,需要您单击停止按钮结束迁移流程,执行后续流程。
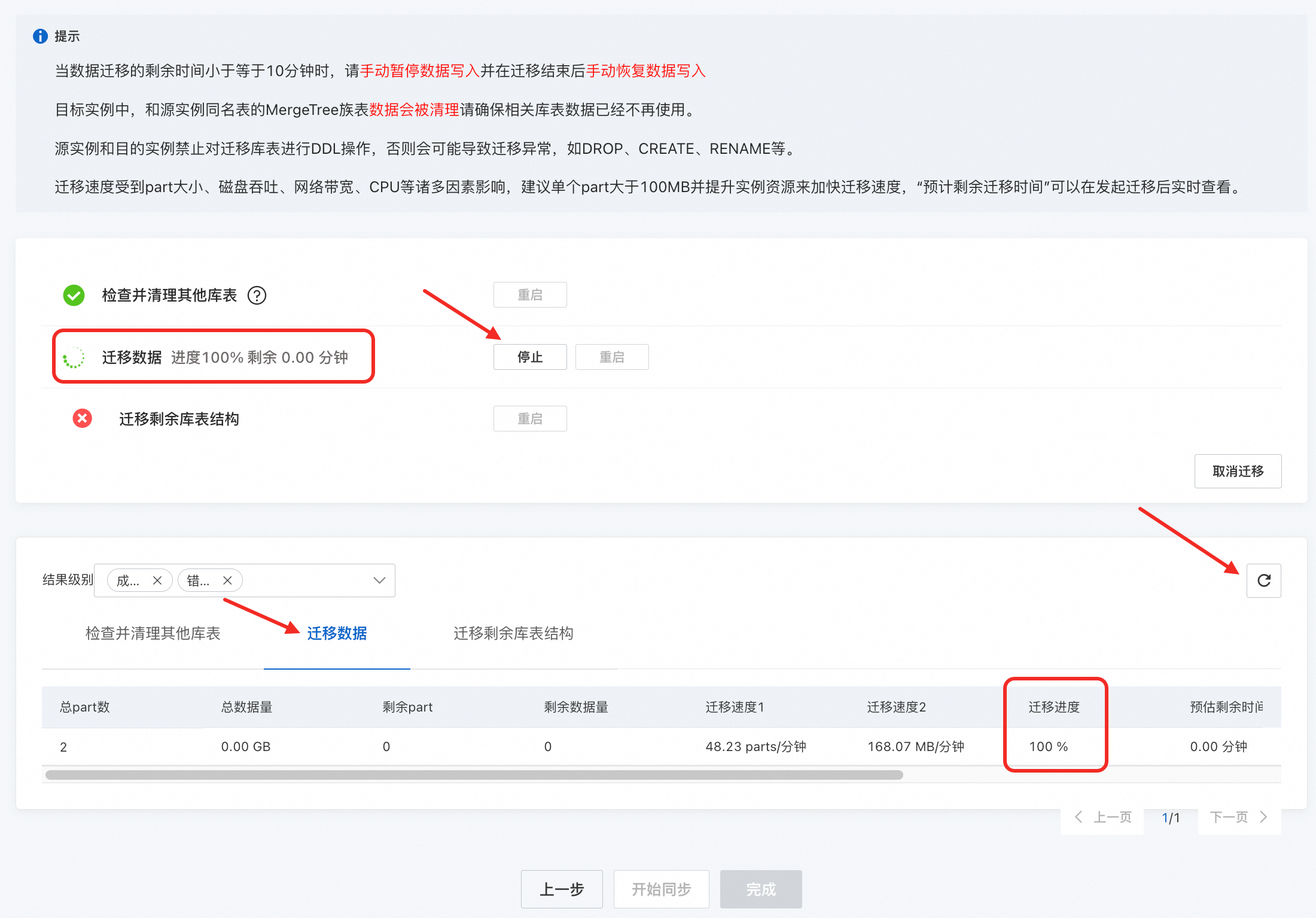
同步完成后单击完成。
重要当“启动同步”步骤完成后,该迁移任务将被锁定,即不允许修改迁移流程,您可通过上一步、下一步或刷新按钮查看迁移步骤执行结果。
步骤四:迁移非MergeTree类型表的业务数据
迁移任务中,非MergeTree类型的表仅支持迁移表结构(例如MySQL表)或者不支持迁移(例如Log表)。因此,迁移任务完成后,目标集群可能存在只有表结构,没有具体的业务数据的表,您需自主完成业务数据迁移,具体操作如下:
登录自建集群,查看需要迁移数据的非MergeTree类型的表。
SELECT `database` AS database_name, `name` AS table_name, `engine` FROM `system`.`tables` WHERE (`engine` NOT LIKE '%MergeTree%') AND (`engine` != 'Distributed') AND (`engine` != 'MaterializedView') AND (`engine` NOT IN ('Kafka', 'RabbitMQ')) AND (`database` NOT IN ('system', 'INFORMATION_SCHEMA', 'information_schema')) AND (`database` NOT IN ( SELECT `name` FROM `system`.`databases` WHERE `engine` IN ('MySQL', 'MaterializedMySQL', 'MaterializeMySQL', 'Lazy', 'PostgreSQL', 'MaterializedPostgreSQL', 'SQLite') ))登录目标集群,通过remote函数执行数据迁移。
手动迁移
从自建ClickHouse向企业版迁移
在云数据库 ClickHouse 企业版中,无论您的源表是否存在分片或副本,您只需创建对应的目标表即可(在该表中,您可以省略Engine参数,因为系统将自动使用SharedMergeTree表引擎)。云数据库 ClickHouse 企业版集群会自动处理垂直和水平扩展,您无需担心复制和分片的具体实现方式。
操作概述
从自建ClickHouse向云数据库 ClickHouse 企业版集群迁移的流程如下。
在源集群中添加一个只读用户。
在目标集群上复制源表结构。
如果源集群支持从外部网络访问时,您可以将源集群数据读取至目标集群;如果源集群不支持从外部网络访问时,您可以将源集群数据推送至目标集群。
(可选)在目标集群上将源集群的IP地址删除。
从源集群中删除只读用户。
操作步骤
在源集群上执行以下操作(源表中已有数据):
增加一个只读用户到表db.table中。
CREATE USER exporter IDENTIFIED WITH SHA256_PASSWORD BY 'password-here' SETTINGS readonly = 1;GRANT SELECT ON db.table TO exporter;复制源表结构。
SELECT create_table_query FROM system.tables WHERE database = 'db' and table = 'table'
在目标集群上执行以下操作。
创建数据库。
CREATE DATABASE db使用源数据表的
CREATE TABLE语句来创建目标数据表。说明在运行
CREATE TABLE语句时,将ENGINE更改为SharedMergeTree,但是不能包含任何参数,因为云数据库 ClickHouse 企业版集群始终会复制表并提供正确的参数。ORDER BY、PRIMARY KEY、PARTITION BY、SAMPLE BY、TTL和SETTINGS子句定义了表的结构和元数据信息,请保留这些子句,以确保表在目标云数据库 ClickHouse 企业版集群中正确地创建。CREATE TABLE db.table ...使用
Remote函数读取数据或推送数据。说明如果源ClickHouse服务器不可从外部网络访问,您可以选择将数据推送而不是读取,因为
Remote函数适用于选择和插入操作。在目标集群中使用
Remote函数从源集群的源表中读取数据。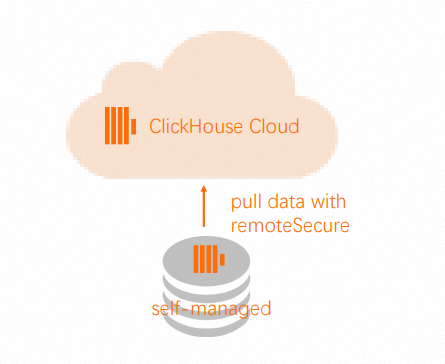
INSERT INTO db.table SELECT * FROM remote('source-hostname:9000', db, table, 'exporter', 'password-here')在源集群中使用
Remote函数将数据推送到目标集群中。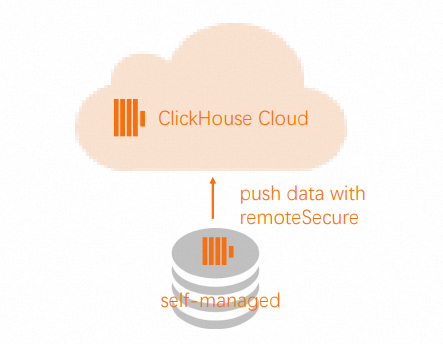 说明
说明为了使
Remote函数能够连接到您的云数据库 ClickHouse 企业版集群上,您需要将源集群的IP地址添加到目标集群的白名单中。具体操作,请参见设置白名单。INSERT INTO FUNCTION remote('target-hostname:9000', 'db.table', 'default', 'PASS') SELECT * FROM db.table
常见问题
检查连通性与配置中的报错信息及解决方案
报错信息 | 含义 | 解决方案 |
| 自建集群网络连接超时。 | 根据报错信息,排查网络问题。 |
| 自建集群中不存在创建迁移任务时配置的cluster。 | 通过SQL查询自建集群的cluster,并修改迁移任务的配置。 |
| 自建集群不存在 | 在自建集群创建对应的系统表。 |
| 自建集群与目标集群时区不匹配。 | 修改时区,使其匹配。 |
| 目标集群compatibility配置与自建集群版本不一致。 | 调整目标集群compatibility配置,使其与自建集群版本一致。 重要 若将compatibility设置到低版本,会导致ParallelReplica等部分新特性失效。 |
检查库表结构中的报错信息及解决方案
报错信息 | 含义 | 解决方案 |
| 在自建集群中,不同节点之间的数据库表不一致。 | 检查自建集群各节点上的库表,解决不一致问题。 |
| 库表密码不可见。 | 设置display_secrets_in_show_and_select=1,并重启。 注意:此操作要求账号拥有displaySecretsInShowAndSelect权限。 |
| 自建集群的库引擎不支持迁移。 | 考虑更换目的端支持的库引擎。 |
| 自建集群的库引擎不支持迁移。 | 后台自动替换为Replicated数据库,以绕过迁移异常。 |
| 自建集群的库引擎不支持迁移。 | 请使用DTS(数据传输服务)替代同步功能,或创建同名数据库以绕过迁移异常。 |
| 自建集群的库引擎不支持迁移。 | 在迁移过程中自动被忽略。 |
| 云数据库 ClickHouse 企业版不建议使用分布式表。 | 在自建集群删除分布式表,迁移后直接查询MergeTree表。 |
| 引用外部引擎,可能存在无法访问的问题,但并不一定存在问题。 | 需要您自行确认所引用的IP地址在目标实例是否可以访问。若无法访问,则需要打通网络连接,并加白IP地址。 |
| 部分引擎的表只会迁移表结构,不支持迁移数据。 | 需要您通过remote函数等方式自行迁移数据 |
| 部分引擎的表不支持迁移。 | 需要客户在目标端创建同名的MergeTree表,并自行迁移数据。 |
| 部分引擎的表不支持迁移。 | 请参见操作步骤中的步骤四。 |
| 检查库表结构时,对应的表在目标实例应为空表,不能有数据。 | 删除目标实例对应表的数据。 |
| 只支持迁移客户自定义的 | 自行在目标实例中创建对应的function。 |
其他
迁移过程中的其他问题及解决方法请参见常见问题。