服务网格 ASM(Service Mesh)支持为特定服务之间和特定路由上的东西向调用流量配置熔断规则,通过配置使网格代理主动拒绝出现故障上游服务的请求,实现无侵入式的流量熔断能力。本文介绍如何使用ASMCircuitBreaker CRD为东西向调用流量配置熔断规则。
背景信息
流量熔断是一种过载保护机制,主要用于防止系统因为短时间内过大的流量而崩溃。在云原生服务之间存在东西向调用流量的情况下,如果某个服务发生故障(例如:响应过慢或者失败率升高),可能会导致该服务所在调用链路上的一系列服务也发生连锁崩溃。
通过为服务间的东西向调用流量配置熔断规则,可以实现当流量失败率或响应超时次数达到阈值时,主动“切断”来自上游服务的请求。在保护上游服务的同时,也有效防止故障在整个调用链路中扩散,造成整个系统雪崩。
配置熔断规则后,每个网格代理将基于其代理的请求分别计算流量失败率或响应超时次数。因此,对于同一个发生故障的上游服务、客户端网格代理发生熔断的时机可能略有不同。
前提条件
已创建ASM专业版实例,且版本为v1.14.3及以上。具体操作,请参见创建ASM实例。
已完成sleep和httpbin示例应用的部署。具体操作,请参见在数据面集群中部署httpbin应用和在数据面集群部署sleep服务。
步骤一:为服务调用的东西向调用流量配置请求路径路由
登录ASM控制台,在左侧导航栏,选择。
选择下方两种方式的任意一种配置虚拟服务。
控制台手动创建
在网格管理页面,单击目标实例名称,然后在左侧导航栏,选择,然后单击创建。
填写命名空间和服务名称,打开作用范围>作用于所有Sidecar。
在所属服务框中单击添加所属服务,添加httpbin服务。
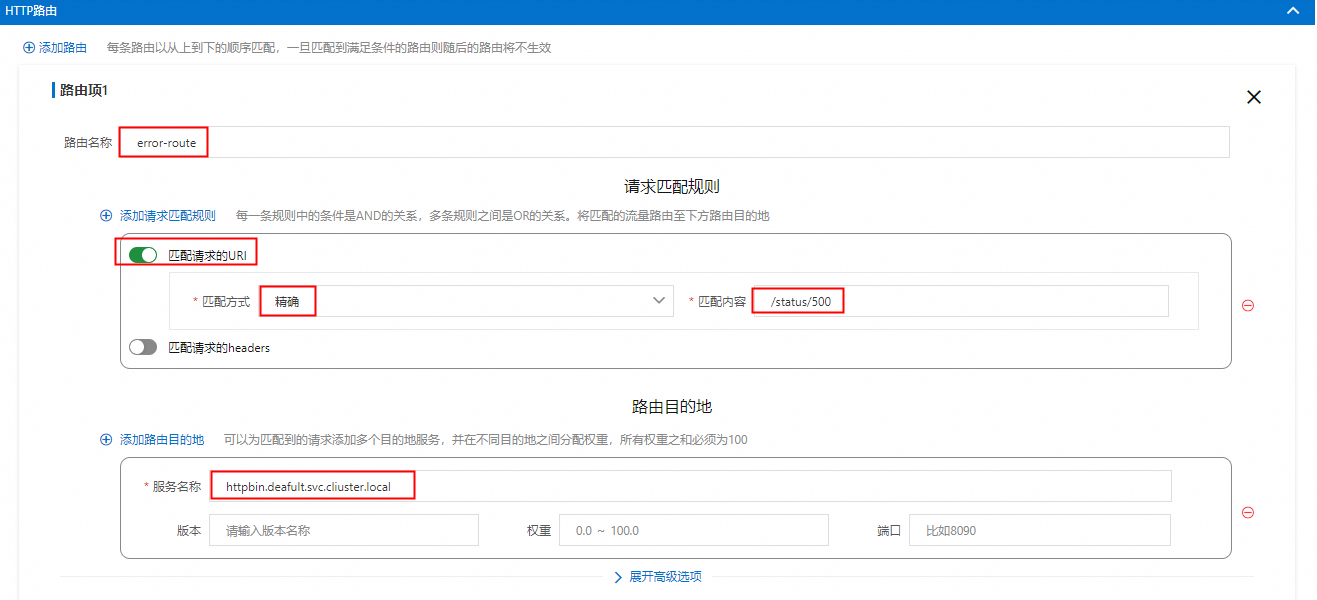
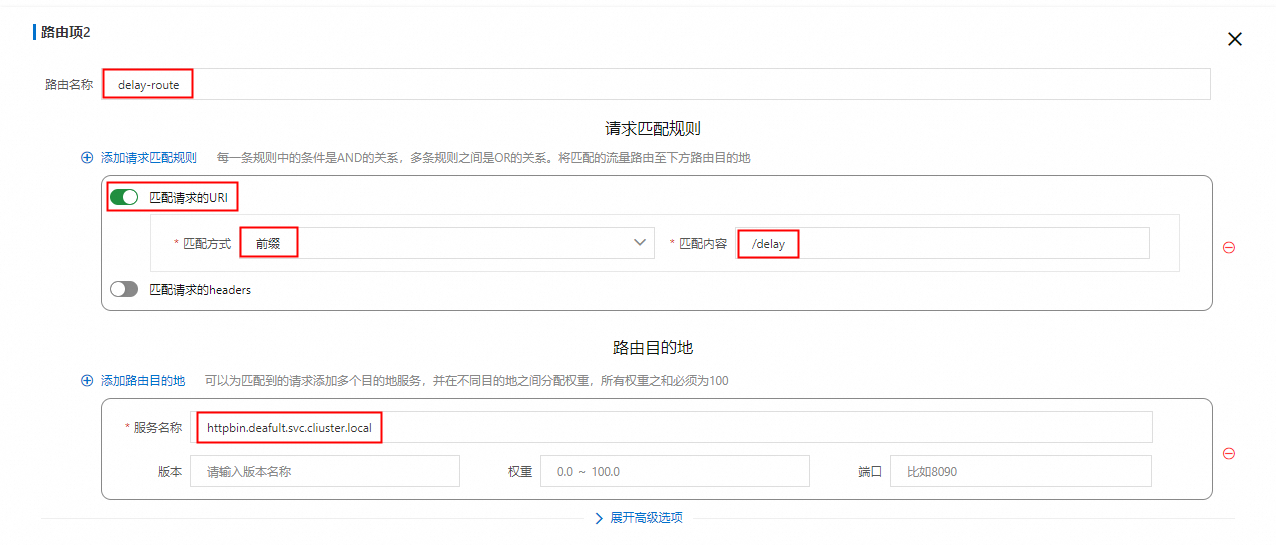
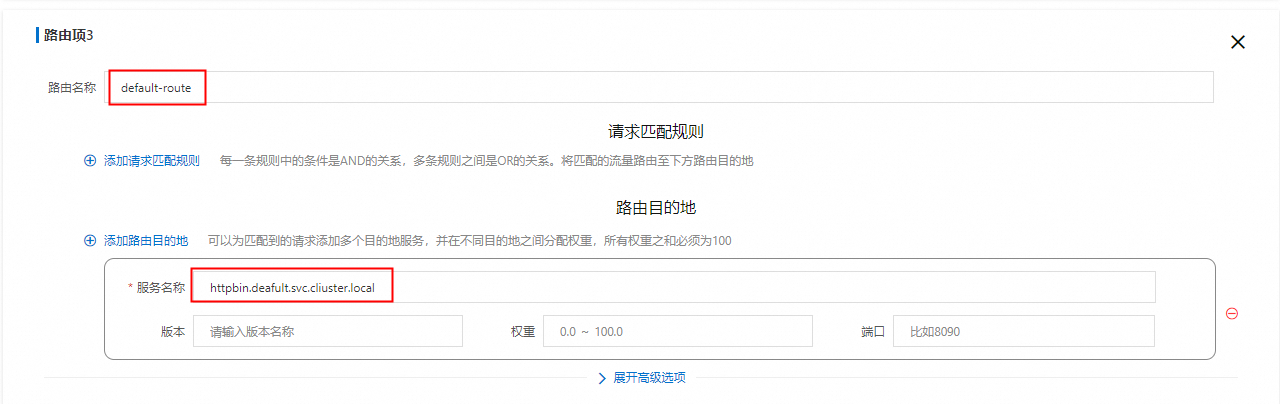
配置HTTP路由>添加路由,信息填写请参见下图红框标注。
使用YAML创建
在网格管理页面,单击目标实例名称,然后在左侧导航栏,选择,然后单击使用YAML创建。
在YAML输入框中输入如下内容,点击创建。
下表为请求与路径的对应关系以及具体说明。
请求路径
匹配类型
路由项
说明
/status/500精确匹配
error-route固定响应500状态码。
/delay前缀匹配
delay-route指定的时间后响应200状态码;/delay请求的具体使用方法参见delay。
/*任意路径
default-route默认路由项。
步骤二:配置熔断
本节将分别介绍错误率熔断和慢请求熔断的具体配置步骤以及测试结果。
基于错误率熔断
基于错误率的熔断是指在给定的时间窗口内检测服务器响应的错误率,并在错误率超过一定阈值时触发熔断。
登录ASM控制台,在左侧导航栏,选择。
在网格管理页面,单击目标实例名称,然后在左侧导航栏,选择。
在创建页面,在YAML输入框处输入以下内容,然后单击创建。
熔断配置中使用的参数说明如下:
参数
说明
workloadSelector.labels
熔断配置的下游服务工作负载,在本例中是sleep服务,因此用
app: sleep标签选中该工作负载。break_duration
熔断发生后到恢复对服务访问之间的时长。本例中配置为60s。
window_size
进行熔断检测的时间窗口。本例中配置为10s,代表在10秒内若路由中的请求错误率超过指定阈值,则开始熔断,拒绝请求。
error_percent
在时间窗口内,判断是否达到熔断所需的请求错误率。本例中配置为60,代表在时间窗口的10s内若路由中的请求错误率超过60%,则发生熔断,拒绝请求。
min_request_amount
时间窗口内触发熔断所需的最小请求数。配置该参数的目的是防止因请求量过小而误判触发熔断。
本例中配置为5,代表在时间窗口的10s内若路由已经发送了5次以上请求,且错误率超过60%时,才发生熔断。
custom_response
熔断发生时,网格代理拒绝请求时返回的自定义响应内容。
body配置为
error break!,代表响应体为error break!header_to_add配置为
x-envoy-overload: 'true',代表熔断的响应头中将添加x-envoy-overload: 'true'status_code配置为
499,代表熔断后请求的响应码为499。
match.vhost
熔断的路由条目配置,该路由条目必须与虚拟服务中声明的具体路由条目匹配。
name:需要配置为调用链路中的上游服务服务域名。在本例中,配置为sleep服务的上游服务httpbin服务的域名
httpbin.default.svc.cluster.local。port:需要配置为上游服务的Service端口。在本例中,配置为httpbin服务的Service端口
8000。route.name_match:需要配置为虚拟服务中实际的路由项名称,熔断配置将在该段路由中生效。在本例中,配置为步骤二中编写的路由项
error-route,此路由项对应的请求将固定响应500状态码,确保能够触发熔断。
使用kubectl连接ACK集群,执行以下命令。
for i in {1..100}; do kubectl exec -it deploy/sleep -- curl httpbin:8000/status/500 -I | grep 'HTTP'; echo ''; sleep 0.1; done;预期输出:
可以看到,当发送第6条请求时,熔断被触发,可以观察到后续请求都返回自定义的499响应码,熔断将持续60s。
在熔断期间,可以尝试对httpbin服务的其他路径进行访问。
for i in {1..100}; do kubectl exec -it deploy/sleep -- curl httpbin:8000/status/503 -I | grep 'HTTP'; echo ''; sleep 0.1; done;预期输出:
可以看到发往服务其他路径的请求并不受
error-route路由项上的熔断配置影响,仍然可以正常返回httpbin服务的响应内容。
基于慢请求熔断
基于慢请求数的熔断是指检测在给定的时间窗口内响应时间超过给定阈值的请求数量(这种请求被称作慢请求),并在慢请求数量超过一定阈值时触发熔断。
登录ASM控制台,在左侧导航栏,选择。
在网格管理页面,单击目标实例名称,然后在左侧导航栏,选择。
在创建页面,在YAML输入框中输入以下内容,然后单击创建。
熔断配置中使用的参数说明如下:
参数
说明
workloadSelector.labels
熔断配置的下游服务工作负载,在本例中是sleep服务,因此用
app: sleep标签选中该工作负载。break_duration
熔断发生后到恢复对服务访问之间的时长。本例中配置为60s。
window_size
进行熔断检测的时间窗口。本例中配置为10s,代表在10秒内若路由中慢请求数量超过指定阈值,则发生熔断,拒绝请求。
slow_request_rt
慢请求的判断基准响应时间。本例中配置为0.5s,代表响应时间超过0.5s的请求将被视作慢请求。
max_slow_requests
时间窗口内触发熔断所需的慢请求数量。本例中配置为5,代表时间窗口的10s内若出现了超过5次慢请求,则发生熔断,拒绝请求。
min_request_amount
时间窗口内触发熔断所需的最小请求数量。配置该参数的目的是防止因请求量过小而被误判触发熔断。
本例中配置为5,代表在时间窗口的10s内若路由上已经发送了5次以上请求、且慢请求数超过5时,才会发生熔断。
custom_response
熔断发生时,网格代理拒绝请求时返回的自定义响应内容。
body配置为
delay break!,代表响应体为delay break!header_to_add配置为
x-envoy-overload: 'true',代表熔断的响应头中将添加x-envoy-overload: 'true'status_code配置为
498,代表熔断后请求的响应码为498。
match.vhost
熔断的路由条目配置,该路由条目必须与虚拟服务中声明的具体路由条目匹配。
name:需要配置为调用链路中上游服务的服务域名。在本例中,配置为sleep服务的上游服务httpbin服务的域名
httpbin.default.svc.cluster.local。port:需要配置为上游服务的Service端口。在本例中,配置为httpbin服务的Service端口
8000。route.name_match:需要配置为虚拟服务中实际配置的路由项名称,熔断配置将在该段路由中生效。在本例中,配置为步骤二中编写的路由项
delay-route,此路由项对应的请求能够以人工方式指定超过0.5秒响应,确保能够触发熔断。
使用kubectl连接ACK集群,执行以下命令。
for i in {1..100}; do kubectl exec -it deploy/sleep -- curl httpbin:8000/delay/1 -I | grep 'HTTP'; echo ''; sleep 0.1; done;预期输出:
可以看到,当发送第6次请求时,熔断被触发。可以观察到后续的请求都返回了自定义498响应码,熔断将持续60s。
在熔断触发期间,可以执行以下命令对步骤三中配置的基于错误率的熔断进行测试。
for i in {1..100}; do kubectl exec -it deploy/sleep -- curl httpbin:8000/status/500 -I | grep 'HTTP'; echo ''; sleep 0.1; done;预期输出:
上述输出说明在不同路由项上配置的熔断规则彼此之间互不影响,您可以灵活地针对服务之间不同特征的东西向调用流量配置各自的熔断规则,灵活地实现流量熔断策略。
相关操作
查看服务级熔断相关指标
在1.22.6.28及以上的ASM版本中,您可以查看和使用ASMCircuitBreaker的服务级熔断相关指标。
指标 | 指标类型 | 描述 |
envoy_asm_circuit_breaker_total_broken_requests | Counter | 被ASMCircuitBreaker熔断的请求总数。 |
您可以通过配置Sidecar代理的proxyStatsMatcher来上报相关指标。
在配置proxyStatsMatcher时,选中正则匹配,配置为
.*circuit_breaker.*。具体操作,请参见proxyStatsMatcher。重新部署httpbin应用,使新的代理配置生效。具体操作,请参见重新部署工作负载。
执行以下命令,查看httpbin服务的服务级熔断相关指标。
kubectl exec -it deploy/httpbin -c istio-proxy -- curl localhost:15090/stats/prometheus|grep asm_circuit_breaker预期输出:
# TYPE envoy_asm_circuit_breaker_total_broken_requests counter envoy_asm_circuit_breaker_total_broken_requests{cluster="outbound|8000||httpbin.default.svc.cluster.local",uuid="af7cf7ad-67e8-49c5-b5fe-xxxxxxxxx"} 1430 # TYPE envoy_total_asm_circuit_breakers gauge envoy_total_asm_circuit_breakers{} 1
配置服务级熔断指标采集及告警
配置完成上报服务级熔断指标后,您可以配置采集相关指标到Prometheus,并基于关键指标配置告警规则,实现熔断发生时的及时告警。以下以可观测监控Prometheus版为例说明如何配置服务级熔断指标采集和告警。
在可观测监控Prometheus版中,为数据面集群接入阿里云ASM组件或升级至最新版,以保证可观测监控Prometheus版可以采集到暴露的熔断指标。关于接入组件的具体操作,请参见接入组件管理。(如果您已经集成自建Prometheus实现网格监控来采集服务网格指标,则无需做额外操作。)
创建针对服务级熔断的告警规则。具体操作,请参见通过自定义PromQL创建Prometheus告警规则。配置告警规则的关键参数的填写示例如下,其余参数可参考上述文档根据实际需求填写。
参数
示例
说明
自定义PromQL语句
(sum by(cluster, namespace) (increase(envoy_asm_circuit_breaker_total_broken_requests[1m]))) > 0
查询最近1分钟之内熔断的请求数量,并根据触发熔断的服务所在命名空间以及服务名称进行分组。当1分钟内被熔断的请求数量大于0时触发告警。
告警内容
发生服务级熔断!命名空间:{{$labels.namespace}},发生熔断的目标服务:{{$labels.cluster}}。当前1分钟内熔断的请求数量:{{ $value }}
展示了触发熔断的服务所在命名空间以及服务名称,以及最近1分钟内发往该服务被熔断的请求数量的告警信息格式。