服务网格 ASM(Service Mesh)会为所有流入、流出及网格内部的服务流量生成指标,以便监控服务行为。这些指标包括总流量数、错误率和请求响应时间等信息。然而,长时间运行会生成大量的指标数据,显著增加了Envoy和Prometheus的资源消耗。为此,ASM提供了定期清理监控指标的配置,支持定期清理Envoy中缓存的一段时间内未使用的指标,以减少Envoy内存消耗,并降低Prometheus拉取指标时的网络负载。本文将介绍如何配置定期清理功能及其应用实例。
前提条件
已添加集群到ASM实例,且实例版本在1.18及以上。具体操作,请参见添加集群到ASM实例。
配置方式
登录ASM控制台,在左侧导航栏,选择。
在网格管理页面,单击目标实例名称,然后在左侧导航栏,选择。
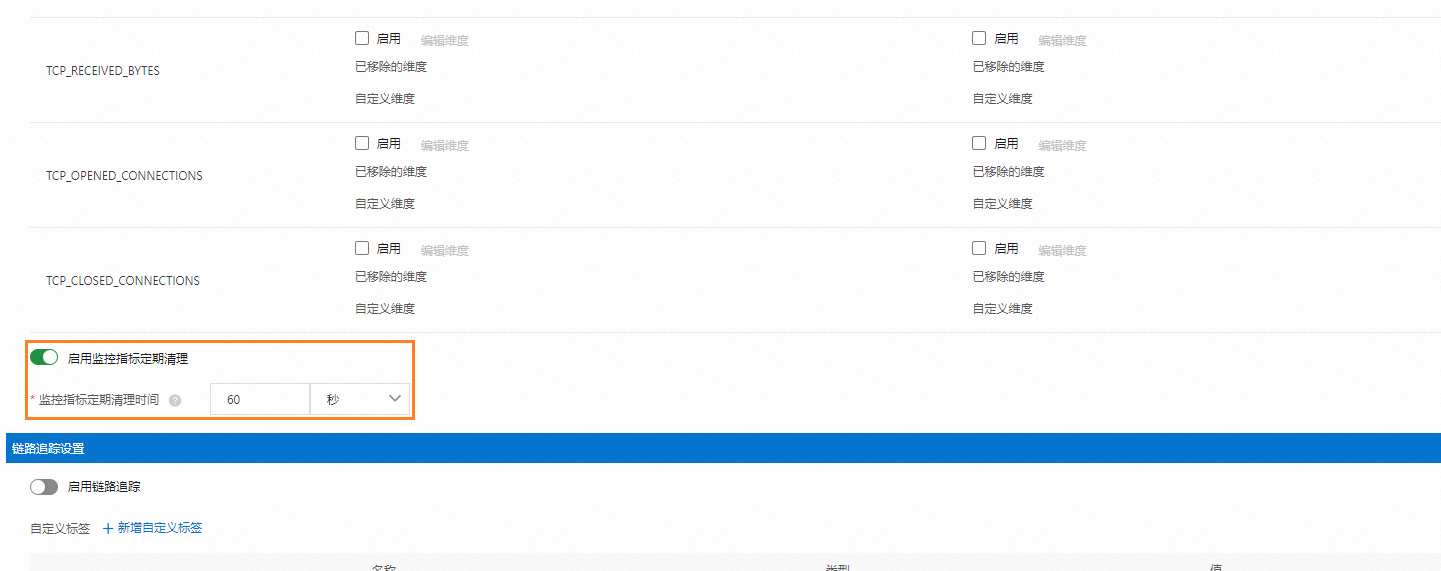
在可观测配置页面,单击全局页签,在监控指标设置处输入定期清理时间,然后单击提交。
 重要
重要建议监控指标定期清理时间至少设为Prometheus指标抓取时间
scrape_interval的两倍,以确保在指标清理之前Prometheus能够成功地抓取指标。
示例演示
部署示例应用
使用以下内容在数据面集群部署示例应用。具体操作,请参见创建无状态工作负载Deployment或使用YAML创建。
执行以下命令,查看应用状态,
kubectl get pod预期输出:
NAME READY STATUS RESTARTS AGE httpbin-846bxxx694-xxxxx 2/2 Running 0 44s sleep-866xxx97f9-xxxxx 2/2 Running 0 44s
启用指标并测试
登录ASM控制台,在左侧导航栏,选择。
在网格管理页面,单击目标实例名称,然后在左侧导航栏,选择。
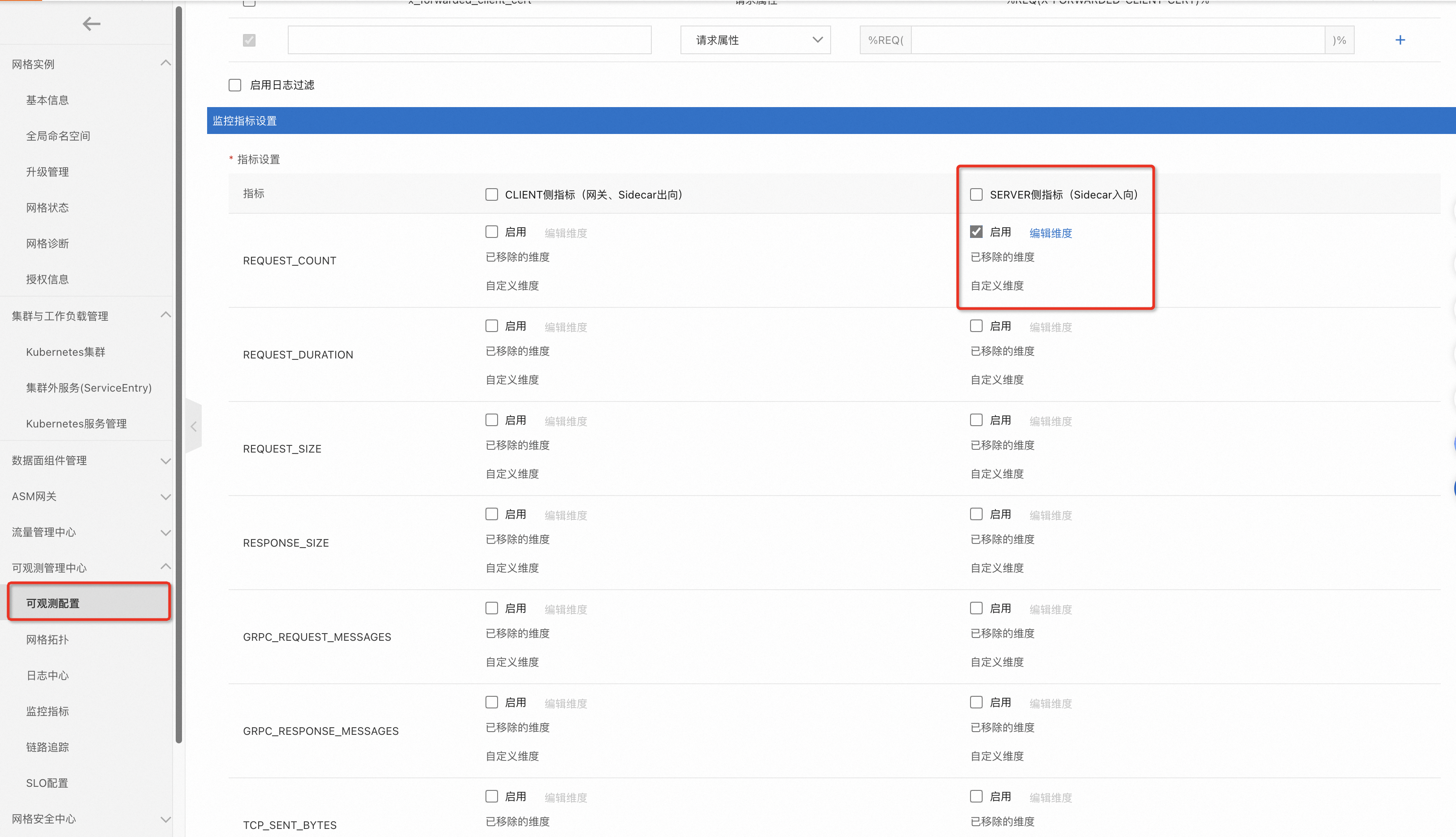
在可观测配置页面,单击全局页签,在监控指标设置列表中,勾选SERVER侧指标的REQUEST_COUNT指标的启用。然后单击提交。
执行以下命令,访问httpbin应用。
kubectl exec -it deploy/sleep -- sh -c 'for i in $(seq 1 10); do curl -s httpbin:8000/status/418 > /dev/null; done'执行以下命令,查看httpbin应用的监控指标。
kubectl exec -it deploy/httpbin -c istio-proxy -- curl 0.0.0.0:15020/stats/prometheus | grep istio_requests_total{预期输出:
istio_requests_total{reporter="destination",source_workload="sleep",source_canonical_service="sleep",...,request_protocol="http",response_code="418",grpc_response_status="",response_flags="-",connection_security_policy="mutual_tls"} 20
配置监控指标定期清理
根据配置方式中的步骤,配置监控指标定期清理时间为10s。
指标清理会有几秒的延迟,验证过程中,您可以视情况适当调整清理时间。
配置完成后,执行以下命令,查看httpbin应用的监控指标。
kubectl exec -it deploy/httpbin -c istio-proxy -- sh -c ' for i in $(seq 1 2); do echo "# Current content of the istio_requests_total metric: "; curl -s 0.0.0.0:15020/stats/prometheus | grep istio_requests_total{; sleep 15; done'预期输出:
# Current content of the istio_requests_total metric: istio_requests_total{reporter="destination",source_workload="sleep",source_canonical_service="sleep",...connection_security_policy="mutual_tls"} 30 # Current content of the istio_requests_total metric:以上测试命令共发送2次请求。在清理之前,每次请求都会返回一行指标内容输出和一行自定义输出;15s后指标数据已经被清理,每次请求的返回变为只有一行自定义输出。