为Java应用安装探针后,ARMS即可开始监控Java应用,您可以在实例监控页面了解应用的基础监控、实例GC和JVM内存等信息。
前提条件
ARMS应用监控面向已开通新版计费的用户提供全新的监控详情页面,新版计费详情,请参见产品计费(新版)。
对于未开通新版计费的用户,如需查看新版监控详情页面,可在应用列表页面单击切换新版。
已为应用安装探针,具体操作,请参见应用监控接入概述。
查看实例监控
登录ARMS控制台,在左侧导航栏选择。
在应用列表页面顶部选择目标地域,然后单击目标应用名称。
说明语言列的图标含义如下:
 :接入应用监控的Java应用。
:接入应用监控的Java应用。 :接入应用监控的Golang应用。
:接入应用监控的Golang应用。 :接入应用监控的Python应用。
:接入应用监控的Python应用。-:接入可观测链路 OpenTelemetry 版的应用。
在上方导航栏单击实例监控。
页面说明
实例监控页面会根据应用接入的信息自动适配展示大盘,并针对ECS环境和容器环境做区别展示。
在容器场景下,如果已经接入可观测监控 Prometheus 版,则优先以可观测监控 Prometheus 版数据作为容器信息的展示。容器环境接入可观测监控 Prometheus 版的操作,请参见容器可观测。
容器环境如果未接入可观测监控 Prometheus 版,需要确保应用监控探针版本在4.1.0或以上,对应数据展示容器的基础信息。应用监控探针说明,请参见探针(Java Agent)版本说明。
ECS环境
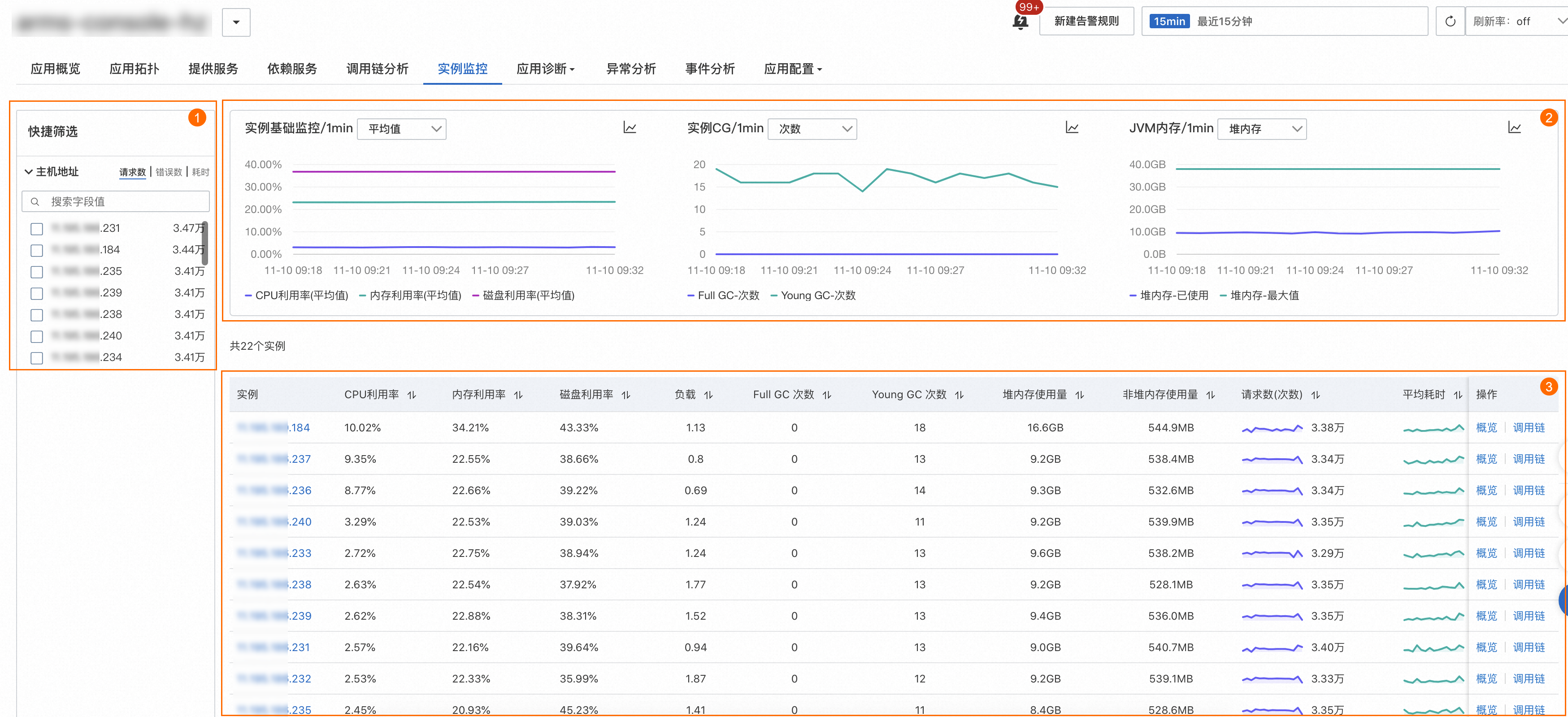
在快捷筛选区域(图示①),您可以按主机地址对图表、实例列表进行筛选。
在趋势图区域(图示②),您可以查看实例的基础监控、实例GC和JVM内存的时序曲线。
基础监控:应用在指定时间范围内CPU、内存和磁盘使用率趋势图。通过图标名称右侧的下拉框可以切换展示各使用率的平均值和最大值。
实例GC:应用在指定时间范围内Full GC和Young GC的趋势图。通过图表名称右侧的下拉框可以切换展示GC的次数和平均耗时。
JVM内存:应用在指定时间范围内堆内存已使用和最大值趋势图。通过图标名称右侧的下拉框可以切换展示非堆内存已使用和最大值趋势图。
说明ARMS应用监控采集的数据来自JMX,其中非堆内存所包含的内存区域比Java进程中实际的非堆内存区域少,因此可能会出现监控中堆内存+非堆内存总和与通过
top命令看到的RES大小存在一定差值,相关细节请参见JVM监控内存详情说明。
单击
 图标,可以在弹出的对话框中查看该指标在某个时间段的统计情况或对比不同日期在同一时间段的统计情况,通过选择
图标,可以在弹出的对话框中查看该指标在某个时间段的统计情况或对比不同日期在同一时间段的统计情况,通过选择 图标可以切换柱状图、趋势图进行展示。
图标可以切换柱状图、趋势图进行展示。在实例列表区域(图示③),您可以查看实例IP、CPU利用率、内存利用率、磁盘利用率、负载、Full GC次数、Young GC次数、堆内存使用量、非堆内存使用量、RED三指标(请求数、错误数、平均耗时)等信息。
在实例列表,您可以执行以下操作:
容器环境(Prometheus版)
在快捷筛选区域(图示①),您可以按集群和主机地址对图表、实例列表进行筛选。
在趋势图区域(图示②),您可以查看实例的基础监控、实例GC和JVM内存的时序曲线。
基础监控:应用在指定时间范围内CPU用量和内存用量趋势图。
实例GC:应用在指定时间范围内Full GC和Young GC的趋势图。通过图表名称右侧的下拉框可以切换展示GC的次数和平均耗时。
JVM内存:应用在指定时间范围内堆内存已使用和最大值趋势图。通过图标名称右侧的下拉框可以切换展示非堆内存已使用和最大值趋势图。
说明ARMS应用监控采集的数据来自JMX,其中非堆内存所包含的内存区域比Java进程中实际的非堆内存区域少,因此可能会出现监控中堆内存+非堆内存总和与通过
top命令看到的RES大小存在一定差值,相关细节请参见JVM监控内存详情说明。
单击
图标,可以在弹出的对话框中查看该指标在某个时间段的统计情况或对比不同日期在同一时间段的统计情况,通过选择图标可以切换柱状图、趋势图进行展示。在实例列表区域(图示③),您可以查看实例IP、CPU用量、CPU请求、CPU限制、CPU利用率(未设置CPU限制时,此项展示为-)、内存用量、内存请求、内存限制、内存利用率(未设置内存限制时,此项展示为-)、磁盘用量、磁盘限制、磁盘利用率(未设置磁盘限制时,此项展示为-)、负载、Full GC 次数、Young GC 次数、堆内存使用量、非堆内存使用量、RED三指标(请求数、错误数、平均耗时)等。
在实例列表,您可以执行以下操作:
容器环境(ARMS自采集版)
在快捷筛选区域(图示①),您可以按主机地址对图表、实例列表进行筛选。
在趋势图区域(图示②),您可以查看实例的基础监控、实例GC和JVM内存的时序曲线。
基础监控:应用在指定时间范围内CPU用量和内存用量趋势图。
实例GC:应用在指定时间范围内Full GC和Young GC的趋势图。通过图表名称右侧的下拉框可以切换展示GC的次数和平均耗时。
JVM内存:应用在指定时间范围内堆内存已使用和最大值趋势图。通过图标名称右侧的下拉框可以切换展示非堆内存已使用和最大值趋势图。
说明ARMS应用监控采集的数据来自JMX,其中非堆内存所包含的内存区域比Java进程中实际的非堆内存区域少,因此可能会出现监控中堆内存+非堆内存总和与通过
top命令看到的RES大小存在一定差值,相关细节请参见JVM监控内存详情说明。
单击
图标,可以在弹出的对话框中查看该指标在某个时间段的统计情况或对比不同日期在同一时间段的统计情况,通过选择图标可以切换柱状图、趋势图进行展示。在实例列表区域(图示③),您可以查看实例IP、CPU用量、内存用量、负载、Full GC 次数、Young GC 次数、堆内存使用量、非堆内存使用量、RED三指标(请求数、错误数、平均耗时)等。
在实例列表,您可以执行以下操作:
实例详情
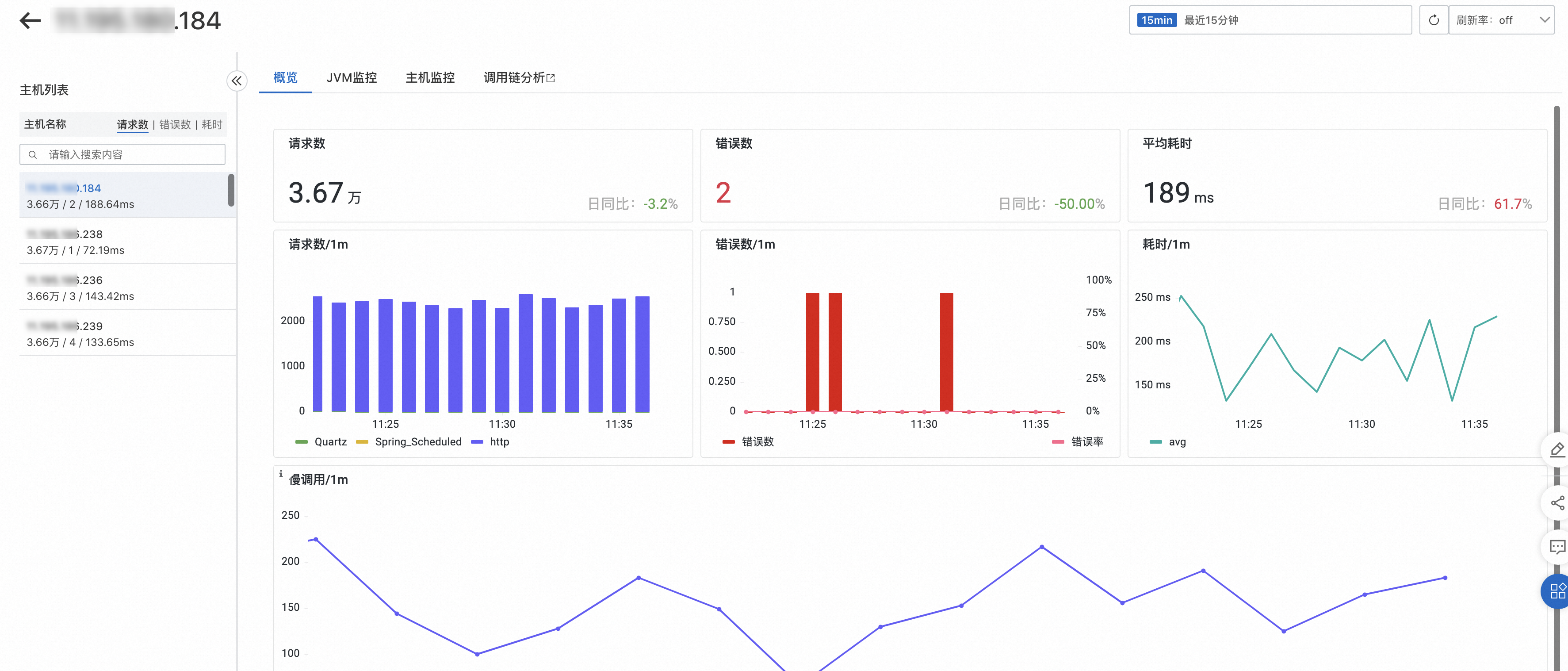
概览
概览页签可以查看目标接口的请求数、错误数、平均耗时和慢调用信息。
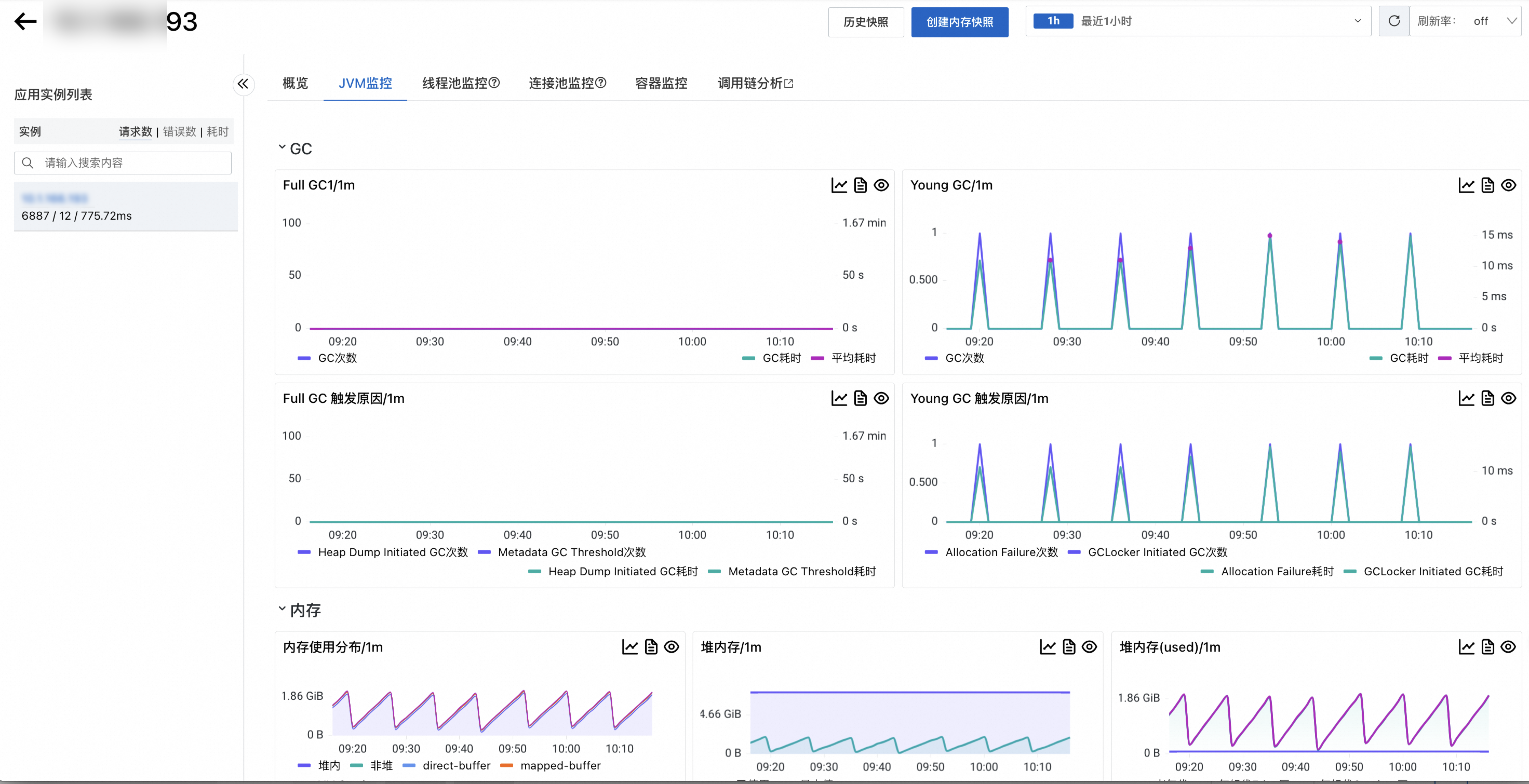
JVM监控
JVM监控页签可以查看对应实例的GC、内存、线程、文件等信息。
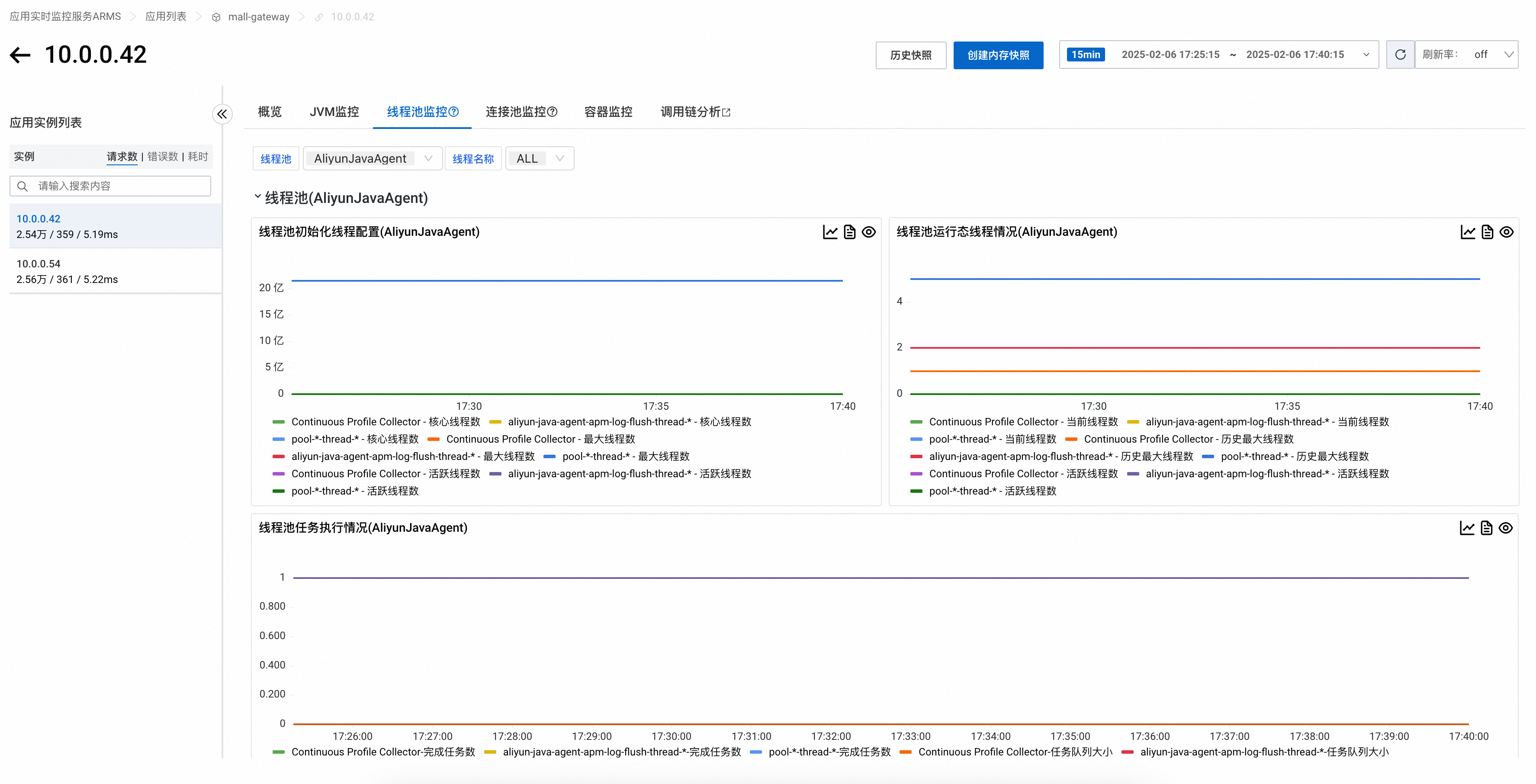
线程池监控
4.1.x及以上探针版本
线程池监控页签可以查看应用所使用的线程池的各项指标,包括线程池初始化线程配置、线程池运行态线程情况、线程池任务执行情况。
在页签顶部可以按线程池类型和名称筛选需要查询的线程池。
4.1.x以下探针版本
线程池监控页签可以查看应用所使用的线程池的核心线程数量、当前线程数量、最大线程数量、活跃线程数量、任务队列容量等指标。
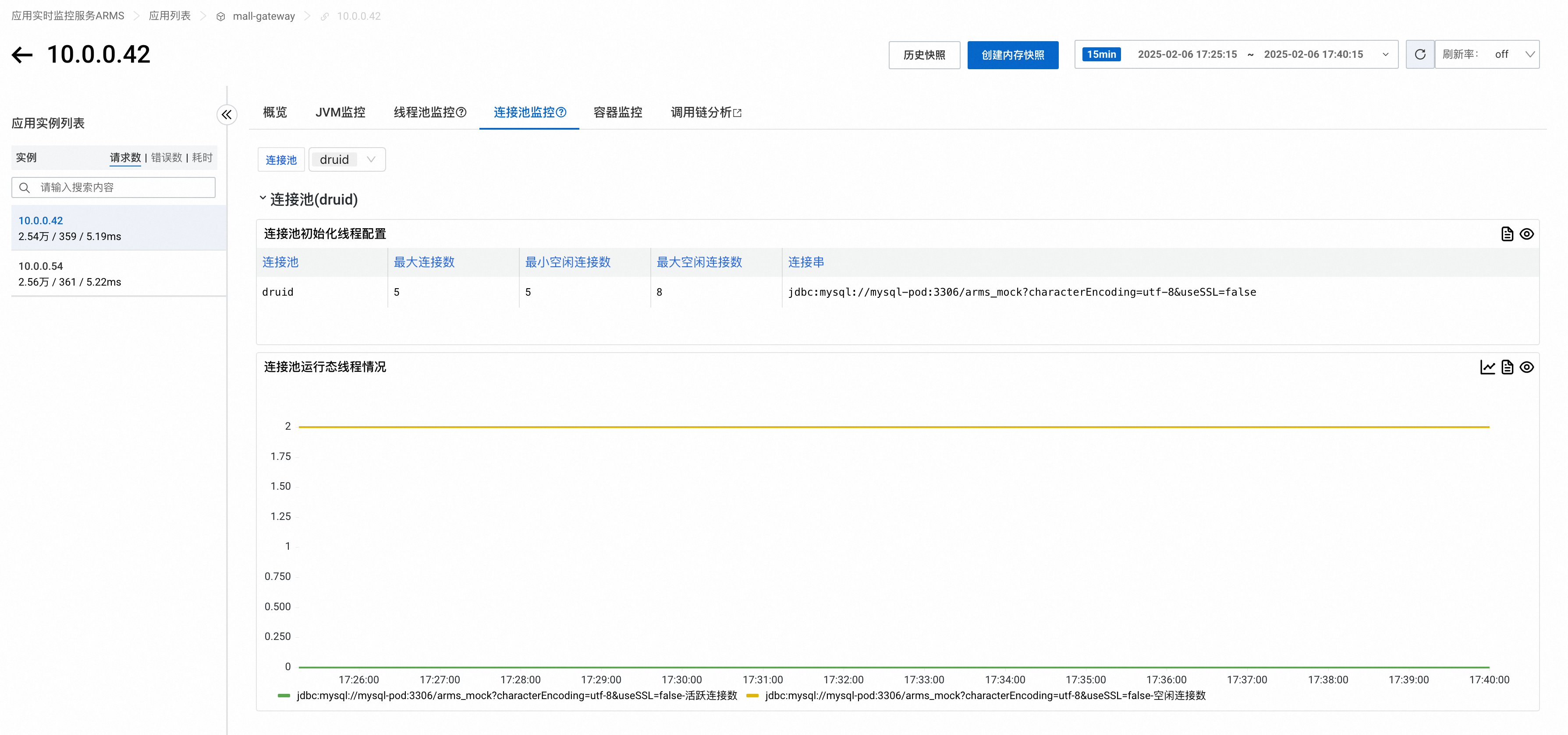
连接池监控
4.1.x及以上探针版本
连接池监控页签可以查看应用所使用的连接池的各项指标,包括连接池初始化线程配置和连接池运行态线程情况。
在页签顶部可以按连接池类型筛选需要查询的连接池。
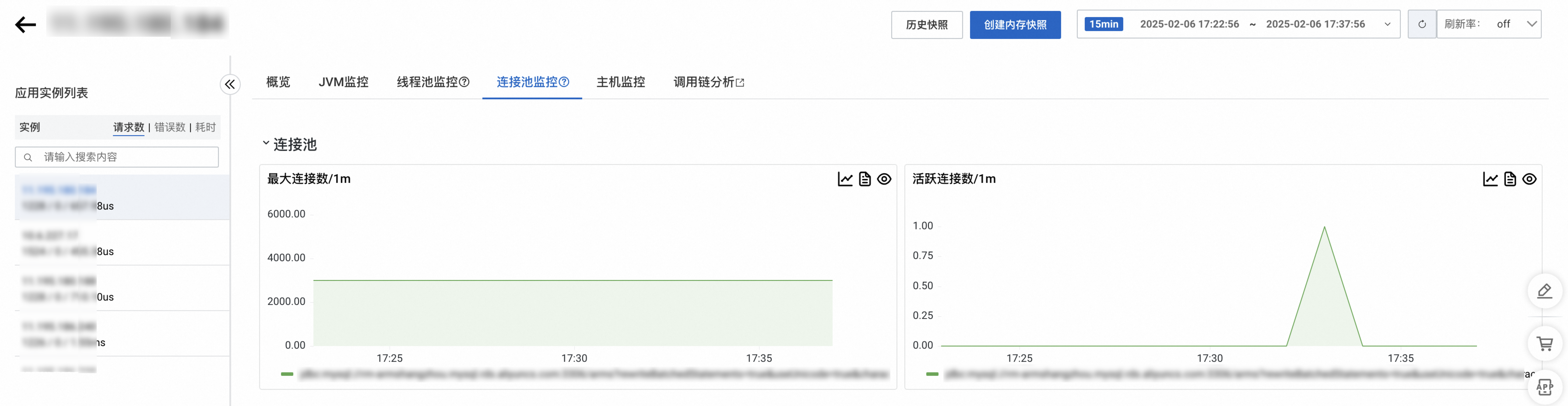
4.1.x以下探针版本
连接池监控页签可以查看应用所使用的连接池的最大连接数和活跃连接数指标。
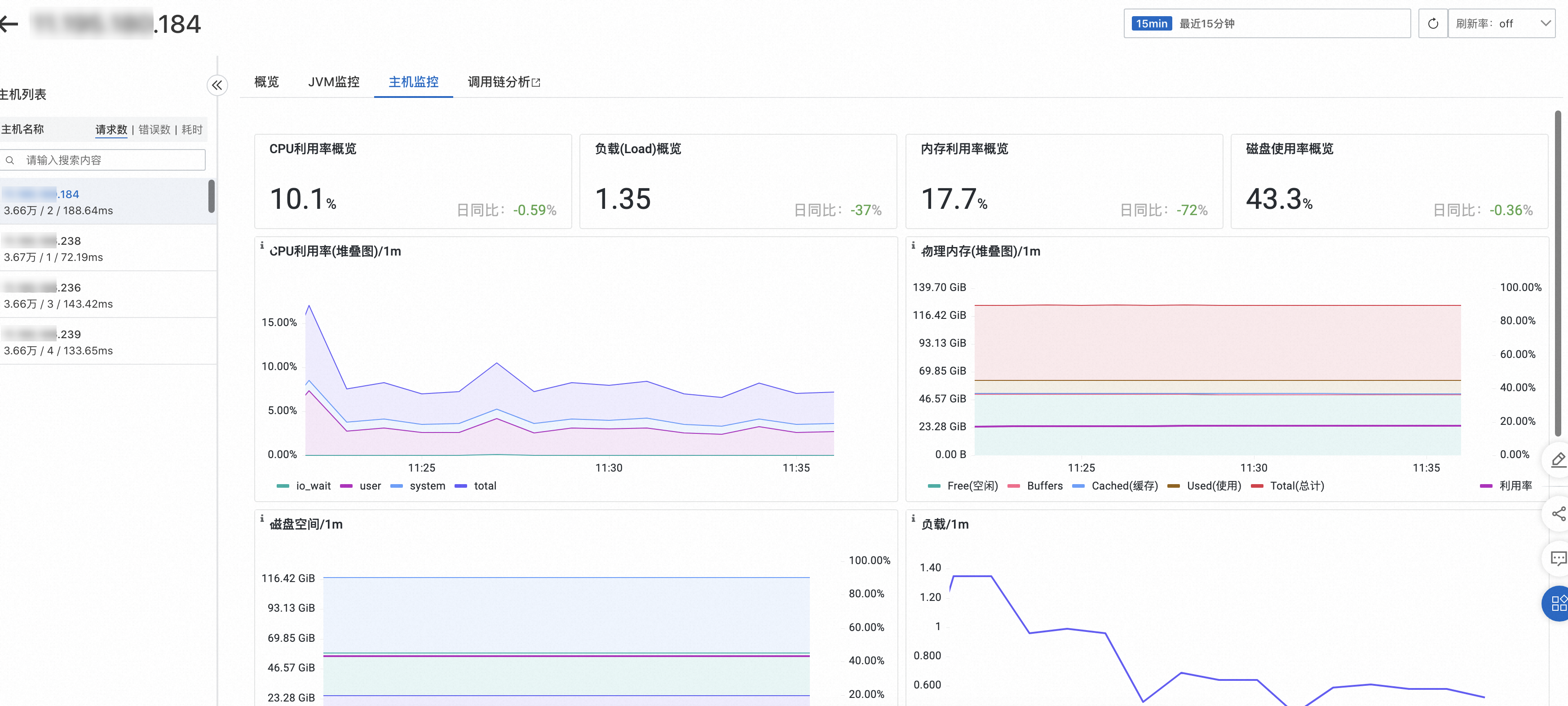
主机监控
主机监控页签可以查看CPU、内存、Disk(磁盘)、Load(负载)、网络流量和网络数据包的各项指标。
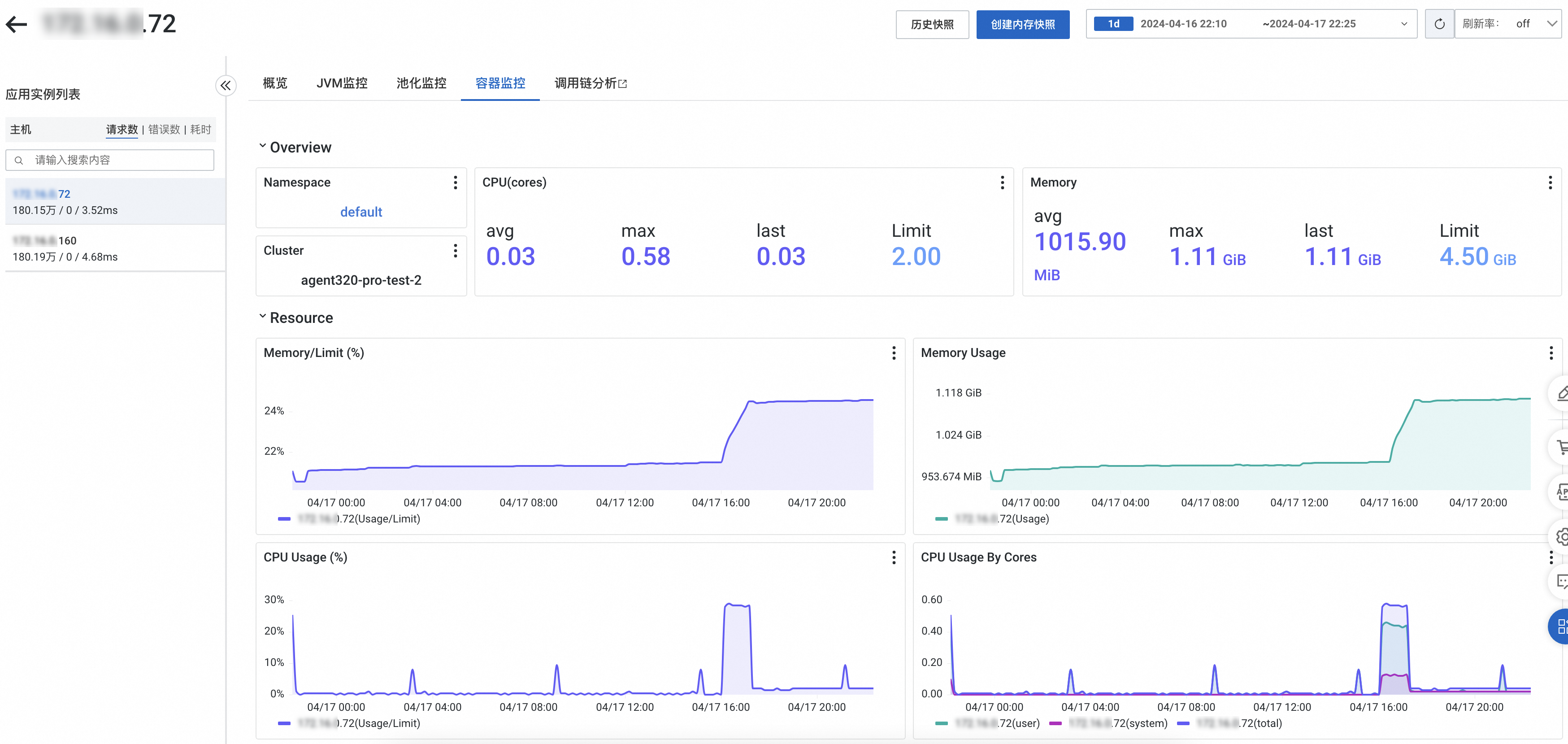
容器监控
容器环境(Prometheus版)
接入可观测监控 Prometheus 版的操作请参见Prometheus实例 for 容器服务。
容器监控页签可以查看容器视角的CPU、内存、Disk(磁盘)、Load(负载)、网络流量和网络数据包的各项指标。
容器环境(ARMS自采集版)
未接入可观测监控 Prometheus 版的情况下,需要确保ARMS探针版本在4.1.0或以上。探针版本说明请参见探针(Java Agent)版本说明。
容器监控页签可以查看容器视角的CPU、内存、网络流量的时序曲线。
调用链分析
调用链分析功能基于已存储的全量链路明细数据,通过自由组合筛选条件与聚合维度进行实时分析,可以满足不同场景的自定义诊断需求。更多信息,请参见调用链分析。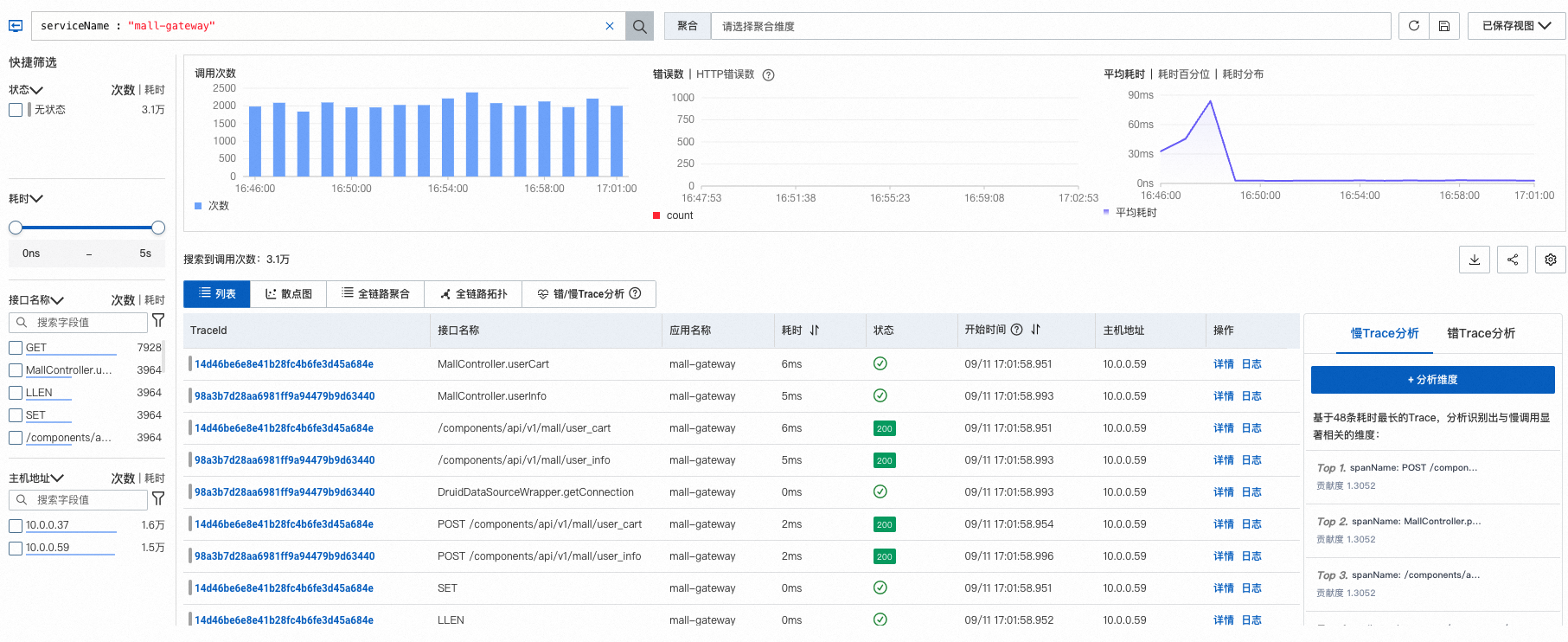
相关文档
应用监控详细的指标信息,请参见应用监控指标说明。
常见问题
应用级别的数据与单机的数据是什么关系
RED(请求数、错误数、延迟)指标:
请求数、慢调用次数、HTTP状态码次数:应用级别的数据是单机级别数据的汇总。
响应时间:应用级别的数据是单机级别数据的平均值。
JVM指标:
GC次数、GC耗时:应用级别的数据是单机级别数据的汇总。
堆内存数据、线程数:应用级别的数据是单机级别数据取最大值。
线程池/连接池指标
所有指标:应用级别的数据是单机级别数据的平均值。
系统指标
所有指标:应用级别的数据是单机级别数据取最大值。
SQL/NSQL调用:同RED指标,对于次数类指标,应用级别的数据是单机级别数据的汇总;对于其余指标,应用级别的数据是单机级别数据的平均值。
异常指标:应用级别的数据是单机级别数据的汇总。
不同实例之间流量不均匀
在3.x版本探针中,如果打开了内存优化开关,可能会导致部分指标统计丢失。该问题已在4.x版本探针中修复。
Undertow一次请求被统计成了两次
3.2.x版本之前探针埋点方法在使用DeferredResult场景下一次调用中会被执行两次。该问题已在3.2.x及以上版本中修复。
容器监控中CPU/内存配额与Pod实际设置不一致
请检查您的Pod中是否定义了多个Container,该指标会统计所有Container加起来的总配额。
系统指标部分缺失、不准或者CPU使用率展示为100%
4.x之前版本探针不支持Windows环境下系统指标采集,4.x及以后版本探针已经修复。
为什么应用刚启动会FullGC
一般是因为用户没有配置元空间大小,默认的元空间大小约为20 MB,应用在刚启动的时候可能会进行元空间的扩容从而触发FullGC,可通过-XX:MetaspaceSize参数和-XX:MaxMetaspaceSize参数设置初始元空间和最大元空间大小。
VM Stack指标是如何计算的
该指标是通过存活(state=live)线程数×1 MB得到的,其中1 MB是线程堆栈默认大小。如果通过-Xss参数重新指定了线程堆栈大小,则该数据与实际情况会有差异。
state=live包含以下状态:live、blocked、new、runnbale、timed-wait和wait。
JVM指标获取原理
ARMS展示的JVM指标均是通过标准的JDK接口获取的,对应接口如下:
内存相关指标:
ManagementFactory.getMemoryPoolMXBeans
java.lang.management.MemoryPoolMXBean#getUsage
GC相关指标:
4.4.0以下版本探针
ManagementFactory.getGarbageCollectorMXBeans
java.lang.management.GarbageCollectorMXBean#getCollectionCount
java.lang.management.GarbageCollectorMXBean#getCollectionTime
4.4.0及以上版本探针
通过订阅由 GarbageCollectorMXBean提供的 GarbageCollectionNotificationInfo事件获取。
为什么JVM最大堆内存值为-1
-1代表未设置最大堆内存大小。
为什么JVM堆内存使用总量不等于设置的堆内存最大值
根据JVM内存分配机制,-Xms参数指定初始堆内存分配,当空余堆内存不足后扩容,直到达到-Xmx参数设置的最大值,总量与最大量不一致说明还没触发扩容,使用量是当前实际用量。
JVM GC的频率逐渐加快
可能是使用了JDK 8默认的GC算法ParallelGC,该算法默认开启了-XX:+UseAdaptiveSizePolicy,其作用是自动调整堆的大小,包括新生代大小、SurvivorRatio等参数,为了满足GC的停顿时间,当Young GC比较频繁时,可能会动态缩小Survivor区的大小,这时候Survivor区的对象很容易晋升到Old区,导致Old区空间涨幅过快,从而触发Full GC的频率也加快。更多信息,请参见Java官方文档。
线程池、连接池监控没有数据
在自定义配置页面的高级设置区域确认是否已经开启线程池、连接池监控开关。
检查框架是否在支持的范围内,具体内容,请参见线程池和连接池监控。
HikariCP连接池获取的最大连接数与实际不符
3.2.x版本之前的探针获取最大连接数代码有误,3.2.x及以上版本已经修复。
池化监控指标展示数值是小数
探针每隔15s采集一次,因此一分钟会采集4个点的数据,控制台会根据采集信息展示一个时间段的平均值。例如:一分钟采集的4个数据点为0、 0、 1、 0,理论上平均值为0.25。
线程池/连接池明明被打满了,但为什么监控上没有体现出来
如果您的日志或其他记录中确实看到线程池/连接池被打满,但是ARMS控制台却看不到相关指标的增长,有可能是由于指标采样时间点与打满的时间点错开导致的。目前ARMS自动采集线程池/连接池状态指标的时间间隔为15s,发生在这个时间段内的瞬时冲高可能不会被采集到。
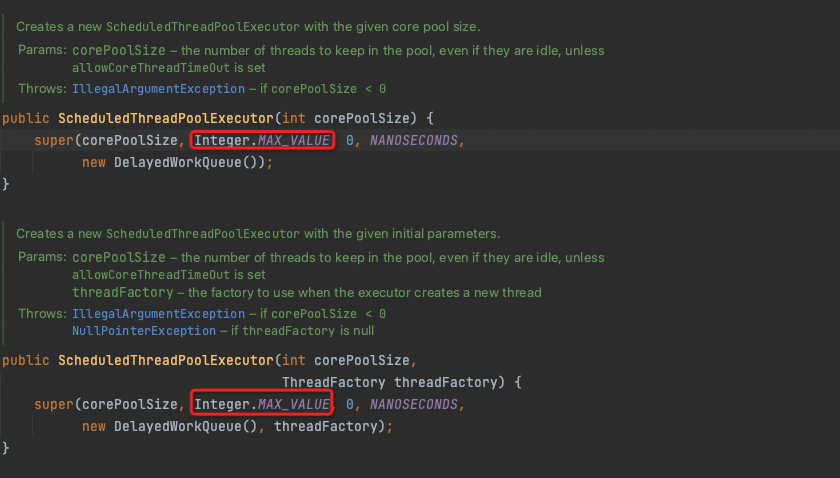
线程池监控最大线程数不符合预期或者最大线程数为21亿
ARMS最大线程池是直接调用线程池对象的获取最大线程数方法得到的,一般不会出错。如果不符合用户预期可能是用户设置的最大线程数未生效。
如果最大线程数为21亿,通常是调度线程池,在调度线程池中,默认设置的最大线程数是Integer.MAX_VALUE,如下图所示。
Tomcat 线程池监控各项指标均不符合预期
ARMS线程池指标是直接调用线程池对象的相应方法得到的,一般不会出错。如果几个维度都匹配不上(最大线程数、活跃线程数、核心线程数等),请先确认您的应用是否通过多个端口对外提供了 Tomcat 服务(如 spring-actuator 这类组件也会开放一个端口暴露指标),这种情况下探针会由于维度收敛机制将多个线程池的数据混在一起统计。如果数据混在一起,可以将探针版本升级到 4.1.10 及以上,并在页面的池化监控配置区域,修改线程池线程名模式提取策略为替换结尾数字字符为*来解决。
某个线程池/连接池在某个时间点前无数据
由业务自行触发了定时任务,任务初始化时产生了线程池/连接池数据,而定时任务被触发前则没有对应的线程池/连接池。流量型数据通常也会存在此类问题,例如某个接口的请求数。
HTTPClient连接池无数据
从ARMS 4.x版本探针开始,ARMS不再支持okHttp3、Apache HTTPClient等框架的连接池监控,主要考虑此类框架会为当前应用的每一个外部访问域名创建一个连接池对象,当访问外部域名较多时,整体开销较高,存在稳定性风险,因此不再支持。
ACK环境应用接入后无法看到容器监控数据
可能原因是创建ACK集群的阿里云账号与接入ARMS的阿里云账号不同,ARMS目前仅支持展示同一阿里云账号下的容器监控数据。
句柄打开率不为0,而文件句柄数为0
请确认应用环境是否为JDK 9+,且ARMS探针版本为3.x,如果是,是由于相关指标采集逻辑在该环境存在兼容性问题,该问题已在4.2.2+版本探针中修复,建议升级探针到对应版本。
JVM进程的实际物理内存占用和JVM监控中的堆内存占用有较大差距
这种情况一般是因为JVM进程有较大的堆外内存占用,ARMS目前仅能监控到JVM进程的堆内内存以及部分堆外内存占用,具体一个JVM占用内存中哪些可以被ARMS监控到哪些无法被监控到请参见JVM监控内存详情说明,如果出现较大的堆外内存占用,可以参见该文档的堆外内存泄露分析章节自行分析。
为什么连接池 Druid 实时的空闲连接数会超过设置的最大空闲连接数?
MaxIdle是Druid为了方便DBCP用户迁移而增加的,实际上不会生效。
部分实例探针升级到了最新版本,但为什么没数据?
若探针是从4.1.x以下版本升级上来的,则需要将全部实例对应的探针升级到最新版本,页面才能自动适配并进行数据展示。