ARMS支持通过分位数统计指标数据,本文介绍ARMS分位数指标的计算原理。
背景介绍
分位数是将一组数据按照大小顺序分成若干等份的数值点,用来表示数据的分布情况。常见的分位数包括:
P50代表中位数,即将数据分为两等份的数值点。
P75表示数据中排在前75%的数值点。
P90表示数据中排在前90%的数值点。
P99表示数据中排在前99%的数值点。
通过分位数可以更直观地了解数据的分布情况,以及数据中的极端值和离群值。
示例说明
示例样本:[2, 3, 6, 7, 8, 9, 10, 12, 14, 15, 16, 17, 18, 20]
对应的分位数分别为:
P50: 10
P75: 16
P90: 18
P99: 20
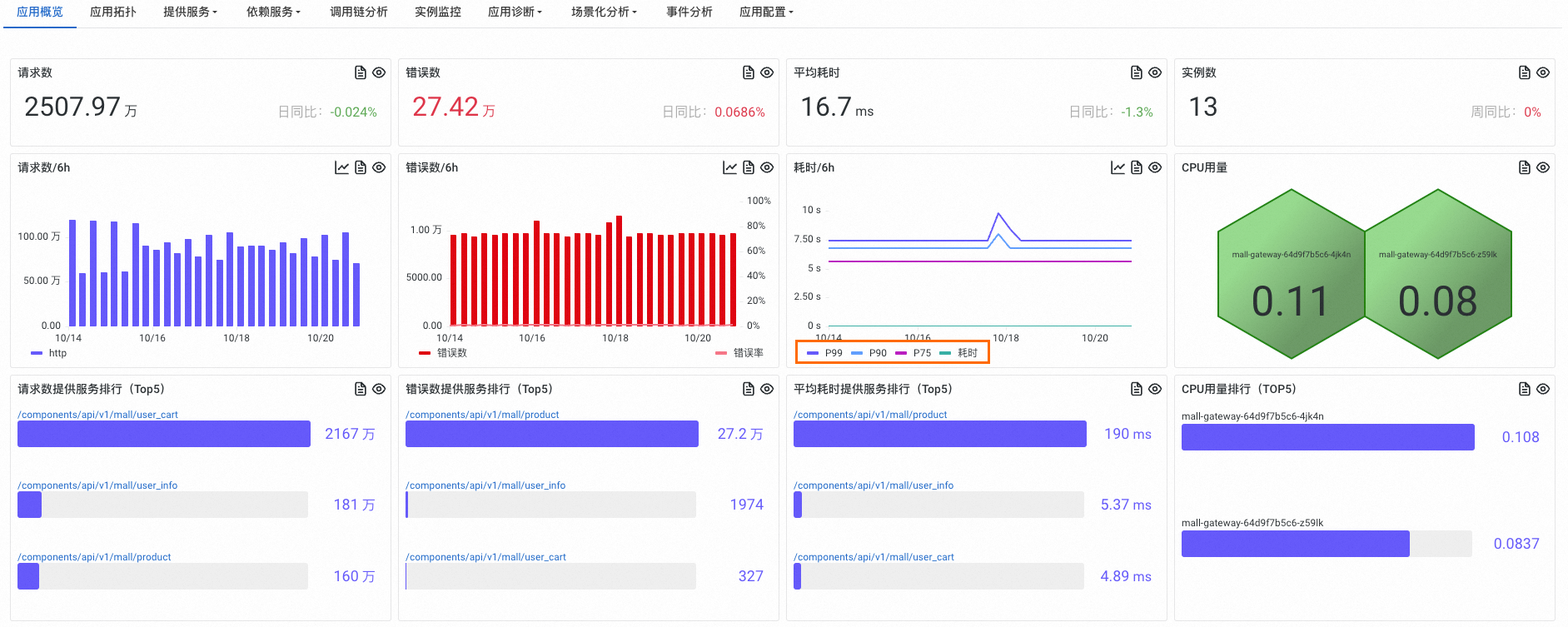
分位数指标示例
新版控制台
开启分位数统计功能的操作请参见Java应用自定义配置。
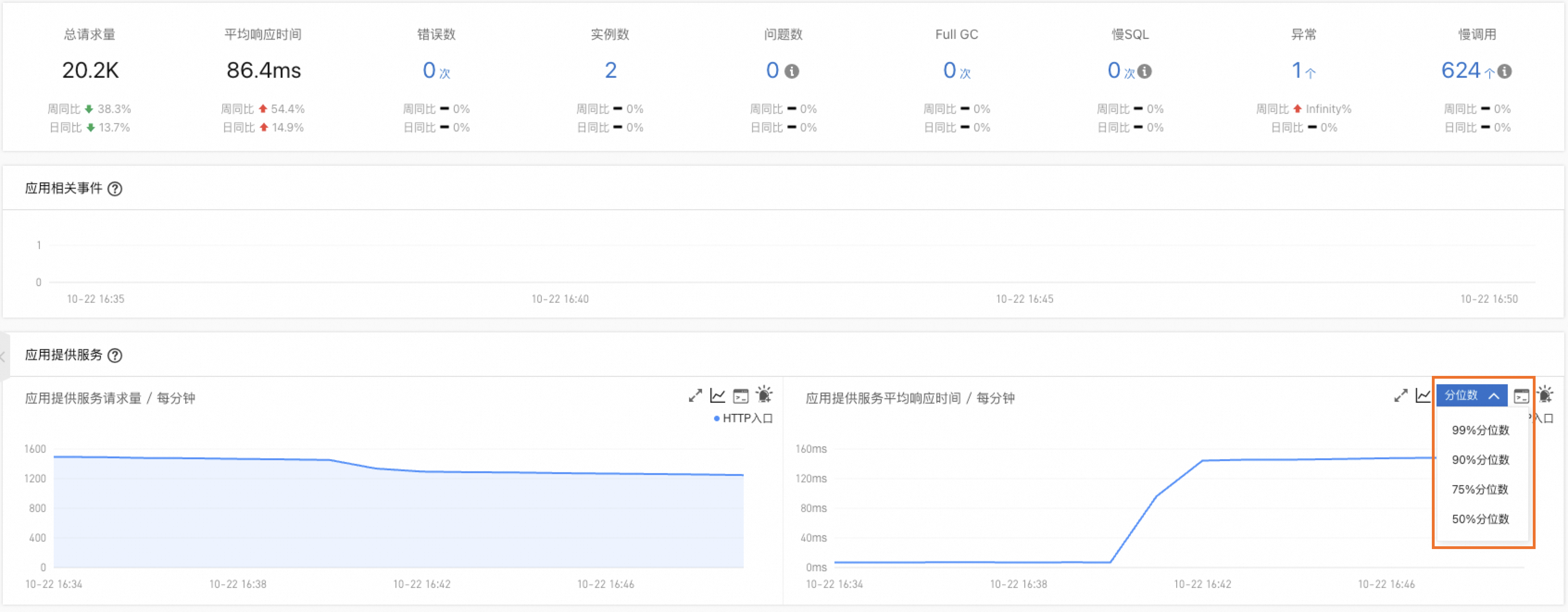
旧版控制台
开启分位数统计功能的操作请参见自定义配置。
ARMS探针分位数计算原理
4.x及以上版本探针基于分桶的方式来计算耗时分位数,目前默认的分桶边界为:
[0.0, 5.0, 10.0, 25.0, 50.0, 75.0, 100.0, 250.0, 500.0, 750.0, 1000.0, 2500.0, 5000.0, 7500.0, 10000.0]。
对应的分桶耗时区间为:
桶0:(-∞, 0.0]
桶1:(0.0, 5.0]
桶2:(5.0, 10.0]
桶3:(10.0, 25.0]
桶4:(25.0,50.0]
桶5:(50.0,75.0]
桶6:(75.0,100.0]
桶7:(100.0,250.0]
桶8:(250.0,500.0]
桶9:(500.0,750.0]
桶10:(750.0,1000.0]
桶11:(1000.0,2500.0]
桶12:(2500.0,5000.0]
桶13:(5000.0,7500.0]
桶14:(7500.0,10000.0]
桶15:(10000.0, +∞]
下面结合示例说明中的样本说明ARMS计算分位数的原理。
针对每一个样本点,确定该样本点对应的分桶,并对对应的分桶计数器计数加1,得到如下结果:
桶0:0
桶1:2
桶2:5
桶3:7
桶4:0
桶5:0
桶6:0
桶7:0
桶8:0
桶9:0
桶10:0
桶11:0
桶12:0
桶13:0
桶14:0
桶15:0
计算分位数。
以计算P75为例。
先根据需要计算的分位数计算分桶表。
P75即需要保证75%的数据在左边,共有14个样本数据,14*0.75 = 10.5,需要找到一个分桶,该分桶的数据和该分桶左边的数据加起来需要有11个样本,所以找到桶3。
按照线性插值的方法计算最终分位数。
桶0 + 桶1 + 桶2已经有7个数据点了,所以在桶3中仅需要找4个数据点,桶3中总共有7个数据点,再结合桶3的区间
(10.0, 25.0]。所以最终P75 = 10.0 + (25.0-10.0)* 4 / 7 = 18.6。
分位数优缺点分析
优点:开销极小,无需保存全量样本数据即可计算任意分位数。
缺点:在耗时极小、耗时极大、样本数很少等场景下,分位数存在计算不准确的情况。
ARMS调用链分析分位数计算原理
调用链分析中分位数是以满足页面过滤条件的所有Span的耗时为样本数据,并调用日志服务的SQL函数计算得到,详情请参见函数概览中估算函数的approx_percentile函数说明。