什么是收敛
ARMS探针在运行过程中会采集很多指标数据(例如请求量、耗时、错误数等),为了能够提供丰富、准确的监控信息,指标中会携带一些维度信息(例如机器、接口等)。由于各种原因,有些维度会出现发散的情况,即高基数问题。高基数问题不仅会给存储系统带来巨大的压力,造成写入丢失、查询缓慢等问题,也会导致用户的账单暴涨。为解决该问题,ARMS提供了相应的收敛机制,一方面可用于解决高基数问题本身,即将维度的基数控制在合理的范围内,另一方面也可用于标记真实的观测维度。例如用户对外提供了RESTful形式的用户服务,其中包含一个查询用户信息的/api/v1/users/{ID}/info接口,如果直接记录原始的请求URL,由于ID的变化,将会记录一堆不同的URL,显然这会造成高基数问题,另外还会导致用户无法直观地获取到接口性能指标。本文将逐一介绍ARMS现有的收敛机制,以帮助您了解收敛发生的原因及收敛结果所代表的含义。
收敛结果说明
ARMS已有的收敛结果及对应的原因概括如下,更详细的部分请参见下文。
收敛结果 | 收敛原因 |
{ARMS_IP}:80 | 访问同一端口的IP数量过多,超过阈值(默认50)。 |
{ARMS_STATIC_REQ} 或 {ARMS_S_XXX} | URL为静态资源相关的请求。 |
{ARMS_ATTACK_REQ} | URL中包含攻击字符串。 |
{ARMS_PARAMED_REQ} | URL中携带了参数。 |
{ARMS_OTHERS} | 单位时间内,记录的维度值超过了允许的上限。 说明 默认上限阈值详细请参见下文基数空间收敛。 |
{ARMS_NUMBER} | URL中以 |
{ARMS_WORD} | URL中以 |
{ARMS_ANY} | URL中以 |
{XXX} | 使用了SpringController中的注解。 |
含有*的字符串 说明 仅适用于探针版本小于4.x的情况。 | 基于探针端的内存统计机制对发散的部分进行了收敛。 |
收敛机制说明
以下所有收敛机制都是默认开启的。除基数空间收敛外,所有收敛机制均支持用户手动关闭。
不同的收敛机制支持的数据类型不同,每个收敛机制都会注明所支持的数据类型。
Spring注解收敛
对传统的Web API来说,直接以请求URL作为维度值不会有任何问题,但对于RESTful形式的API或URL中包含变量的API来说,直接记录请求URL将会导致维度发散。因此,对于使用了Spring Web框架的应用,ARMS会尝试提取相应的注解信息(例如@RequestMapping)作为接口的维度值。
收敛逻辑
读取Spring URL路由注解中的Path信息。
收敛结果
路由注解中配置的Value。
支持的数据类型
URL:仅适用于对外提供服务的URL,对于外部URL不适用。
收敛发生位置
探针端
支持的探针版本
2.9.1.2及以上版本
示例
下述APIController定义了一个获取用户信息的接口,其中使用了Path Variable。在采集接口数据时,将提取其注解(/api/v1/user/{userId}/info)作为最终的接口。
@RestController
@RequestMapping("/api/v1")
public class APIController {
@RequestMapping("/user/{userId}/info")
public String getUserInfo(@PathVariable("userId") String userId) {
return "hello " + userId;
}
}收敛结果:
/api/v1/user/1234/info被收敛为/api/v1/user/{userId}/info 。
基于内存统计的收敛
对于未使用Spring Web框架的应用或注解提取失败的场景,将使用基于内存统计的收敛算法进行收敛。
仅适用于4.X以下版本的探针。
收敛逻辑
对每一个输入使用预设的切分符号(/、=等)进行切割,识别出一组单词N。
对每个位置的单词,统计其不重复的个数(即基数),当个数超过设置阈值时,该位置的单词就会变为
*。
收敛结果
包含*的字符串
支持的数据类型
任意
收敛发生位置
探针端
支持的探针版本
2.x及以上版本且小于4.X版本
示例
应用A中对外提供一个用户信息查询接口,请求方式为/api/v1/user/${userId}/info,其中$userId填写具体的userId。由于存在大量的userId, 内存统计模块会发现$userId存在发散的情况,便会将其收敛
为 /api/v1/user/*/info
自定义收敛
该功能支持用户自定义一些收敛规则,来满足一些特定的收敛需求。
收敛逻辑
逐一匹配用户配置的收敛规则,如果命中,则结束。
收敛结果
以用户配置为准。
支持的数据类型
URL
收敛触发位置
4.x及以上版本触发于探针端
4.x以下版本触发于服务端
支持的探针版本
所有
示例
用户配置的规则:匹配/api/v1/user/[\d]+/info,收敛为/api/v1/getUserInfo。
对于所有命中/api/v1/user/[\d]+/info正则表达式的请求将都被收敛为/api/v1/getUserInfo。
静态资源收敛
正常情况下,ARMS并不会监控静态资源相关请求。由于一些历史原因,老旧的探针会采集静态资源相关的指标数据,鉴于大多数情况下静态资源并不具备监控价值且资源URL变化频繁,默认开启收敛。
收敛逻辑
检查请求URL后缀是否命中默认的静态资源扩展名,如命中则会被收敛。
默认的静态资源扩展名:.log .7z .tgz .jpg .jpeg .png .gif .css .js .ico .woff2 .xml .svg .pdf .txt .text .ppt .word .xlsx .tar.gz .tar.bz2 .sh .yml .yaml .zip .log .gz .ttf .woff .eot .rar .properties
收敛结果
默认为{ARMS_STATIC_REQ},开启高级选项时(如有需要可提工单开启),收敛结果中将包含资源后缀名。
支持的数据类型
URL
收敛触发位置
4.x及以上版本触发于探针端
4.x以下版本触发于服务端
支持的探针版本
所有
示例
/api/v1/hello.jpg默认收敛为{ARMS_STATIC_REQ},开启高级选项时,收敛为{ARMS_S_JPG}。
攻击请求收敛
根据经验,用户服务可能会受到一些莫名的攻击请求(例如尝试读取/etc/passwd文件),这些请求是被攻击者构造出来的,变化频繁,记录下来会给存储带来较大压力。
收敛逻辑
检查URL中是否含有攻击字符,如存在则会被收敛。
默认的攻击字符:` $ \ ' !
收敛结果
{ARMS_ATTACK_REQ}
支持的数据类型
URL
收敛触发位置
4.x及以上版本触发于探针端
4.x以下版本触发于服务端
支持的探针版本
所有
示例
/app/v1/user/info?cmd=`more /etc/passwd`收敛为{ARMS_ATTACK_REQ}。
带参请求收敛
默认情况下,探针在采集URL时并不会获取参数信息,但依然存在部分场景下采集到的URL中包含了查询参数,由于查询参数不可控,极易导致维度发散。
收敛逻辑
判断URL中是否带有查询参数,如果存在则进行收敛。
默认的查询参数分隔符:; ? &
收敛结果
默认为{ARMS_PARAMED_REQ},开启高级选项时(如有需要可提工单开启),收敛结果将保留URL部分,参数部分使用{ARMS_REQ_PARAMS}进行替换。
支持的数据类型
URL
收敛触发位置
4.x及以上版本触发于探针端
4.x以下版本触发于服务端
支持的探针版本
所有
示例
/api/v1/user/info?userId=12345默认收敛为{ARMS_PARAMED_REQ},开启高级选项时,收敛为/api/v1/user/info?{ARMS_REQ_PARAMS}。
无意义单词收敛
一般来说,一个URL中如果含有长度过长的单词或数字,该URL大概率会发散,为了尽量减少发散的情况。ARMS默认会对过长的单词或数字进行替换。
收敛逻辑
以/切分URL,结果记为term数组,遍历term数组,针对每个term判断其长度是否超过下述阈值,如果超过则会进行替换。
单词最大长度:64
纯数字最大长度:10
单词中包含的数字最大长度:10
收敛结果
过长的数字被收敛为:{ARMS_NUMBER}
过长的单词被收敛为:{ARMS_WORD}
单词中包含的数字过长被收敛为:{ARMS_ANY}
支持的数据类型
URL
收敛触发位置
4.x及以上版本触发于探针端
4.x以下版本触发于服务端
支持的探针版本
所有
示例
/api/2024040710/hello2024040710将被收敛为/api/{ARMS_NUMBER}/{ARMS_ANY}。
智能收敛
经过上文几个收敛动作后,依然有可能存在大量发散的URL被记录下来,针对这部分URL,ARMS会周期性基于算法自动计算出相应的收敛规则,然后替换掉原始的URL。
收敛逻辑
逻辑较为复杂,此处仅做简单介绍。
基于算法对样本URL进行分组。
对每个分组内的URL Pattern进行收敛处理,生成收敛规则。
合并各分组的收敛规则。
收敛结果
发散部分如果为纯数字,将被替换为{ARMS_NUMBER}。
发散部分如果为纯字母,将被替换为{ARMS_WORD}。
发散部分如果同时包含数字和字母,将被替换为{ARMS_ANY}。
支持的数据类型
URL
收敛触发位置
4.x及以上版本触发于探针端
4.x以下版本触发于服务端
支持的探针版本
所有
示例
/api/product/1/info
/api/product/2/info
....
/api/product/N/info服务端经过计算后,会生成收敛规则:/api/product/[\d]+/info(正则匹配)
收敛结果为/api/product/{ARMS_NUMBER}/info。
后续符合上述正则的请求,都将被收敛为/api/product/{ARMS_NUMBER}/info。
SQL规整化
由于多种情况的存在(例如分库分表、注释、明文),探针很可能会采集到大量SQL。基于这种情况,ARMS默认会对每条SQL进行处理,替换掉可能发散的部分。
规整逻辑
逻辑较为复杂,此处仅做简单介绍。
注释移除。
明文替换。
分库分表名替换。
...
规整结果
替换掉发散部分后的结果。
支持的数据类型
SQL
收敛发生位置
探针端
支持的探针版本
4.X 及以上版本
示例
select * from cache_0 where ckey='23'将会被收敛为:
select * from cache_{NUM} where ckey=?IP收敛
如果应用依赖的外部服务众多且直接使用IP进行访问,将会导致探针采集到大量的外部IP,导致发散。
收敛逻辑
按照端口对IP进行分组。
统计分组后,每个端口内包含的IP数,如果超过阈值则收敛。默认阈值:50
收敛结果
{ARMS_IP}:port
支持的数据类型
IP
收敛触发位置
4.x及以上版本触发于探针端
4.x以下版本触发于服务端
支持的探针版本
所有
示例
1.1.1.1:8080
...
1.1.1.255:8080将被收敛为{ARMS_IP}:8080。
基数空间收敛
对于URL类型的维度来说,经过上文收敛机制的处理,基本可以解决高基数问题。但对于SQL等类型来说,即使我们尽可能剔除了可能发散的信息,依然可能会记录大量的维度值,为解决这一问题,ARMS对单位时间内可以记录的维度值进行了控制,以保证不会出现发散问题。
收敛逻辑
逻辑较为复杂,此处仅做简单介绍。
周期性生成大小固定的基数空间。
针对每一个维度值,首先判断基数空间中是否已存在该值,如存在则原样返回,否则尝试放入基数空间,如果可以放入则原样返回,否则返回{ARMS_OTHERS}。
收敛结果
超过空间限制的维度值收敛为{ARMS_OTHERS}。
默认阈值
观测对象 | 阈值(个) |
URL接口 | 每小时500 |
调度任务 | 每小时1000 |
RPC接口 | 每小时1000 |
上游接口 | 每小时200 |
正常SQL | 每小时100 |
慢SQL | 每小时100 |
外部请求URL | 每小时200 |
外部请求地址 | 每小时100 |
支持的数据类型
任意
收敛触发位置
4.x及以上版本触发于探针端
4.x以下版本触发于服务端
支持的探针版本
所有
示例
指标会记录外部服务地址,假定外部服务地址如下,基数空间的大小为每小时100个记录。
www.a1.com
www.a2.com
....
www.a1000.com那么每1小时,仅有前100个外部服务会被记录下来,后续的外部服务地址都会被收敛为{ARMS_OTHERS}。
执行顺序
4.x以下版本
探针端
URL类型
Spring收敛 > 基于内存统计的收敛
SQL类型
基于内存统计的收敛
IP等其他类型
基于内存统计的收敛
服务端
URL类型
自定义收敛 > 攻击请求收敛 > 带参请求收敛 > 静态资源收敛 > 无意义单词收敛 > 智能收敛> 基数空间收敛
SQL类型
自定义收敛 > 基数空间收敛
IP等其他类型
自定义收敛 > IP收敛 > 基数空间收敛
4.x及以上版本
探针端
URL类型
Spring收敛 > 自定义收敛 > 攻击请求收敛 > 带参请求收敛 > 静态资源收敛 > 无意义单词收敛 > 智能收敛> 基数空间收敛
SQL类型
自定义收敛 > SQL规整化 > 基数空间收敛
IP等其他类型
自定义收敛 > IP收敛 > 基数空间收敛
服务端
不适用
收敛执行将按照上述顺序逐一执行,维度值被任一收敛机制收敛后,将不再继续执行后续逻辑。
常见问题
在哪里可以看到收敛前的原始值?
对于4.x以上探针版本,Trace数据中会记录原始的值也会记录收敛后的值,您可以通过调用链分析功能查看到原始值。更多信息,请参见调用链分析。
对于4.x以下的探针版本,由于大部分收敛逻辑发生在服务端,目前无法查看收敛前的原始值。
收敛结果不满足预期,我该如何处理?
可以通过自定义收敛规则能力进行调整。
打开新版ARMS控制台,切换到应用设置/收敛配置功能,即可添加自定义收敛规则。
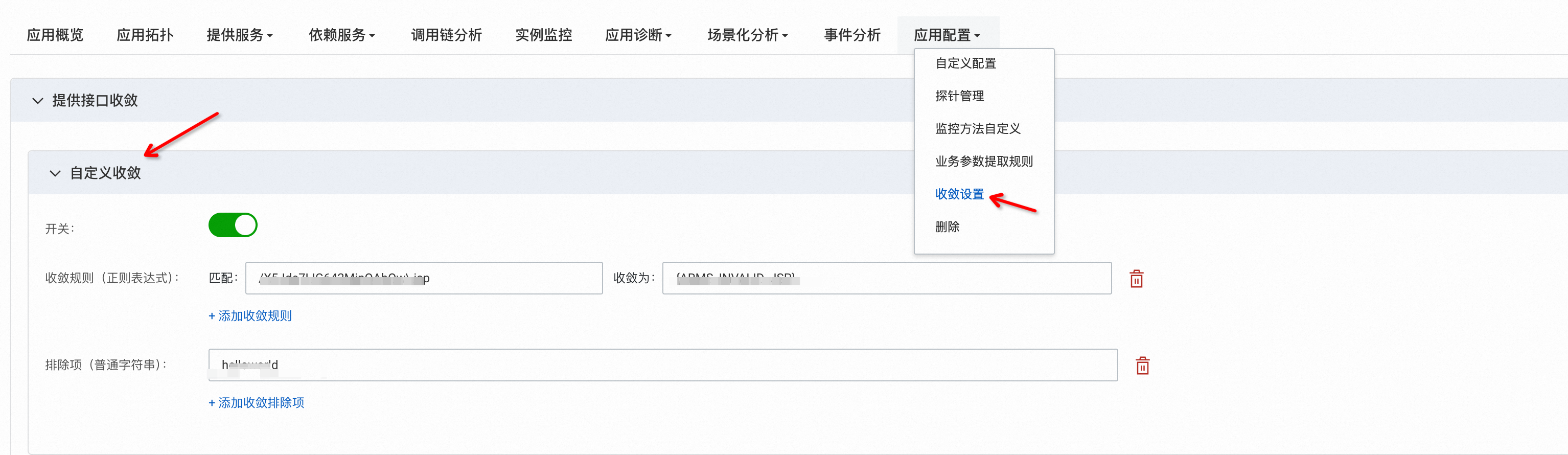
示例:
添加匹配/api/v1/user/\d+/info收敛为/api/v1/user/userId/info,即可将形如/api/v1/user/124343543/info的请求收敛为/api/v1/user/userId/info。
收敛结果误伤了一些重要接口,我不想这些重要接口被收敛,该如何处理?
参考问题2,打开收敛配置功能,在自定义收敛块添加排除项即可。
示例:
添加/api/v1/user/9999/info,那么/api/v1/user/9999/info就不会被收敛为/api/v1/user/userId/info。
探针端收敛与服务端收敛有什么差异?
探针端收敛即意味着收敛行为发生在探针侧,那么上报到服务端数据就已经是收敛过的,对于服务端来说处理的压力会大大降低,且可以保证100%的数据准确性。
当探针版本较低时,很多收敛机制是不支持的,一旦出现了发散的情况,只能在服务端进行收敛处理,由于探针端并未进行收敛处理,此时上报到服务端的数据包可能会很大。一方面存在因数据包过大被拒绝导致数据丢失的风险,另一方面受限于服务端的处理机制,经过收敛处理后的数据准确性会存在一定的偏差。因此,强烈建议升级到最新版本的探针。