本文主要介绍云消息队列 RocketMQ 版TCP协议的Java客户端使用过程中,经常会出现的消息堆积和消息延迟的问题。通过了解云消息队列 RocketMQ 版客户端的消费原理和消息堆积的主要原因,帮助您可以在业务部署前更好的规划资源和配置,或在运维过程中及时调整业务逻辑,避免因消息堆积和延迟影响业务运行。
背景信息
消息处理流程中,如果客户端的消费速度跟不上服务端的发送速度,未处理的消息会越来越多,这部分消息就被称为堆积消息。消息出现堆积进而会造成消息消费延迟。以下场景需要重点关注消息堆积和延迟的问题:
业务系统上下游能力不匹配造成的持续堆积,且无法自行恢复。
业务系统对消息的消费实时性要求较高,即使是短暂的堆积造成的消息延迟也无法接受。
客户端消费原理
云消息队列 RocketMQ 版TCP协议客户端的消费流程如下图所示。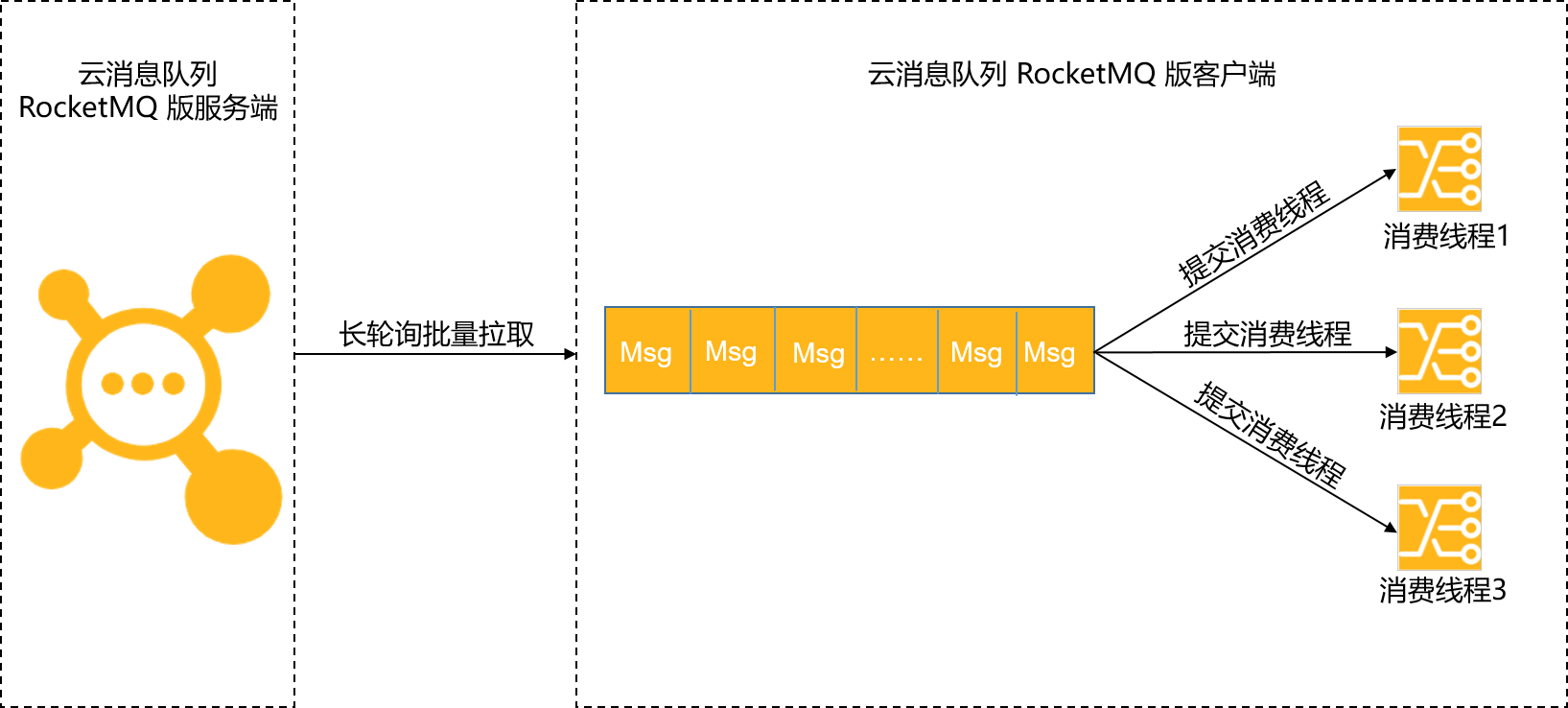
SDK客户端使用Push模式消费消息时,分为以下两个阶段:
阶段一:获取消息,SDK客户端通过长轮询批量拉取的方式从云消息队列 RocketMQ 版服务端获取消息,将拉取到的消息缓存到本地缓冲队列中。
SDK获取消息的方式为批量拉取,常见内网环境下都会有很高的吞吐量,例如:1个单线程单分区的低规格机器(4C8GB)可以达到几万TPS,如果是多个分区可以达到几十万TPS。所以这一阶段一般不会成为消息堆积的瓶颈。
阶段二:提交消费线程,SDK客户端将本地缓存的消息提交到消费线程中,使用业务消费逻辑进行处理。
此时客户端的消费能力就完全依赖于业务逻辑的复杂度(消费耗时)和消费逻辑并发度了。如果业务处理逻辑复杂,处理单条消息耗时都较长,则整体的消息吞吐量肯定不会高,此时就会导致客户端本地缓冲队列达到上限,停止从服务端拉取消息。
通过以上客户端消费原理可以看出,消息堆积的主要瓶颈在于本地客户端的消费能力,即消费耗时和消费并发度。想要避免和解决消息堆积问题,必须合理的控制消费耗时和消息并发度,其中消费耗时的优先级高于消费并发度,必须先保证消费耗时的合理性,再考虑消费并发度问题。
消费耗时
影响消费耗时的消费逻辑主要分为CPU内存计算和外部I/O操作,通常情况下,代码中不涉及复杂的递归和循环,其内部计算所耗时间相较于外部I/O操作几乎可以忽略不计。外部I/O操作通常包括如下业务逻辑:
读写外部数据库,例如MySQL数据库读写。
读写外部缓存等系统,例如Redis读写。
下游系统调用,例如Dubbo调用或者下游HTTP接口调用。
这类外部调用的逻辑和系统容量您需要提前梳理,掌握每个调用操作预期的耗时,这样才能判断消费逻辑中I/O操作的耗时是否合理。通常消费堆积都是由于这些下游系统出现了服务异常、容量限制导致的消费耗时增加。
例如:某业务消费逻辑中需要写一条数据到数据库,单次消费耗时为1 ms,平时消息量小未出现异常。业务侧进行大促活动时,写数据库TPS爆发式增长,并很快达到数据库容量限制,导致消费单条消息的耗时增加到100 ms,业务侧可以明显感受到消费速度大幅下跌。此时仅通过调整云消息队列 RocketMQ 版SDK的消费并发度并不能解决问题,需要对数据库容量进行升配才能从根本上提高客户端消费能力。
消费并发度
云消息队列 RocketMQ 版消费消息的并发度计算方法如下表所示。
消息类型 | 消费并发度 |
普通消息 | 单节点线程数*节点数量 |
定时和延时消息 | |
事务消息 | |
顺序消息 | Min(单节点线程数*节点数量,分区数) |
客户端消费并发度由单节点线程数和节点数量共同决定,一般情况下需要优先调整单节点的线程数,若单机硬件资源达到上限,则必须通过扩容节点来提高消费并发度。
顺序消息的消费并发度还受Topic中分区个数的限制,具体分区数,请联系阿里云技术支持根据业务情况进行评估。
单节点的并发度需要谨慎设置,不能盲目直接调大线程数,设置过大的线程数反而会带来大量的线程切换的开销。理想环境下单节点的最优线程数计算模型如下:
单机vCPU核数为C。
线程切换耗时忽略不计,I/O操作不消耗CPU。
线程有足够消息等待处理,且内存充足。
逻辑中CPU计算耗时为T1,外部I/O操作为T2。
则单个线程能达到的TPS为1/(T1+T2),如果CPU使用率达到理想状态100%,那么单机达到最大能力时需要设置C*(T1+T2)/T1个线程。
这里计算的最大线程数仅仅是在理想环境下得到的理论数据,实际应用环境中建议逐步调大线程数并观察效果再进行调整。
如何避免消息堆积和延迟
为了避免在业务使用时出现非预期的消息堆积和延迟问题,您需要在前期设计阶段对整个业务逻辑进行完善的排查和梳理。整理出正常业务运行场景下的性能基线,才能在故障场景下迅速定位到阻塞点。其中最重要的就是梳理消息的消费耗时和消息消费的并发度。
梳理消息的消费耗时
通过压测获取消息的消费耗时,并对耗时较高的操作的代码逻辑进行分析。查询消费耗时,请参见获取消息消费耗时。梳理消息的消费耗时需要关注以下信息:
消息消费逻辑的计算复杂度是否过高,代码是否存在无限循环和递归等缺陷。
消息消费逻辑中的I/O操作(如:外部调用、读写存储等)是否是必需的,能否用本地缓存等方案规避。
消费逻辑中的复杂耗时的操作是否可以做异步化处理,如果可以是否会造成逻辑错乱(消费完成但异步操作未完成)。
设置消息的消费并发度
逐步调大单个节点的线程数,并观测节点的系统指标,得到单个节点最优的消费线程数和消息吞吐量。
得到单个节点的最优线程数和消息吞吐量后,根据上下游链路的流量峰值计算出需要设置的节点数,节点数=流量峰值/单线程消息吞吐量。