本文介绍如何通过创建Tablestore Sink Connector,将数据从云消息队列 Kafka 版实例的数据源Topic导出至表格存储(Tablestore)。
前提条件
云消息队列 Kafka 版
已为实例开启Connector。具体操作,请参见开启Connector。
已为实例创建数据源Topic。更多信息,请参见步骤一:创建Topic。
表格存储
已开通表格存储服务并创建实例。具体操作,请参见开通服务并创建实例。
注意事项
操作流程
使用Tablestore Sink Connector将数据从云消息队列 Kafka 版实例的数据源Topic导出至表格存储操作流程如下:
可选:创建Tablestore Sink Connector依赖的Topic和Group
如果您不需要自定义Topic和Group,您可以直接跳过该步骤,在下一步骤选择自动创建。
重要部分Tablestore Sink Connector依赖的Topic的存储引擎必须为Local存储,大版本为0.10.2的云消息队列 Kafka 版实例不支持手动创建Local存储的Topic,只支持自动创建。
结果验证
创建Tablestore Sink Connector依赖的Topic
您可以在云消息队列 Kafka 版控制台手动创建Tablestore Sink Connector依赖的5个Topic,包括:任务位点Topic、任务配置Topic、任务状态Topic、死信队列Topic以及异常数据Topic。每个Topic所需要满足的分区数与存储引擎会有差异,具体信息,请参见配置源服务参数列表。
在概览页面的资源分布区域,选择地域。
重要Topic需要在应用程序所在的地域(即所部署的ECS的所在地域)进行创建。Topic不能跨地域使用。例如Topic创建在华北2(北京)这个地域,那么消息生产端和消费端也必须运行在华北2(北京)的ECS。
在实例列表页面,单击目标实例名称。
在左侧导航栏,单击Topic 管理。
在Topic 管理页面,单击创建 Topic。
在创建 Topic面板,设置Topic属性,然后单击确定。
参数
说明
示例
名称
Topic名称。
demo
描述
Topic的简单描述。
demo test
分区数
Topic的分区数量。
12
存储引擎
说明当前仅专业版实例支持选择存储引擎类型,标准版暂不支持,默认选择为云存储类型。
Topic消息的存储引擎。
云消息队列 Kafka 版支持以下两种存储引擎。
云存储:底层接入阿里云云盘,具有低时延、高性能、持久性、高可靠等特点,采用分布式3副本机制。实例的规格类型为标准版(高写版)时,存储引擎只能为云存储。
Local 存储:使用原生Kafka的ISR复制算法,采用分布式3副本机制。
云存储
消息类型
Topic消息的类型。
普通消息:默认情况下,保证相同Key的消息分布在同一个分区中,且分区内消息按照发送顺序存储。集群中出现机器宕机时,可能会造成消息乱序。当存储引擎选择云存储时,默认选择普通消息。
分区顺序消息:默认情况下,保证相同Key的消息分布在同一个分区中,且分区内消息按照发送顺序存储。集群中出现机器宕机时,仍然保证分区内按照发送顺序存储。但是会出现部分分区发送消息失败,等到分区恢复后即可恢复正常。当存储引擎选择Local 存储时,默认选择分区顺序消息。
普通消息
日志清理策略
Topic日志的清理策略。
当存储引擎选择Local 存储(当前仅专业版实例支持选择存储引擎类型为Local存储,标准版暂不支持)时,需要配置日志清理策略。
云消息队列 Kafka 版支持以下两种日志清理策略。
Delete:默认的消息清理策略。在磁盘容量充足的情况下,保留在最长保留时间范围内的消息;在磁盘容量不足时(一般磁盘使用率超过85%视为不足),将提前删除旧消息,以保证服务可用性。
Compact:使用Kafka Log Compaction日志清理策略。Log Compaction清理策略保证相同Key的消息,最新的value值一定会被保留。主要适用于系统宕机后恢复状态,系统重启后重新加载缓存等场景。例如,在使用Kafka Connect或Confluent Schema Registry时,需要使用Kafka Compact Topic存储系统状态信息或配置信息。
重要Compact Topic一般只用在某些生态组件中,例如Kafka Connect或Confluent Schema Registry,其他情况的消息收发请勿为Topic设置该属性。具体信息,请参见云消息队列 Kafka 版Demo库。
Compact
标签
Topic的标签。
demo
创建完成后,在Topic 管理页面的列表中显示已创建的Topic。
创建Tablestore Sink Connector依赖的Group
您可以在云消息队列 Kafka 版控制台手动创建Tablestore Sink Connector数据同步任务使用的Group。该Group的名称必须为connect-任务名称,具体信息,请参见配置源服务参数列表。
在概览页面的资源分布区域,选择地域。
在实例列表页面,单击目标实例名称。
在左侧导航栏,单击Group 管理。
在Group 管理页面,单击创建 Group。
在创建 Group面板的Group ID文本框输入Group的名称,在描述文本框简要描述Group,并给Group添加标签,单击确定。
创建完成后,在Group 管理页面的列表中显示已创建的Group。
创建并部署Tablestore Sink Connector
创建并部署将数据从云消息队列 Kafka 版同步至表格存储的Tablestore Sink Connector。
在概览页面的资源分布区域,选择地域。
在左侧导航栏,单击Connector 任务列表。
在Connector 任务列表页面,从选择实例的下拉列表选择Connector所属的实例,然后单击创建 Connector。
在创建 Connector配置向导页面,完成以下操作。
在配置基本信息页签,按需配置以下参数,然后单击下一步。
参数
描述
示例值
名称
Connector的名称。命名规则:
可以包含数字、小写英文字母和短划线(-),但不能以短划线(-)开头,长度限制为48个字符。
同一个云消息队列 Kafka 版实例内保持唯一。
Connector的数据同步任务必须使用名称为connect-任务名称的Group。如果您未手动创建该Group,系统将为您自动创建。
kafka-ts-sink
实例
默认配置为实例的名称与实例ID。
demo alikafka_post-cn-st21p8vj****
在配置源服务页签,选择数据源为消息队列Kafka版,并配置以下参数,然后单击下一步。
说明如果您已创建好Topic和Group,那么请选择手动创建资源,并填写已创建的资源信息。否则,请选择自动创建资源。
表 1. 配置源服务参数列表
参数
描述
示例值
数据源 Topic
需要同步数据的Topic。
ts-test-input
消费线程并发数
数据源Topic的消费线程并发数。默认值为6。取值说明如下:
1
2
3
6
12
6
消费初始位置
开始消费的位置。取值说明如下:
最早位点:从最初位点开始消费。
最近位点:从最新位点开始消费。
最早位点
VPC ID
数据同步任务所在的VPC。单击配置运行环境显示该参数。默认为云消息队列 Kafka 版实例所在的VPC,您无需填写。
vpc-bp1xpdnd3l***
vSwitch ID
数据同步任务所在的交换机。单击配置运行环境显示该参数。该交换机必须与云消息队列 Kafka 版实例处于同一VPC。默认为部署云消息队列 Kafka 版实例时填写的交换机。
vsw-bp1d2jgg81***
失败处理
消息发送失败后,是否继续订阅出现错误的Topic的分区。单击配置运行环境显示该参数。取值说明如下。
继续订阅:继续订阅出现错误的Topic的分区,并打印错误日志。
停止订阅:停止订阅出现错误的Topic的分区,并打印错误日志
说明如何查看日志,请参见Connector相关操作。
如何根据错误码查找解决方案,请参见错误码。
继续订阅
创建资源方式
选择创建Connector所依赖的Topic与Group的方式。单击配置运行环境显示该参数。
自动创建
手动创建
自动创建
Connector 消费组
Connector的数据同步任务使用的Group。单击配置运行环境显示该参数。该Group的名称必须为connect-任务名称。
connect-cluster-kafka-ots-sink
任务位点 Topic
用于存储消费位点的Topic。单击配置运行环境显示该参数。
Topic:建议以connect-offset开头。
分区数:Topic的分区数量必须大于1。
存储引擎:Topic的存储引擎必须为Local存储。
cleanup.policy:Topic的日志清理策略必须为compact。
connect-offset-kafka-ots-sink
任务配置 Topic
用于存储任务配置的Topic。单击配置运行环境显示该参数。
Topic:建议以connect-config开头。
分区数:Topic的分区数量必须为1。
存储引擎:Topic的存储引擎必须为Local存储。
cleanup.policy:Topic的日志清理策略必须为compact。
connect-config-kafka-ots-sink
任务状态 Topic
用于存储任务状态的Topic。单击配置运行环境显示该参数。
Topic:建议以connect-status开头。
分区数:Topic的分区数量建议为6。
存储引擎:Topic的存储引擎必须为Local存储。
cleanup.policy:Topic的日志清理策略必须为compact。
connect-status-kafka-ots-sink
死信队列 Topic
用于存储Connect框架的异常数据的Topic。单击配置运行环境显示该参数。该Topic可以和异常数据Topic为同一个Topic,以节省Topic资源。
Topic:建议以connect-error开头。
分区数:Topic的分区数量建议为6。
存储引擎:Topic的存储引擎可以为Local存储或云存储。
connect-error-kafka-ots-sink
异常数据 Topic
用于存储Sink的异常数据的Topic。单击配置运行环境显示该参数。该Topic可以和死信队列Topic为同一个Topic,以节省Topic资源。
Topic:建议以connect-error开头。
分区数:Topic的分区数量建议为6。
存储引擎:Topic的存储引擎可以为Local存储或云存储。
connect-error-kafka-ots-sink
在配置目标服务页签,选择目标服务为表格存储,并配置以下参数,然后单击创建。
参数
描述
示例值
实例名称
表格存储的实例名称。
k00eny67****
自动创建目标表
是否在表格存储中自动创建表。
是:在表格存储中根据配置的表名自动创建一个存储同步数据的表。
否:使用已创建的表存储同步数据。
是
目标表名
存储同步数据的表名称。如果自动创建目标表选择否,表名称需与表格存储实例中已有表名称相同。
kafka_table
表格存储
存储同步数据的表类型。
宽表模型
时序模型
宽表模型
消息 Key 格式
消息Key的输入格式。支持String和JSON两种格式,默认值为JSON。当表格存储选择宽表模型时显示该参数。
String:直接将消息的Key作为字符串解析。
JSON:消息的Key必须符合JSON格式。
String
消息 Value 格式
消息值的输入格式。支持String和JSON两种格式。默认值为JSON。当表格存储选择宽表模型时显示该参数。
String:直接将消息的Value作为字符串解析。
JSON:消息的Value必须符合JSON格式。
String
JSON消息字段转化
JSON消息的字段处理方式。消息 Key 格式或消息 Value 格式选择JSON时显示该参数。取值范围如下:
全部作为String写入:将所有字段转化为表格存储中对应的String。
自动识别字段类型:将JSON消息体中的String和Boolean字段分别转化为表格存储中对应的String和Boolean字段。JSON消息体中的Integer和Float数据类型,将被转化为表格存储中的Double类型。
全部作为String写入
主键模式
指定主键模式。支持从云消息队列 Kafka 版消息记录的不同部分提取数据表主键,包括消息记录的Coordinates(Topic,Partition,Offset),Key和Value。当表格存储选择宽表模型时显示该参数。默认值为kafka。
kafka:表示以<connect_topic>_<connect_partition>和 <connect_offset>作为数据表的主键。
record_key:表示以Record Key中的字段作为数据表的主键。
record_value:表示以 Record Value 中的字段作为数据表的主键。
kafka
主键列名配置
数据表的主键列名和对应的数据类型。支持string和Integer两种数据类型,表示从Record Key或Record Value中提取与配置的主键列名相同的字段作为数据表的主键。
消息 Key 格式选择JSON,且主键模式选择record_key,或消息 Value 格式选择JSON,且主键模式选择record_value,显示该参数。
单击添加可以增加列名。最多支持配置四个列名。
无
写入模式
指定写入模式,支持put和update两种写入模式,默认值为put。当表格存储选择宽表模型时显示该参数。
put:表示覆盖写。
update:表示更新写。
put
删除模式
当云消息队列 Kafka 版消息记录出现空值时,您可以选择是否进行删除行或删除属性列的操作。主键模式选择record_key显示该参数。取值范围如下:
none:默认值,不允许进行任何删除。
row:允许删除行。
column:允许删除属性列。
row_and_column:允许删除行和属性列。
删除操作与写入模式的配置相关。具体如下:
如果写入模式为put,选择任意一种删除模式,当Value中存在空值时,数据均覆盖写入表格存储数据表。
如果写入模式为update,选择none或row删除模式,当Value所有字段值均为空值时,数据作为脏数据处理。当Value部分字段值为空值时,自动忽略空值,将非空值写入表格存储数据表。选择column或row_and_column删除模式,当Value存在空值时,删除行和属性列后,将数据写入表格存储数据表。
无
度量名称字段
将该字段映射为表格存储时序模型中的度量名称字段(_m_name),表示时序数据所度量的物理量或者监控指标的名称,比如temperature、speed等,不能为空。当表格存储选择时序模型时显示该参数。
measurement
数据源字段
将该字段映射为表格存储时序模型中的数据源字段(_data_source),作为产生某个时间序列数据的数据源标识,比如机器名或者设备ID等,可以为空。当表格存储选择时序模型时显示该参数。
source
标签字段
将一个或多个字段作为表格存储时序模型中的标签字段(_tags)。每个标签是一个字符串类型的Key和Value,Key为配置的字段名,Value为字段内容。标签作为时间线元数据的一部分,度量名称、数据源、标签共同标识一条时间线,可以为空。当表格存储选择时序模型时显示该参数。
tag1, tag2
时间戳字段
将该字段映射为表格存储时序模型中的时间戳字段(_time)。表示该行时序数据所对应的时间点,比如产生物理量的时刻等。在数据写入表格存储时,会将时间戳字段转换成微秒单位进行写入和存储。当表格存储选择时序模型时显示该参数。
time
时间戳单位
视时间戳字段实际情况进行配置。当表格存储选择时序模型时显示该参数。取值范围如下:
SECONDS(秒)
MILLISECONDS(毫秒)
MICROSECONDS(微秒)
NANOSECONDS(纳秒)
MILLISECONDS
是否映射全部非主键字段
是否将非主键字段(主键字段为已经映射为度量名称、数据源、标签或时间戳的字段)全部映射为数据字段。当表格存储选择时序模型时显示该参数。取值范围如下:
是:会自动映射字段并判断数据类型,数值类型会全部转换为Double类型。
否:需要指定需要映射的字段和类型。
是
配置映射全部非主键字段
时序表的非主键字段名称对应的字段类型。支持Double、Integer、String、Binary和Boolean五种数据类型。当是否映射全部非主键字段选择否时显示该参数。
String
创建完成后,在Connector 任务列表页面,查看创建的Connector 。
创建完成后,在Connector 任务列表页面,找到创建的Connector ,单击其操作列的部署。
单击确认。
发送测试消息
部署Tablestore Sink Connector后,您可以向云消息队列 Kafka 版的数据源Topic发送消息,测试数据能否被同步至表格存储。
在Connector 任务列表页面,找到目标Connector,在其右侧操作列,单击测试。
在发送消息面板,发送测试消息。
发送方式选择控制台。
在消息 Key文本框中输入消息的Key值,例如demo。
在消息内容文本框输入测试的消息内容,例如 {"key": "test"}。
设置发送到指定分区,选择是否指定分区。
单击是,在分区 ID文本框中输入分区的ID,例如0。如果您需查询分区的ID,请参见查看分区状态。
单击否,不指定分区。
发送方式选择Docker,执行运行 Docker 容器生产示例消息区域的Docker命令,发送消息。
发送方式选择SDK,根据您的业务需求,选择需要的语言或者框架的SDK以及接入方式,通过SDK发送消息。
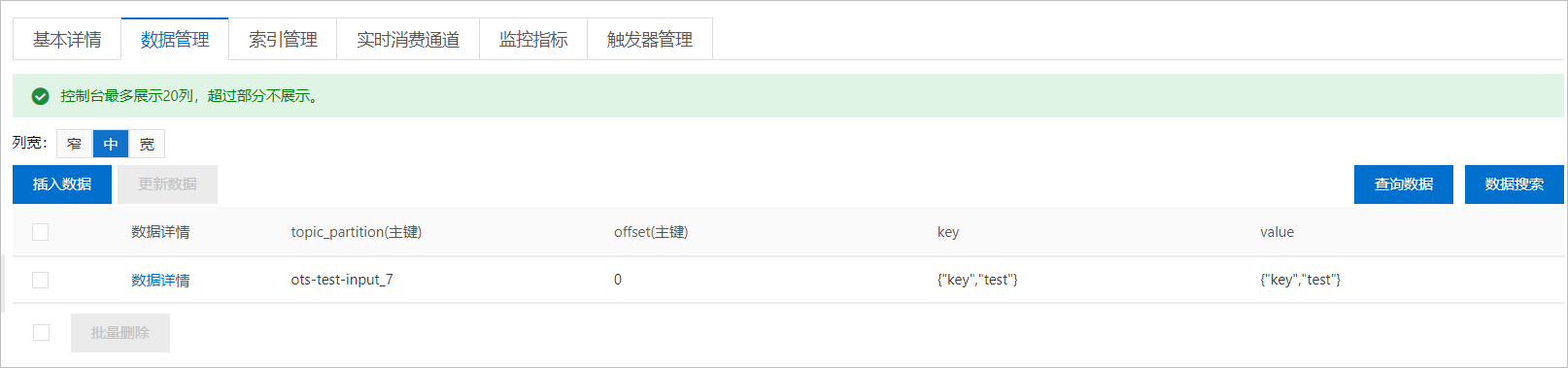
查看表数据
向云消息队列 Kafka 版的数据源Topic发送消息后,在表格存储控制台查看表数据,验证是否收到消息。
登录表格存储控制台。
在概览页面,单击实例名称或在操作列单击实例管理。
在实例详情页签,数据表列表区域,查看对应的数据表。

单击数据表名称,在表管理页面的数据管理页签,查看表数据。