AnalyticDB for MySQL在前端接入节点接收到查询请求后,会将查询切分成多个Stage,在存储节点(Worker节点)和子任务执行节点(Executor节点)分布式进行数据的读取和计算。部分Stage可以并行执行,但部分Stage之间存在依赖关系,只能串行执行,导致一些复杂SQL语句的查询耗时问题难以分析,您可以调用API或通过控制台使用Stage和Task详情进行慢查询问题分析。本文主要介绍如何使用Stage和Task详情分析查询。
操作步骤
登录云原生数据仓库AnalyticDB MySQL控制台,在左上角选择集群所在地域。在左侧导航栏,单击集群列表。在集群列表上方,选择产品系列,然后单击目标集群ID。
在左侧导航栏,单击诊断优化。
在SQL列表区域,单击诊断。
单击Stage&Task详情,查看目标Stage的详细信息。Stage的查询结果说明,请参见Stage查询结果说明。
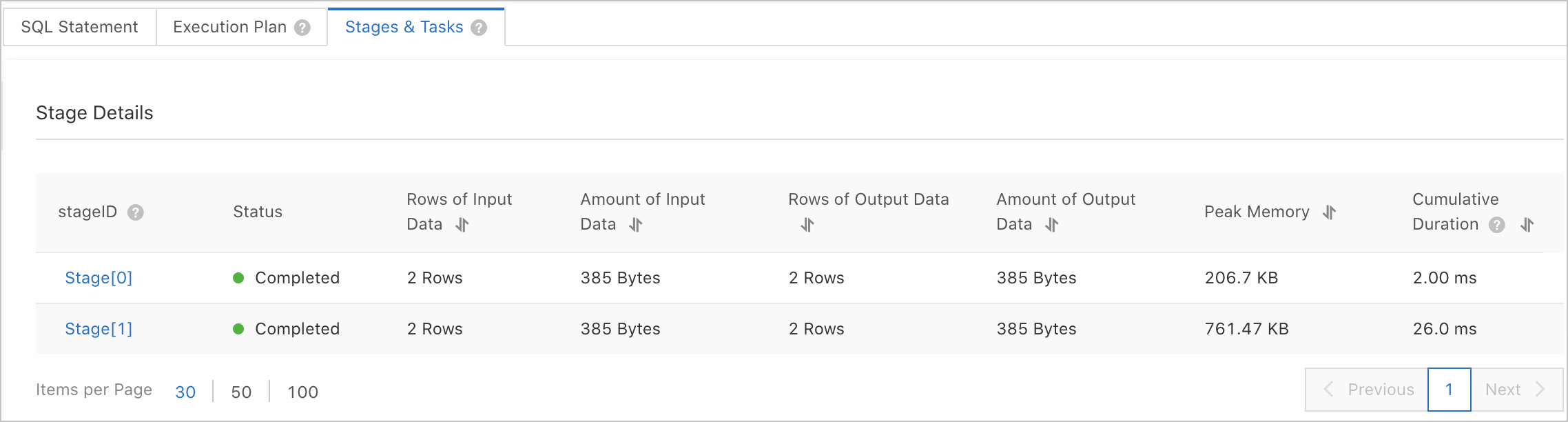
如果是慢查询,单击目标StageID,查看目标Stage下所有Task的详细信息。Task的查询结果说明,请参见Task查询结果说明。
重要仅耗时超过1秒的查询支持查看Task详细信息。
列表字段说明
Stage列表字段说明
字段 | 说明 |
StageID | Stage的唯一标识,和执行计划树中的StageID对应。 |
状态 | Stage的执行状态。取值:
|
Stage输入行数 | Stage的输入数据行数。 |
Stage输入数据量 | Stage的输入数据大小。 |
Stage输出行数 | Stage的输出数据行数。 |
Stage输出数据量 | Stage的输出数据大小。 |
峰值内存 | Stage的内存最大值。 |
累计耗时 | Stage所有算子消耗的时间之和。 该字段可以初步定位耗时较高的Stage,也可以协助定位CPU消耗较高的Stage。累积耗时不能与查询耗时直接比较,需要结合Stage的并行度判断查询耗时和累计耗时是否有关。 |
Task列表字段说明
字段 | 说明 |
TaskID | Task的唯一标识。 例如: |
状态 | Task的执行状态。取值:
|
Task输入数据量 | Task的输入数据量,包括输入行数和输入数据大小。 对输入数据量进行排序,可以查看Stage的输入数据是否存在数据倾斜。如果存在数据倾斜,说明分组查询的分组字段或Join条件字段存在数据倾斜,需要追溯到当前Task所属的Stage的上游Stage进一步定位问题。 说明 数据倾斜即分布字段设置不合理,导致数据在Worker节点上分布不均衡。 |
Task输出数据量 | Task的输出数据量,包括输出行数和输出数据大小。 根据当前Stage算子计划树中的聚合节点(Aggregation)或Join节点的属性,对应到具体的SQL语句,判断分区字段或者Join条件字段中是否存在某些字段组合。例如: |
峰值内存 | Task执行过程中的内存最大值。 峰值内存和输入数据大小成正比,峰值内存可以判断某些节点是否存在内存使用极不均衡导致查询失败的问题。 |
表数据读取耗时 | 当某个Stage的算子树中有表扫描节点(TableScan)时,表示该Stage的所有表扫描节点在读取表数据时的耗时累加值。 表数据读取耗时是一个多机多线程的累加值,不能直接和查询耗时比较。与累计耗时比较时,可以判断一个Stage的计算量是否消耗在数据扫描上。 |
表数据读取量 | 当某个Stage的算子树中有表扫描节点(TableScan)时,表示该Stage的所有表扫描节点从源表读取的数据行数和数据大小。 对该字段进行排序,可以判断源表数据是否存在数据倾斜。如果存在数据倾斜,您可以通过控制台进行分布字段倾斜诊断,具体操作,请参见存储空间诊断。 |
创建时间 | Task的创建时间。 |
排队时间 | Task在真正开始执行前的排队时间。 |
结束时间 | Task执行结束时间。 |
开始结束时间差 | Task结束时间和Task创建时间两个绝对时间的时间差。例如:Task的创建时间是2022-12-12 12:00:00,结束时间是2022-12-12 12:00:04,则开始结束时间差为4s。 开始结束时间差与查询耗时比较,可以确定耗时瓶颈发生的位置。例如:查询耗时是6s,开始结束时间差是4s,则耗时瓶颈发生在当前Stage。详细的计算方法,请参见Task耗时与并发度计算示例。 |
累计耗时 | Stage中所有Task任务的所有线程耗时的累加。详细的计算方法,请参见Task耗时与并发度计算示例。 |
计算时间占比 | 实际处理数据的耗时在子任务生命周期中的比例。 计算公式为:计算时间占比=(累积耗时/子任务并发度)/开始结束时间差。其中,(累积耗时/子任务并发度)表示每个线程实际处理数据平均耗时,开始结束时间差包含实际处理数据的时间、子任务排队耗时、网络等待延迟等。详细的计算方法,请参见Task耗时与并发度计算示例。 说明 开始结束时间差越大,计算时间占比越小,需要重点定位耗时的算子;开始结束时间差越小,计算时间占比越大,需要重点定位资源等待、网络延迟等问题。 |
子任务并发度 | 每个Task在单机内是多线程并发执行的,同时执行计算任务的线程数就是子任务的并发度。详细的计算方法,请参见Task耗时与并发度计算示例。 |
执行节点 | Task实际执行的内部节点IP地址。如果多个查询都在相同的节点出现长尾现象,需要重点定位某个节点问题。 说明 长尾现象即在AnalyticDB for MySQL分布式执行任务时,某些Task任务执行的时间远大于其他Task任务的执行时间。 |
Task耗时与并发度计算示例
以Task2.1为例,介绍Task任务开始结束时间差、累加耗时、计算时间占比和子任务并发度的计算方法。
假设Task2.1所在的Stage[2]包含四个算子:StageOutput、Join、TableScan、RemoteSource。算子树形图如下所示。
算子树形图在多个节点上按箭头方向并行执行,其中Task2.1在192.168.12.23上有4个线程并发的执行,分别为线程1、线程2、线程3、线程4,处理数据耗时分别为5s、5s、6s、6s。如下图所示:
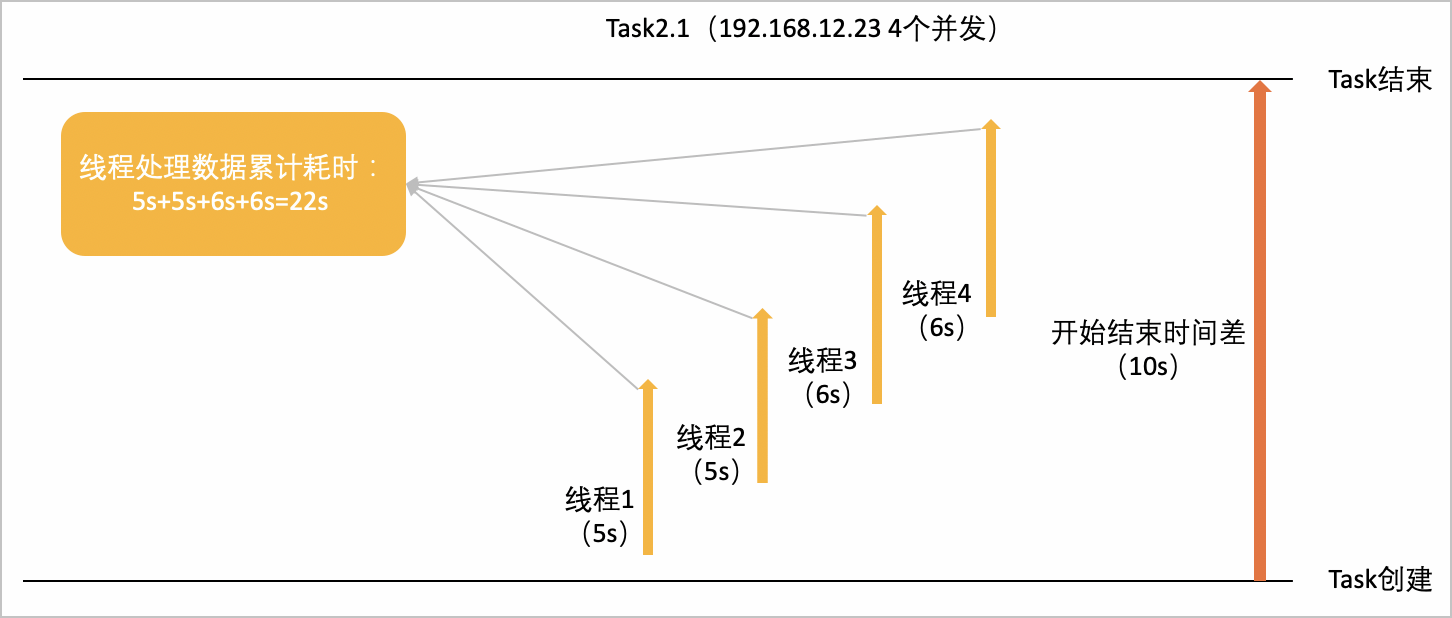
Task的累积耗时:所有线程耗时的累加,即5s+5s+6s+6s=22s。
开始结束时间差:10s。
计算时间占比:计算时间占比=(累积耗时/子任务并发度)/开始结束时间差,即(22s/4)/10s=0.55。
相关API
API | 描述 |
获取SQL执行详情。 | |
获取指定查询ID和Stage ID的分布式子任务执行详情。 |