本文介绍如何在AnalyticDB for MySQL中对分组聚合查询进行优化。
分组聚合流程
AnalyticDB for MySQL是分布式数据仓库,其分组聚合查询默认分为两步:
完成数据的局部(PARTIAL)聚合。
局部聚合节点只需要占用少量内存,聚合过程为流式过程,数据不会堆积在局部聚合节点上。
局部聚合完成后,数据根据分组字段进行节点间的数据重分布,执行最终(FINAL)聚合。
局部聚合后的结果会通过网络传输到下游Stage的节点(更多关于Stage的信息,请参见影响查询性能的因素)。因为数据已经经过了局部聚合,所以需要网络传输的数据较少,网络压力较小。数据重分布完成后,执行最终聚合,在最终聚合节点,需要把一个分组的值及其聚合状态维护在内存中,直到所有数据处理完成,以确保某个特定的分组值没有新的数据需要处理,所以最终聚合节点可能会占用较大的内存空间。
例如执行以下的SQL分组聚合语句。
SELECT sum(A), max(B) FROM tb1 GROUP BY C,D;上述语句在进行分组聚合时,数据会首先在上游Stage的Node1和Node2节点中执行局部聚合,局部聚合的结果是partial sum(A)、partial max(B)、C、D。局部聚合的结果会通过网络传输到下游Stage的Node3和Node4节点中进行最终聚合。流程图如下。
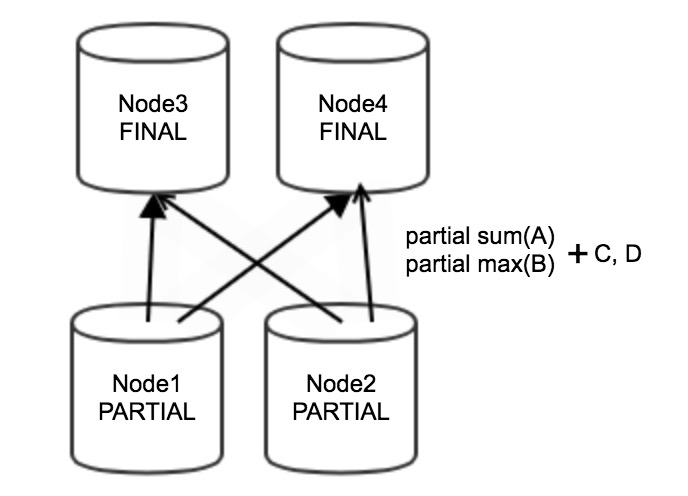
通过Hint优化分组聚合
适用场景
在大多数场景下,两步聚合可以在内存和网络资源之间实现较好的平衡,但在分组聚合的分组数较多(即GROUP BY字段的唯一值较多)等特殊场景下,两步聚合不一定是最好的处理方法。
例如,在需要使用手机号码或用户ID进行分组的场景下,如果依旧使用典型的两步聚合方式,那么在局部聚合阶段,可以被聚合的数据较少,但是局部聚合流程依旧会执行(例如,计算分组的HASH值、去重以及执行聚合函数)。由于分组数多,局部聚合阶段并没有减少网络传输的数据量,却消耗了很多计算资源。
使用方法
为解决上述聚合度较低的分组聚合查询问题,您可以在执行查询时添加Hint
/*+ aggregation_path_type=single_agg*/来跳过局部聚合,直接进行最终聚合,来减少不必要的计算开销。说明如果在查询SQL中使用了
/*+ aggregation_path_type=single_agg*/Hint,那么该SQL中所有的分组聚合查询都会使用这个特定的优化流程,因此最佳的方式是先分析原始执行计划中的聚合算子的特点,并评估该Hint带来的收益,最后决定是否使用该优化方案。优化说明
聚合度较低的情况下,上游Stage的Node1和Node2节点进行局部聚合并没有减少网络传输的数据量,却消耗了很多计算资源。
优化后Node1和Node2节点不需要进行局部聚合,全部数据(即A、B、C、D)直接由下游Stage的Node3和Node4节点进行最终聚合,从而减少了计算量,流程图如下。
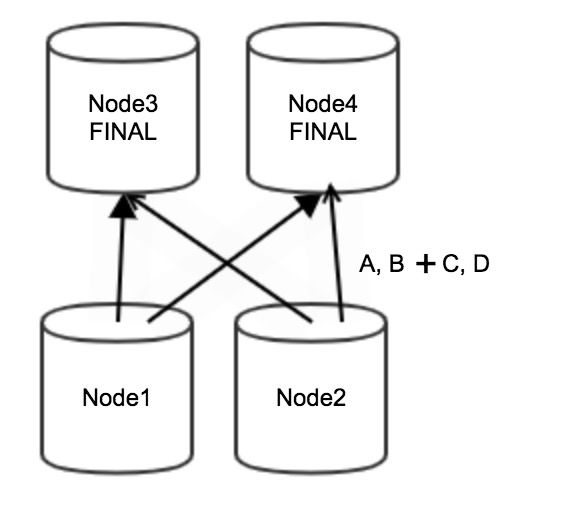 说明
说明该优化不一定能起到优化内存使用的目的,因为在聚合度较低的情况下,数据还是会大量地积攒在内存中进行去重和聚合以确保某个分组值的数据全部处理完成。