本文介绍了如何开发AnalyticDB for MySQL Spark Python作业,提供云端环境构建方案。
前提条件
集群的产品系列为企业版、基础版或湖仓版。
集群与OSS存储空间位于相同地域。
已在企业版、基础版或湖仓版集群中创建Job型资源组。
已创建AnalyticDB for MySQL集群的数据库账号。
如果是通过阿里云账号访问,只需创建高权限账号。
如果是通过RAM用户访问,需要创建高权限账号和普通账号并且将RAM用户绑定到普通账号上。
PySpark的基本用法
编写如下示例程序,并将示例程序存储为
example.py。from pyspark.sql import SparkSession if __name__ == "__main__": spark = SparkSession.builder.getOrCreate() df = spark.sql("SELECT 1+1") df.printSchema() df.show()将
example.py程序上传到OSS中。具体操作,请参见控制台上传文件。进入Spark开发编辑器。
登录云原生数据仓库AnalyticDB MySQL控制台,在左上角选择集群所在地域。在左侧导航栏,单击集群列表,然后单击目标集群ID。
在左侧导航栏,单击 。
在编辑器窗口上方,选择Job型资源组和Spark作业类型。本文以Batch类型为例。
在编辑器中执行以下作业内容。
{ "name": "Spark Python Test", "file": "oss://testBucketName/example.py", "conf": { "spark.driver.resourceSpec": "small", "spark.executor.instances": 1, "spark.executor.resourceSpec": "small" } }参数说明请参见参数说明。
使用Python依赖
在运行 Python 作业(PySpark)时,通常需要安装 Pandas、Numpy 等第三方库。本文将提供两种无需本地打包的云端环境构建方案。
方案类型 | 适用场景 | 方案优缺点 |
实时安装 |
| 优点:配置简单,即配即用。 缺点:每次运行都要重新下载安装依赖。 |
云端构建 |
| 优点:一次打包,永久复用;运行时启动快,稳定性高。 缺点:需要额外运行一次打包任务。 |
前提条件
在配置云端环境之前,请确保满足以下条件:
集群状态:集群已初始化,且能够成功运行基础的 Spark Pi 示例。
版本要求:
Spark 版本:支持 3.5.1。
Python 版本:支持 3.9 或 3.11。
关键约束(Numpy 版本):
Apache Spark 必须运行在 numpy < 2.0.0 的环境下。
系统会强制固定安装 numpy==1.26.0。
操作注意:请确保您要安装的其他依赖包(如 Pandas、Scipy 等)能兼容 Numpy 1.26.0,否则任务会报错。
操作示例
实时安装
准备业务代码
编写 Python 脚本(例如 job.py),并将其上传到 OSS 路径,例如
oss://your-bucket/scripts/job.py。# 示例脚本,会打印出当前python环境中的所有依赖。 # print all modules in python environment import pkgutil if __name__ == "__main__": for module_info in pkgutil.iter_modules(): print(module_info.name)配置作业参数
## 示例作业 { "file": "oss://your-bucket/scripts/job.py", // 代码路径 "name": "Real-time Env Demo", "conf": { "spark.adb.version": "3.5", "spark.driver.resourceSpec": "medium", "spark.executor.instances": 1, "spark.executor.resourceSpec": "medium", // --- 核心配置开始 --- // 1. 设置 Python 版本 "spark.kubernetes.driverEnv.PYTHON_BIN": "python3.11", "spark.executorEnv.PYTHON_BIN": "python3.11", // 2. 设置需要安装的依赖包 (Driver 和 Executor 都要配) "spark.kubernetes.driverEnv.PYTHON_MODULES": "chinesecalendar>=1.10.0,pandas>=1.5.3,lunar_python", "spark.executorEnv.PYTHON_MODULES": "chinesecalendar>=1.10.0,pandas>=1.5.3,lunar_python" // --- 核心配置结束 --- } }重要Spark 分为 Driver(控制节点)和 Executor(执行节点)。为了保证环境一致,必须同时为这两者配置相同的环境变量。
参数
参数说明
是否必填
默认值
备注
spark.kubernetes.driverEnv.PYTHON_MODULES
需要安装的包名列表。
是
无
多个Python依赖使用逗号隔开。
python依赖的格式需要完全符合
PyPI社区要求的格式。没有版本约束的Python依赖必须放置在最后。
示例:
chinesecalendar>=1.10.0,dynaconf>=3.2.10,pandas>=1.5.3,lunar_pythonspark.executorEnv.PYTHON_MODULES
spark.kubernetes.driverEnv.PYTHON_BIN
指定使用的Python版本。
否
python3.11
当前有两个可选项:
python3.11
python3.9
spark.executorEnv.PYTHON_BIN
spark.kubernetes.driverEnv.INDEX_URL
指定
PyPI仓库的地址。否
http://mirrors.cloud.aliyuncs.com/pypi/simple/
默认值为阿里云内部托管镜像的地址,可以使用阿里云内网访问。如果配置为公网才能访问的地址,如清华大学的PyPI镜像源,需配置公网访问能力,详情请参见Spark应用访问公网配置说明。
spark.executorEnv.INDEX_URL
spark.kubernetes.driverEnv.TRUSTED_HOST
指定
PyPI仓库的域名为可信任域名。否
mirrors.cloud.aliyuncs.com
当Python从PyPI仓库安装依赖包时,会对仓库的证书进行可信验证。如果指定的仓库证书没有被证书服务托管,可以通过此参数指定此仓库源是一个可信源。
重要在使用此参数时,请务必确认配置的PyPI源是可信的。PyPI源注入污染依赖包攻击是非常常见的攻击方式。
spark.executorEnv.TRUSTED_HOST
执行示例作业。可以查看日志信息中打印出来Python环境中,包含了声明的依赖及其级联依赖。
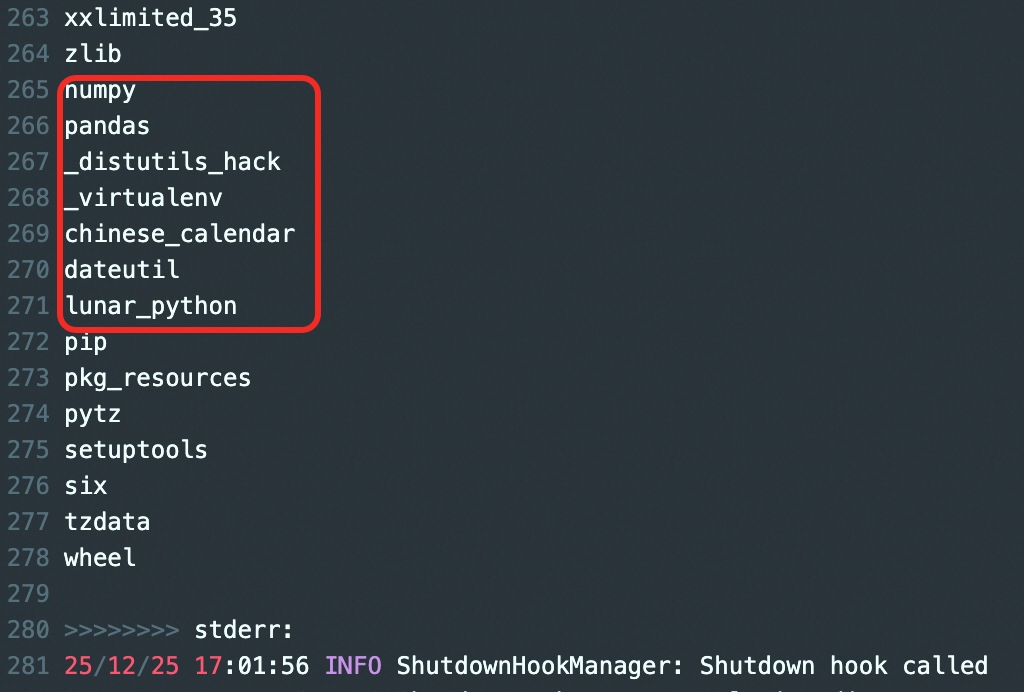
云端构建
此方案会启动一个特殊任务:将依赖包打成压缩文件上传到 OSS,供后续任务重复使用。
规划 OSS 路径
确定一个 OSS 路径用于存放打好的包,例如:
oss://your-bucket/envs/my_custom_env。提交打包作业
重要请勿修改内置打包脚本路径
local:///opt/tools/build_venv.py。args中填入需要安装的依赖。
## 示例作业 { // 1. 这里填写需要打包的所有依赖 "args": [ "chinesecalendar>=1.10.0", "pandas>=1.5.3", "pyarrow>=19.0.1", "lunar_python" ], // 2. 调用内置打包脚本 (不要修改) "file": "local:///opt/tools/build_venv.py", "name": "Build VirtualEnv Job", "conf": { "spark.driver.resourceSpec": "medium", "spark.executor.instances": 1, "spark.executor.resourceSpec": "medium", // 3. 指定 Python 版本 "spark.kubernetes.driverEnv.PYTHON_BIN": "python3.11", // 4. 指定打包结果上传到哪里(按实际路径修改) "spark.kubernetes.driverEnv.VENV_OSS_PATH": "oss://your-bucket/envs/my_custom_env", // 5. 指定构建时的临时目录 "spark.kubernetes.driverEnv.VENV_DIR": "/tmp/build_test" } }参数
参数说明
是否必填
默认值
备注
spark.kubernetes.driverEnv.VENV_OSS_PATH
环境包存储路径。
是
无
示例:
oss://your-bucket/envs/my_custom_env。spark.kubernetes.driverEnv.VENV_DIR
临时构建目录。
否
/tmp/venv
若环境包体积较大,建议挂载数据盘并修改此路径为:
/user_data_dir。spark.kubernetes.driverEnv.PYTHON_BIN
指定使用的Python版本。
否
python3.11
当前有两个可选项:
python3.11
python3.9
spark.kubernetes.driverEnv.INDEX_URL
指定
PyPI仓库的地址。否
http://mirrors.cloud.aliyuncs.com/pypi/simple/
默认值为阿里云内部托管镜像的地址,可以使用阿里云内网访问。如果配置为公网才能访问的地址,如清华大学的PyPI镜像源,需配置公网访问能力,详情请参见Spark应用访问公网配置说明。
spark.kubernetes.driverEnv.TRUSTED_HOST
指定
PyPI仓库的域名为可信任域名。否
mirrors.cloud.aliyuncs.com
当Python从PyPI仓库安装依赖包时,会对仓库的证书进行可信验证。如果指定的仓库证书没有被证书服务托管,可以通过此参数指定此仓库源是一个可信源。
重要在使用此参数时,请务必确认配置的PyPI源是可信的。PyPI源注入污染依赖包攻击是常见的攻击方式。
执行作业
可以查看日志信息中上传压缩包的信息,以及这个virtualenv中所有安装包的详细的版本说明。
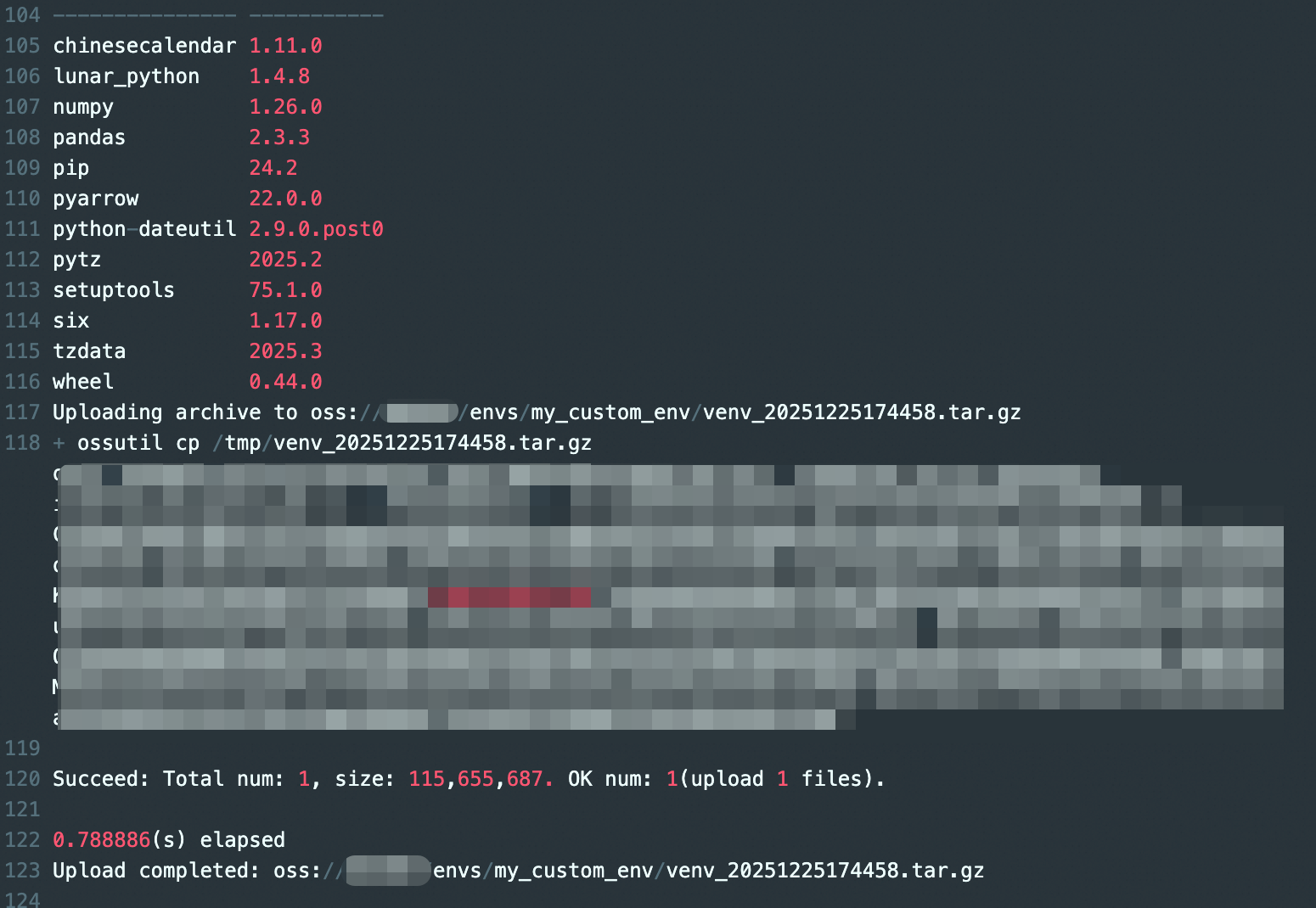
使用环境包
后续您在运行普通 PySpark 任务时,即可引用
oss://your-bucket/envs/my_custom_env中的压缩包。通过配置
pyFiles参数进行使用。## 使用示例 { "name": "Spark Python", "file": "oss://testBucketName/example.py", "pyFiles": ["oss://your-bucket/envs/my_custom_env/venv_*****.tar.gz"], "args": [ "oss://testBucketName/staff.csv" ], "conf": { "spark.driver.resourceSpec": "small", "spark.executor.instances": 2, "spark.executor.resourceSpec": "small" } }
常见问题排查
报错 ModuleNotFoundError:
检查是否同时配置了
driverEnv和executorEnv。检查包名拼写是否符合 PyPi 规范。
报错与 numpy 相关:
检查您的依赖包版本是否要求 numpy >= 2.0.0。如果是,请降级您的依赖包版本以适配 numpy 1.26.0。
下载超时:
如果使用默认内网源仍然超时,请检查是否配置了公网源但未开通公网访问权限。