玄武分析型存储引擎为用户提供高可靠、高可用、高性能、低成本的企业级数据存储能力,是云原生数据仓库 AnalyticDB MySQL 版实现高吞吐实时写入、高性能实时查询的基础支撑。
玄武分析型存储引擎(XUANWU)
高吞吐实时写入
AnalyticDB for MySQL通过三层并行架构实现了极强的吞吐能力,从接入层、到存储节点层再到持久分布式存储层,都可以并行扩展,再结合行列混合存储引擎,增量和全量的异步转换实现了高吞吐、高并发实时写入。
在实时可见性方面,AnalyticDB for MySQL通过Raft一致性协议+同步写入Apply的方式,实现了写入立即可查,保证写入一致性。存储引擎上Mark-for-delete技术实现了高吞吐量的实时更新和删除,同时基于MVCC的技术保证数据原子性和完整性。

行列混合存储
玄武存储引擎支持行列混存的存储格式,其中行列混存是一种以列存为基础兼顾行存的模式,类似于Hadoop中的ORC/Parquet格式。不同的是玄武的行列混存不仅兼顾分析类的列裁剪和大吞吐扫描性能,而且结合其行对齐的能力,可以实现很好的随机查找性能,这对于任意多维索引过滤的场景也拥有出色的性能优势。
行列混存的存储格式如下:

自适应索引
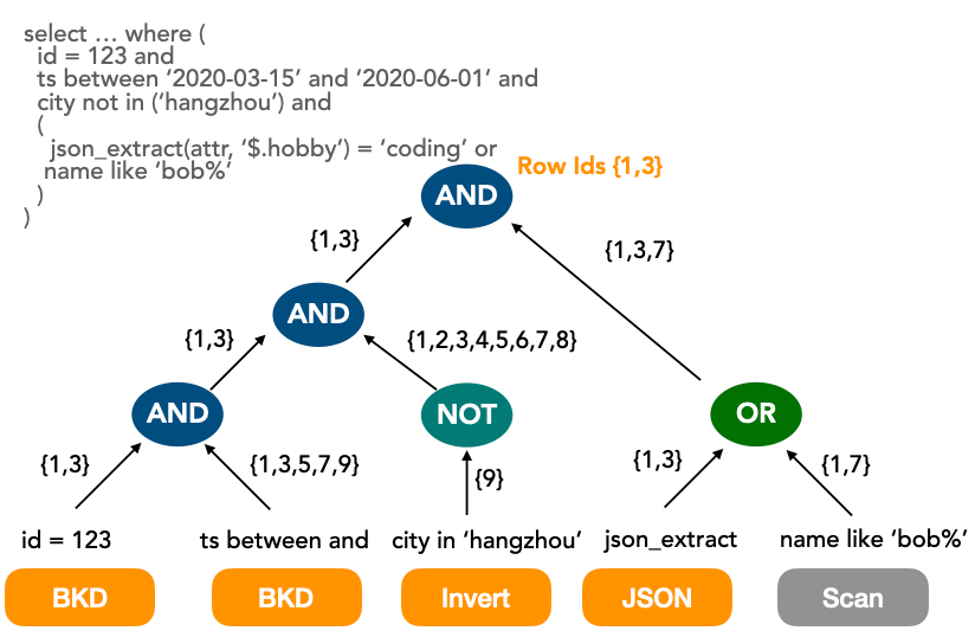
OLAP场景下需要支持任意维度查询,传统的OLTP单列或组合索引难以满足该需求。玄武采用了自适应列级自动索引技术,针对字符串、数字、文本、JSON、向量等列类型都有自动配置的索引数据结构,并且可以做到列级索引任意维度组合检索、多路渐进流式归并,大幅提升了数据过滤性能。
目前索引类型主要有:倒排索引、BKD-Tree索引和Bitmap索引。同时索引的性能主要受数据分布特征影响,包括:cardinality(散列程度),范围查询的记录数/表记录数。在某些情况下,例如age > 0 and age <100这种查询走索引的开销反而比扫描高。因此玄武基于CBO智能选择索引或扫描。
多种索引类型多路归并查找的过程如下所示:
结构化与非结构化融合
玄武存储层索引管理器实现结构化索引与非结构化索引的统一管理,如数值类的BKD索引、字符串类的倒排索引、非结构化的JSON索引及向量索引,还有文本数据的全文索引。对计算层提供统一的表达式,使得计算层的SQL逻辑兼容异构数据类型,同时都得到索引加速。因此AnalyticDB for MySQL实现了全文数据与结构化表之间的关联分析,SQL表达的复杂逻辑都能够统一支持。如下图所示:

SQL语义说明:对子查询里的全文检索的结果集进行关联分析,分析后的结果按照打分值降序排列,输出前10,000行。
玄武分析型存储引擎V2(XUANWU_V2)
AnalyticDB for MySQL基于原玄武分析型存储引擎迭代研发出新一代存储引擎XUANWU_V2。
高效的数据组织方式
XUANWU_V2优化了数据组织方式。数据以Append方式写入实时引擎,经过Flush任务,再写入读友好的全量引擎中。随后,通过Compaction任务全量引擎层级内或层级间的合并,确保L0以下层级的分区有序,并按照固定大小进行数据物理组织。
数据组织方式如下图所示:

该数据组织方式可以保证实时引擎能及时的构建为读友好的全量引擎,提高查询性能。同时,它显著改善了Compaction过程的读放大问题,进一步降低了Compaction过程中的CPU和IO消耗。此外,在这种组织方式下,XUANWU_V2可以自适应地对过大或者过小的分区文件进行切分与合并,用户无需再为分区键的选择而困扰。
高效的存储格式
XUANWU_V2在原有按固定行数组织的列级IO块基础上,引入了按固定大小组织IO块的文件格式。这种固定大小的IO块组织方式,不仅优化了IO和内存管理,解决了因行对齐与IO大小不一致所引发的一系列问题,也提高了内存复用效率,降低了内存申请与回收的开销。通过对齐内存与IO操作,进一步减少了读放大的现象,进而降低了IO成本。

更好的水平扩容弹性
XUANWU_V2将所有数据存储在OSS中,不仅显著降低了用户存储成本,还大幅提升了水平扩缩容和节点迁移的效率。XUANWU_V2采用ESSD云盘作为查询缓存,支持DDL指定分区预热和查询自动缓存两种形式,有效提升了查询性能。