SysOM(System Observer Monitoring)是一种在操作系统内核层提供容器监控可观测能力的方法,支持容器化部署、迁移及监控。本文介绍如何开启和使用ack-sysom-monitor功能,并说明相关监控指标。
前提条件
已创建ACK托管版集群或自2021年10月以后创建的ACK Serverless集群,并确保集群版本为1.18.8及以上。如需升级集群,请参见手动升级集群。
已开启阿里云Prometheus监控。
ack-sysom-monitor组件介绍
ack-sysom-monitor是SysOM的监控组件,基于eBPF技术实现内核级指标采集,覆盖节点和容器维度。除基础系统指标外,还提供深度增强指标,可检测系统抖动、延迟、资源泄漏及Pod内存异常等典型问题场。
ack-sysom-monitor监控功能费用说明
启用ack-sysom-monitor监控功能后,相关组件会自动将监控指标发送至阿里云Prometheus服务,这些指标将被视为自定义指标。使用自定义指标会引起额外的费用。
为避免产生额外的费用,建议在启用此功能前,仔细阅读阿里云Prometheus的计费概述,了解自定义指标的收费策略。费用将根据您的集群规模和应用数量等因素产生变动。您可以通过资源消耗统计功能,监控和管理您的资源使用情况。
开启ack-sysom-monitor监控功能
登录ARMS控制台。
在左侧导航栏,单击接入中心。
在接入中心页面的基础设施区域,单击SysOM 系统观测。
在SysOM 系统观测面板的开始接入页签,选择待接入的容器集群,然后单击确定。
使用ack-sysom-monitor监控功能
操作步骤
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
在Prometheus 监控页面,单击SysOM系统观测页签查看ack-sysom-monitor监控功能。
ack-sysom-monitor提供节点维度、Pod维度的操作系统内核级监控。
节点维度操作系统内核级监控
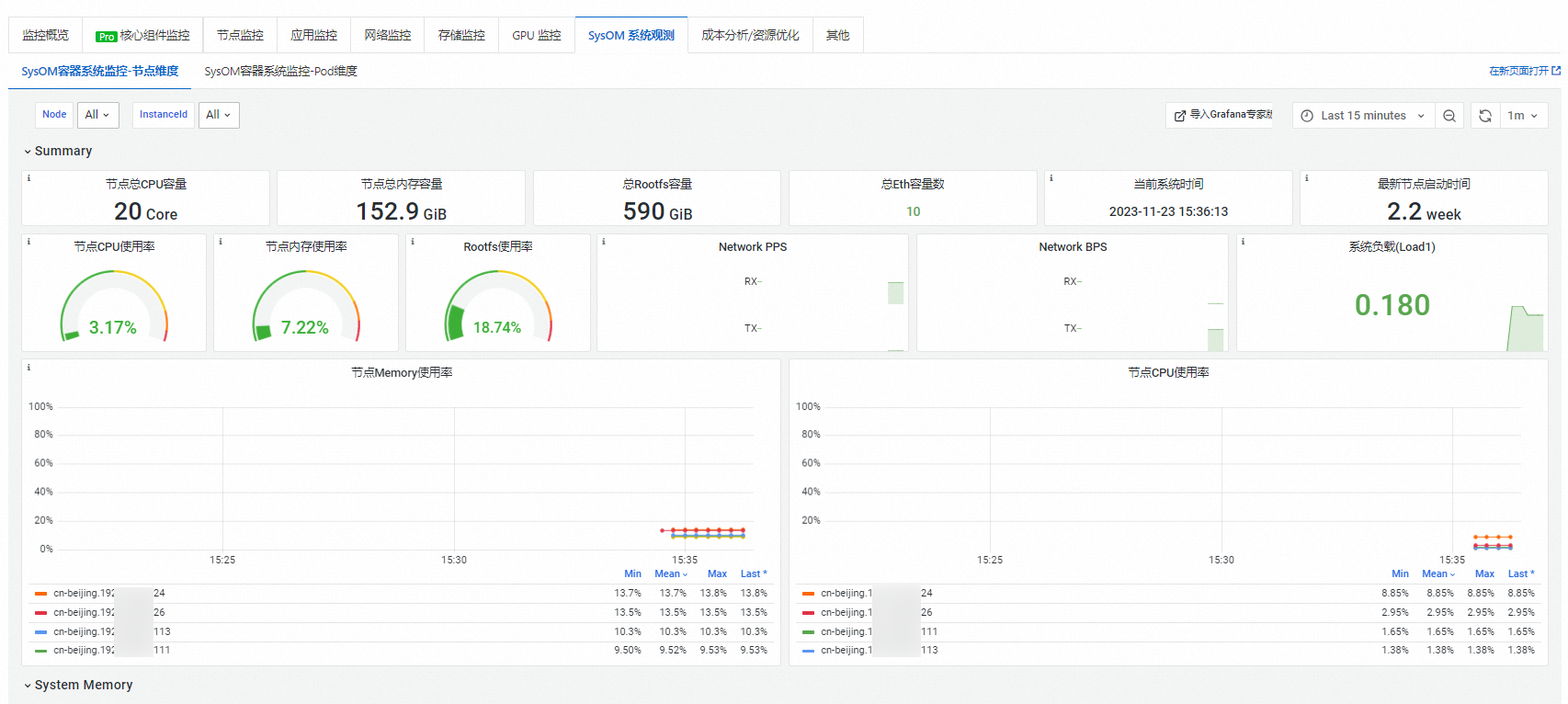
在SysOM容器系统监控-节点维度页签,您可以从节点维度监控内存、CPU和调度、存储、网络等模块的指标。
Pod维度操作系统内核级监控
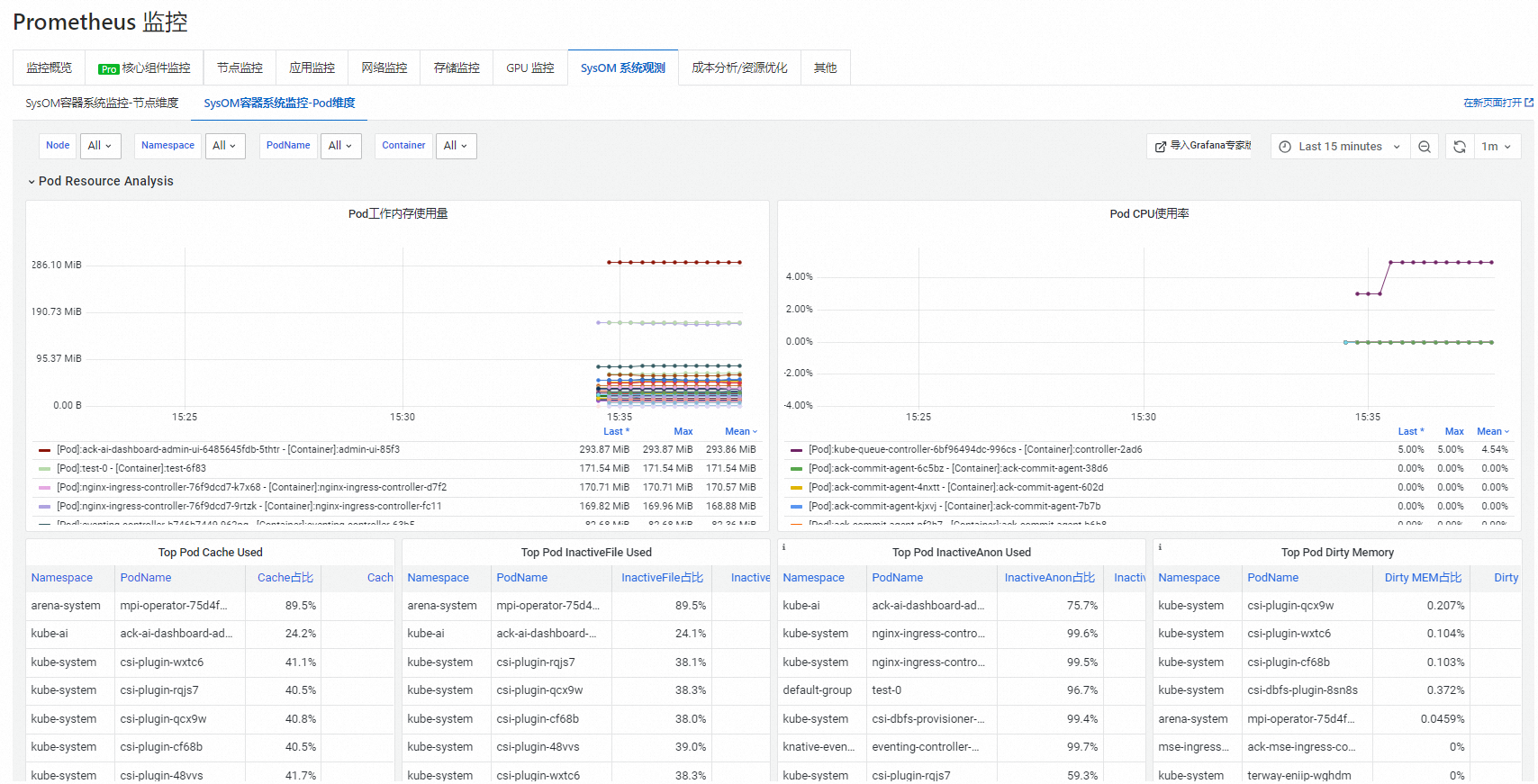
在SysOM容器系统监控-Pod维度页签,您可以从Pod维度实时监控内存、CPU、网络、IO等模块的指标。
相关操作
如需关闭SysOM内核层容器监控,您可以卸载ack-sysom-monitor组件,避免产生额外计费。操作路径,请参见管理组件。
指标说明
ack-sysom-monitor的监控指标格式按照标准Prometheus指标格式定义。
节点指标
节点指标可以分为CPU、内存、存储、网络及其他指标。
CPU和调度相关指标
指标名称 | 指标类型 | 单位 | 说明 |
sysom_proc_cpu_total | gauge | % | 查看节点总体CPU运行时间占比情况。 表示每种状态下系统所有CPU的运行时间占CPU总运行时间的比率。这些状态包括用户态、内核态、软中断(softirq)、硬中断(hardirq)、空闲(idle)和I/O等待(iowait)。 |
sysom_proc_cpus | gauge | % | 查看节点某个CPU的运行时间占比情况。 表示某个CPU在不同系统状态下的运行时间占CPU总运行时间的比率。这些状态包括CPU在用户态、内核态、软中断(softirq)、硬中断(hardirq)、空闲(idle)和I/O等待(iowait)。 |
sysom_proc_sirq | gauge | % | 查看节点的软中断情况。 表示各种类型的软中断(softirq)在系统中发生的次数。其中统计的软中断类型包括HI(高优先级)、TIMER(定时器)、NET_TX(网络发送)、NET_RX(网络接收)、BLOCK(块设备)、IRQ_POLL(中断轮询)、TASKLET(任务队列)、SCHED(调度器)、HRTIMER(高分辨率定时器)和RCU软中断。 |
sysom_proc_stat_counters | gauge | - | 查看节点是否存在过多的D状态进程,以了解系统的负载情况。 表示系统中处于不同状态(Running、D状态)的进程数量。同时,它还提供系统启动时间以及上下文切换次数。 |
sysom_proc_loadavg | gauge | - | 节点的平均负载情况。 表示系统的平均负载(load average)值,包括系统的运行队列(runq)长度、最近1分钟的平均负载值、最近5分钟的平均负载值、最近15分钟的平均负载值以及系统总进程数。 |
sysom_proc_schedstat | gauge | ns(纳秒) | 查看节点的调度延迟情况。 该指标提供了与CPU调度相关的统计数据,包括在当前CPU的调度队列中等待被调度运行的进程的消耗时间,以及当前CPU中运行的时间片长度。 |
sysom_cpu_dist | gauge | - | 查看节点的总体调度情况。 该指标提供了从进程让出CPU到下一次被调度到CPU上运行所用时间的统计情况。包括了在不同时间间隔(1us、10us、100us、1ms、10ms、100ms、1s)内,系统中所有进程从让出CPU到下一次被调度到CPU上运行的次数。 |
内存相关指标
指标名称 | 指标类型 | 单位 | 说明 |
sysom_proc_meminfo | gauge | KiB | 查看节点各种类型内存的占用情况。 该指标支持查看内存的占用情况,包括但不限于系统总内存(Total)、剩余内存(Free)、可用内存(Available)、页缓存(Cache)、块缓存(Buffers)、可回收内存(SReclaimable)、不可回收内存(SUnreclaim)。 |
sysom_proc_vmstat | gauge | - | 查看节点具体的内存使用情况和内存事件情况。 该指标用于表示系统中以页为单位的系统内存统计数据,以及一些内存事件的统计。内存信息和事件统计包括:系统空闲页数(Free Pages)、脏页数(Dirty Pages)、从磁盘读入/写出的页数(Pages Read/Write)、从Inactive链表中回收的页数(Pages Reclaimed from Inactive List)、OOM(Out of Memory)Kill次数。 |
sysom_proc_buddyinfo | gauge | - | 查看节点内核内存管理中伙伴(Buddy)系统的分配和释放情况的统计数据。 该指标提供了有关内核伙伴系统的详细信息,包括系统中所有内存节点(Node)和区域(Zone),以及不同页块大小的伙伴系统链表中的页块数量。 |
存储相关指标
指标名称 | 指标类型 | 单位 | 说明 |
sysom_proc_disks | gauge | - | 查看节点上每个磁盘和分区的读取、写入、I/O请求和延时等统计数据,从而了解节点的I/O情况。 该指标提供系统中有关磁盘和分区的统计信息,具体包括磁盘分区完成的读写请求数、读写请求总共花费的时间、合并的读写请求次数、设备中未完成(Inflight)的I/O数量等。 |
sysom_fs_stat | gauge | - | 查看节点上已挂载的文件系统的使用情况。 该指标提供系统中各文件系统的用量统计信息,具体包括文件系统的挂载点、块大小、已用和可用块数、已用和可用的Inode数量等信息。 |
网络相关指标
指标名称 | 指标类型 | 单位 | 说明 |
sysom_proc_networks | gauge | - | 查看节点各网卡的流量情况。 该指标提供系统中各网卡的流量统计信息,具体包括网卡发送/接收的数据包总数、总字节数、发送/接收时设备驱动程序丢弃的数据包总数、发送/接收数据包时错误总数等。 |
sysom_proc_pkt_status | gauge | - | 查看节点网络协议栈处理数据包的整体情况。 该指标提供系统中网络数据包通过网络协议栈时发生的事件次数,包括在网络协议栈中丢包的次数、发生栈溢出的次数、发生断言失效的次数等。 |
sysom_sock_stat | gauge | - | 该指标可以帮助发现由于应用逻辑、系统参数配置等问题导致的套接字和缓冲区耗尽等情况。 该指标提供有关节点套接字和其缓冲区使用情况的统计信息,包括total/raw/tcp/udp的socket使用量、TCP time wait/orphan状态的socket数量、TCP/UDP socket的内存使用量等。 |
sysom_softnets | gauge | - | 查看节点每个CPU网卡软中断接收数据包的情况。 该指标提供系统中网络软中断相关统计数据,包括某个CPU在软中断中收包和丢包个数、网络收包软中断处理函数net_rx_action调用次数等。 |
sysom_net_health_hist | gauge | - | 查看节点中所有TCP连接的往返时延分布,从而了解TCP链路的时延情况。 该指标提供了节点中所有TCP连接的往返时延分布信息。具体而言,它包括经过平滑处理的RTT(Round Trip Time)时间在不同时间范围内的次数统计,例如在10ms、100ms和1s内的次数。 |
sysom_net_health_count | gauge | - | 与 |
sysom_net_retrans_count | gauge | - | 查看节点中所有TCP连接的重传情况,并快速了解产生重传的原因。 该指标提供系统中TCP连接发生重传的数据包类型以及对应的数目,包括因为RTO(Retransmission Timeout)超时引起重传的数据包数目和不同类型数据包重传数目(例如Syn、Syn-ack、Reset等)。 |
sysom_net_tcp_count | gauge | - | 查看节点中TCP连接的基本情况。 该指标提供系统中TCP连接相关的统计数据,具体包括系统中已建立并且处于活跃状态的TCP连接数,接收/发送的TCP segment数目、重传的TCP segment数目以及接收端发生错误的数据包数目。 |
sysom_net_udp_count | gauge | - | 查看节点中UDP连接的基本情况。 该指标提供系统中UDP连接相关的统计数据,包括系统中发送/接收的UDP数据包数目、UDP发送/接收缓冲区发生错误的次数以及因为无可用端口导致的错误数据包数目。 |
sysom_net_ip_count | gauge | - | 查看节点中IP层的基本情况。 该指标提供系统中IP层相关的统计数据,包括系统中转发、接收和发送的IP数据包数量。 |
sysom_net_icmp_count | gauge | - | 查看节点中ICMP协议的基本情况。 该指标提供系统中ICMP协议相关的统计数据,包括系统中ICMP发送/接收的数据包数目、发送/接收错误的数据包数目。 |
其他系统指标
指标名称 | 指标类型 | 单位 | 说明 |
sysom_cgroups | gauge | - | 查看系统中各CGroup子系统使用的CGroup数量,观察是否有CGroup泄露的情况。 该指标提供系统中各CGroup子系统下的CGroup数量,包括CPU、Cpuacct、Memory、Pids、Blkio、Devices等CGroup子系统目录下CGroup数量。 |
sysom_uptime | gauge | s(秒) | 通过该指标可以一定程度地了解系统的负载程度。 指标表示系统启动到当前经过的时间和系统空闲的时间。 |
容器指标
容器指标可以分为CPU、内存、IO、网络及其他指标。
CPU和调度相关指标
指标名称 | 指标类型 | 单位 | 说明 |
sysom_container_cpu_stat | gauge | - | 可以监视和评估是否需要调整资源配额或进行其他优化。 该指标提供有关容器中CPU资源限制的统计信息,包括CGroup中发生CPU周期性限制次数、发生CPU限制的次数、发生CPU限制的总时间。 |
sysom_container_cpu_acctstat | gauge | % | 查看容器的具体CPU使用情况。 该指标提供容器中所有任务在各个模式下运行的CPU使用率,包括容器在用户态(User)、内核态(Kernel)以及总体的CPU使用率。 |
sysom_container_cpu_cfsquota | gauge | - | 查看容器受CFS调度器限制的运行时间情况。 该指标提供容器在每一个CFS调度时间窗口中可以运行的时间,包括cfs_period_us和cfs_quota_us。
|
内存相关指标
指标名称 | 指标类型 | 单位 | 说明 |
sysom_container_memory_stat | gauge | KiB | 查看容器各种类型的内存占用情况。 该指标提供有关容器内存使用情况的统计信息,包括容器的总内存(Total)、剩余内存(Free)、可用内存大小(Available)、页缓存(Cache)、块缓存(Buffers)、共享内存(Shmem)、可回收内存(SReclaimable)、不可回收内存(SUnreclaim)的占用情况等。 |
sysom_container_memory_filecache | gauge | KiB | 通过该指标可以快速了解容器中文件缓存的占用情况,从而定位因为容器文件缓存占用过多导致的内存紧缺和内存延时抖动问题。 该指标提供有关容器中文件缓存(Page Cache)使用情况的统计信息,包含每个容器中占用文件缓存最多的10个文件,以及它们的大小和占用的文件缓存大小。 |
sysom_container_memory_gdrcm_latency | gauge | 次 | 查看容器中是否存在因直接内存回收产生的延时次数和延时的时间,且直接内存回收是因为节点内存紧张导致的。 该指标提供有关容器中因直接内存回收产生的延迟时间和次数的统计信息,包括1~5毫秒的延迟次数、5~10毫秒的延迟次数、10~100毫秒的延迟次数、100~500毫秒的延迟次数、500~1000毫秒的延迟次数、大于1000毫秒的延迟次数。 |
sysom_container_memory_cdrcm_latency | gauge | 次 | 查看容器中是否存在因直接内存回收产生的延时次数和延时时间,且直接内存回收是因为当前内存控制组(Memory CGroup)紧张导致的。 说明 该指标只有在当前内存控制组是非根(Non-Root)控制组,或者当前内存控制组设置了内存上限时才有意义。 该指标提供有关容器中因直接内存回收产生的延迟时间和次数的统计信息,包括直接内存回收延时1~5毫秒的延迟次数、5~10毫秒的延迟次数、10~100毫秒的延迟次数、100~500毫秒的延迟次数、500~1000毫秒的延迟次数、大于1000毫秒的延迟次数。 |
sysom_container_memory_cpt_latency | gauge | 次 | 查看容器中进程申请内存时是否存在因为节点内存紧张、内存碎片过多引起内核内存规整动作导致的延时。 该指标提供由于直接内存规整导致的延时次数和延时时间的统计信息,包括1~5毫秒的延迟次数、5~10毫秒的延迟次数、10~100毫秒的延迟次数、100~500毫秒的延迟次数、500~1000毫秒的延迟次数、大于1000毫秒的延迟次数。 |
IO相关指标
指标名称 | 指标类型 | 单位 | 说明 |
sysom_container_blkio_stat | gauge | - | 查看容器的基本IO情况。 该指标提供容器在对应磁盘中的IO统计数据,包括容器在对应磁盘中发起的读/写IO请求数、请求字节数、进入排队队列的读/写IO请求数、请求字节数以及读/写IO等待的时间等。 |
网络相关指标
指标名称 | 指标类型 | 单位 | 说明 |
sysom_container_network_stat | gauge | - | 查看容器的基本网络流量情况。 该指标提供容器在虚拟网卡中的流量统计数据,包括容器在虚拟网卡中发送/接收的数据包数目、字节数以及丢包数(丢包只包含被虚拟网卡设备层的丢包数,不包含网络协议栈的丢包)。 |