在CPU与GPU间通信频繁的场景下,跨NUMA(Non-Uniform Memory Access)节点访问会导致延迟增加、带宽受限等问题,从而影响系统整体性能。为了解决此类问题,ACK基于Scheduler Framework机制,实现NUMA拓扑感知调度,将Pod调度到最佳的NUMA节点上,从而减少跨NUMA节点的访问以优化性能。
工作原理
NUMA节点是构成非一致性内存访问(NUMA)系统的基本单位,一个NUMA集合是指单个Node节点上多个NUMA节点的组合,用于实现计算资源的有效分配,并降低处理器间内存访问的竞争。在8 GPU卡机器,即配备了8块GPU卡的高性能机器中,通常包含多个NUMA节点。当CPU没有绑核或CPU没有与GPU分配在相同NUMA上时,可能会由于CPU争抢或CPU与GPU跨NUMA通信导致应用执行性能下降。为了使应用的执行性能最大化,您可以选择将CPU与GPU绑定在相同NUMA下。
原生的基于kubelet CPU Policy以及NUMA Topology Policy的方案能够在单机上实现将CPU与GPU绑定在相同NUMA上的效果,但是在集群中使用时会存在一些难点:
放置结果调度器不感知:调度器无法感知到节点上已分配的具体CPU以及GPU,继而无法判断剩余的CPU与GPU资源是否能够满足Pod的QoS要求,导致调度后大量出现AdmissionError状态的Pod,严重时可能导致集群崩溃。
放置效果上层不可控:由于kubelet拓扑分配策略在原生Kubernetes中只能在节点的进程启动参数里看到,无法通过节点标签等集群层面手段获取。因此,在提交任务时,您无法指定工作负载运行在支持联合分配的节点上,导致应用的实际运行效果具有较大的波动性。
拓扑策略使用复杂:NUMA拓扑策略通过节点进行声明,因此单一节点上只能承载一种拓扑策略。提交任务并使用拓扑策略前,集群资源管理员需要手动划分集群,在节点上进行特殊标记,且任务Pod上也需要声明带有特殊标记的节点亲和。此外,不同策略的Pod即使相互之间没有干扰也无法放置于相同节点上,导致集群利用率下降。
为了解决上述问题,ACK基于Scheduler Framework实现了拓扑感知调度能力,同时采用自主研发的gputopo-device-plugin以及ack-koordinator组件的ack-koordlet完成节点CPU、GPU拓扑结构上报,并且支持在工作负载上声明NUMA拓扑分配策略的能力,解决了原生kubelet方案中存在的不足。整体方案架构如下所示。

前提条件
集群要求:
节点要求:
仅支持GPU计算型超级计算集群实例规格族sccgn7ex及灵骏节点,请参见实例规格族描述。灵骏节点请参见管理灵骏集群和灵骏节点。
GPU拓扑感知调度的节点需要手动添加标签
ack.node.gpu.schedule=topology。相关信息请参见开启调度功能。
组件要求:
kube-scheduler组件版本需高于6.4.4版本。相关介绍,请参见kube-scheduler。如果您需要升级kube-scheduler组件,请在容器服务控制台单击目标集群,然后选择升级组件。
已安装ack-koordinator(原ack-slo-manager)。具体操作,请参见ack-koordinator(ack-slo-manager)。
ACK灵骏集群:直接完成ack-koordinator组件的安装。
ACK托管集群Pro版:配置ack-koordinator参数时,需设置Feature Gate agentFeatures的取值为NodeTopologyReport=true。

已安装GPU拓扑感知调度组件。具体步骤,请参见安装GPU拓扑感知调度组件。
重要如果您先安装了GPU拓扑感知调度组件,然后安装了ack-koordinator组件,您需在安装ack-koordinator后重启GPU拓扑感知调度组件。
使用限制
不支持与启用CPU拓扑感知调度及GPU拓扑感知调度同时使用。
仅支持CPU与GPU设备间的联合分配。
应用Pod中的所有容器的CPU Request必须为整数(单位:Core),且Request与Limit相同。
应用Pod中容器的GPU资源通过
aliyun.com/gpu申请,目前仅支持整卡申请。
计费说明
使用该功能需要安装AI套件,可能会产生额外费用。请参见云原生AI套件计费说明。
ack-koordinator组件本身的安装和使用免费,但在以下场景中可能产生额外费用。
ack-koordinator是非托管组件,安装后将占用Worker节点资源。您可以在安装组件时配置各模块的资源申请量。
ack-koordinator默认会将资源画像、精细化调度等功能的监控指标以Prometheus的格式对外透出。若您配置组件时开启了ACK-Koordinator开启Prometheus监控指标选项并使用了阿里云Prometheus服务,这些指标将被视为自定义指标并产生相应费用。具体费用取决于您的集群规模和应用数量等因素。建议您在启用此功能前,仔细阅读阿里云PrometheusPrometheus 实例计费,了解自定义指标的免费额度和收费策略。您可以通过用量查询,监控和管理您的资源使用情况。
使用NUMA拓扑感知调度
您可以通过在Pod上增加如下Annotation来声明NUMA拓扑感知调度要求:
apiVersion: v1
kind: Pod
metadata:
name: example
annotations:
cpuset-scheduler: required # 启用绑定CPU
scheduling.alibabacloud.com/numa-topology-spec: | # 表明此Pod的NUMA拓扑需求
{
"numaTopologyPolicy": "SingleNUMANode",
"singleNUMANodeExclusive": "Preferred"
}
spec:
containers:
- name: example
image: ghcr.io/huggingface/text-generation-inference:1.4
resources:
limits:
aliyun.com/gpu: '4'
cpu: '24'
requests:
aliyun.com/gpu: '4'
cpu: '24'以下为NUMA开启拓扑感知调度相关参数:
参数 | 说明 |
| Pod需要将CPU与设备进行联合分配。 目前取值仅支持 |
| Pod调度时需要采用哪种NUMA放置策略。
|
| Pod调度时是否需要避开某些NUMA节点。 说明 NUMA节点类型:
|
开启前后性能对比
本文使用模型加载过程来测试开启NUMA拓扑感知调度前后带来的性能提升。我们将使用text-generation-inference工具在两块GPU卡上拉起模型,并使用NSight工具统计绑核前后GPU加载的速度变化。
本实验采用灵骏节点,TGI1.4版本,请参见TGI下载地址,NSight工具请参见NSight工具下载。
采用不同的工具进行测试,测试结果会存在差异。本示例中的性能对比数据仅为采用NSight工具获得的测试结果。实际数据以您的操作环境为准。
不开启拓扑感知调度
相同场景下不开启拓扑感知调度的应用YAML如下:
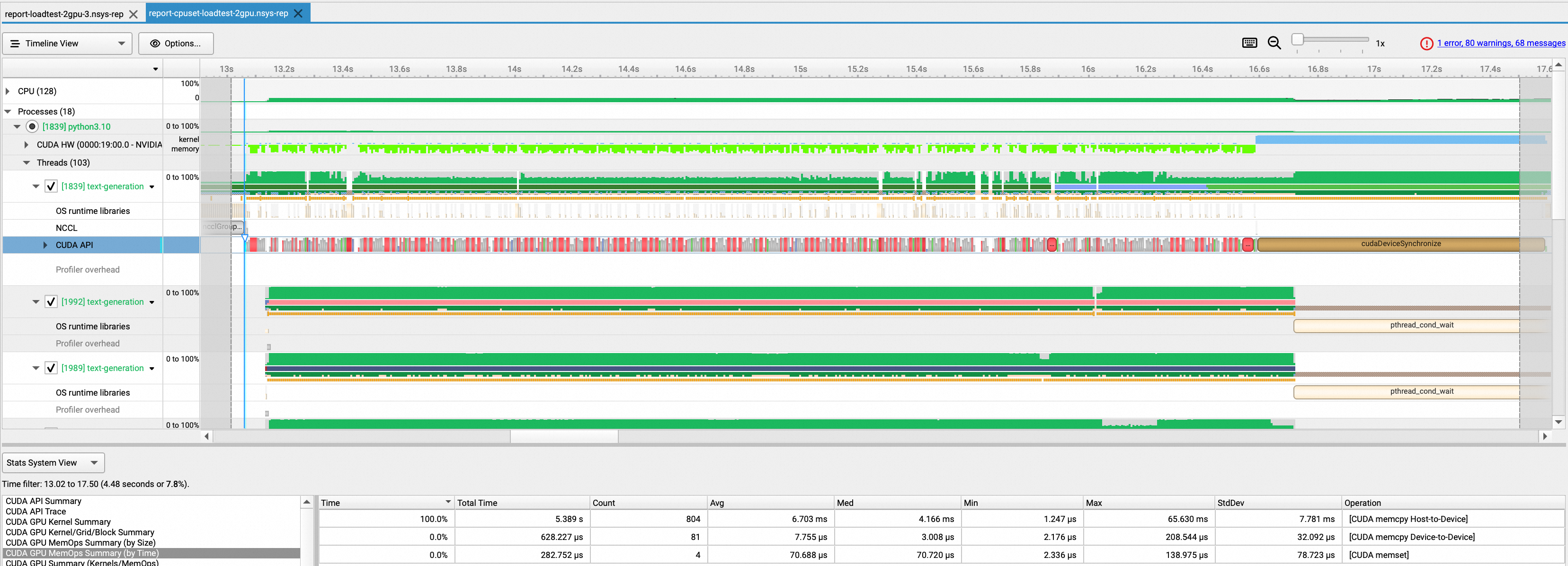
查看模型加载时间,可以看出模型完成加载需要15.9s。
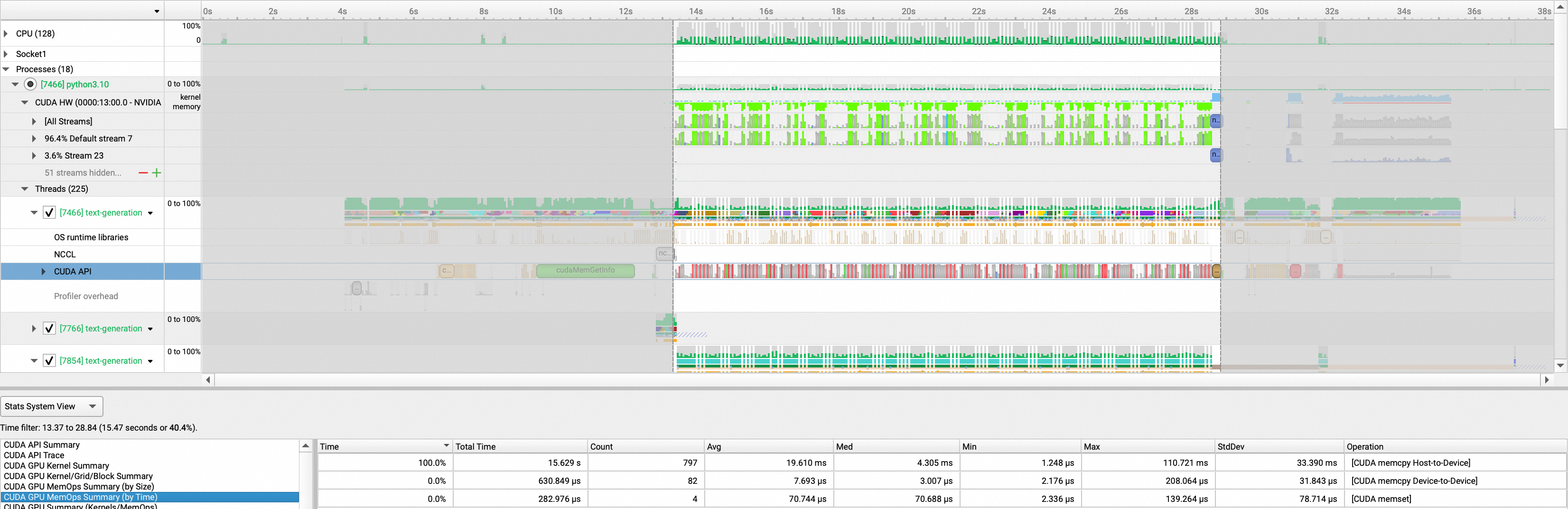
开启拓扑感知调度
相同场景下开启拓扑感知调度的应用YAML如下:
查看模型加载时间,可以看出模型完成加载需要5.4s,较未开启时提升了66%。