GPU监控基于NVIDIA DCGM实现对集群GPU节点的监控。本文将介绍如何查看基于三种不同的GPU申请方式所展现出的监控结果。
前提条件
背景信息
GPU监控支持对集群GPU节点进行全方位监控,提供集群维度、节点维度和应用Pod维度GPU监控大盘。可参见监控面板说明了解更多详细信息。
在集群维度GPU监控大盘,您可以查看集群或节点池维度的相关信息,例如集群层面的利用率、显存使用、XID错误检测等。
在节点维度GPU监控大盘,您可以查看节点维度的相关信息,例如节点中GPU详情、利用率、显存使用等。
在应用Pod维度GPU监控大盘,您可以查看Pod维度的相关信息。例如Pod申请的GPU资源、利用率等。
本文以如下流程为例,介绍三种不同的GPU申请方式所展现出的不同监控结果。

注意事项
当前GPU监控指标的采集间隔为15秒,这可能导致Grafana监控仪表盘展示的数据存在一定延迟。因此可能会出现在监控显示节点无可用显存,但实际Pod还能调度到该节点上。出现该现象可能是在两次监控采集之间(15 秒内)有Pod完成任务并释放GPU资源,调度器感知后,将处于Pending的Pod调度到这个节点上。
监控大盘只支持监控通过在Pod中配置
resources.limits的方式申请的GPU资源。更多信息,请参见为Pod和容器管理资源。节点使用GPU资源时存在以下情况,可能会导致监控大盘的数据不准确:
直接在节点上运行GPU应用。
通过
docker run命令直接启动容器运行GPU应用。在Pod的
env中直接添加环境变量NVIDIA_VISIBLE_DEVICES=all或NVIDIA_VISIBLE_DEVICES=<GPU ID>等,通过环境变量NVIDIA_VISIBLE_DEVICES直接为Pod申请GPU资源,并且运行了GPU程序。在Pod的
securityContext中配置privileged: true,并且运行了GPU程序。在Pod中未设置环境变量
NVIDIA_VISIBLE_DEVICES,但Pod所使用的镜像在制作时,默认配置环境变量NVIDIA_VISIBLE_DEVICES=all,并且运行了GPU程序。
GPU卡已分配的显存和已使用的显存不一定相同。例如某一张GPU卡共有16 GiB显存,为某个Pod分配了5 GiB显存,但Pod的启动命令为
sleep 1000,即Pod处于Running但需要经过1000秒后才会使用GPU,因此存在GPU卡已分配的显存为5 GiB,但已使用的显存为0 GiB的情况。
步骤一:创建节点池
Pod按整张卡方式或显存维度申请GPU资源(包括申请GPU算力资源),GPU监控大盘均可以展示其相关指标。
本示例将在集群中创建三个节点池,展示不同GPU资源申请模式下的Pod调度与资源占用情况。关于创建节点池的具体步骤,请参见创建节点池。节点池部分信息如下:
配置项 | 说明 | 示例值 |
节点池名称 | 节点池一的名称。 | exclusive |
节点池二的名称。 | share-mem | |
节点池三的名称。 | share-mem-core | |
实例规格 | 节点的实例规格,本文以运行Tensorflow Benchmark项目为例,需申请10 GiB显存,节点规格需大于10GiB。 | ecs.gn7i-c16g1.4xlarge |
期望节点数 | 节点池应该维持的总节点数量。 | 1 |
节点标签 | 节点池一添加的标签。表示按整张卡的维度申请GPU资源。 | 无 |
节点池二添加的标签。表示按GPU显存维度申请GPU资源。 | ack.node.gpu.schedule=cgpu | |
节点池三添加的标签。表示按GPU显存维度申请GPU资源且支持算力申请。 | ack.node.gpu.schedule=core_mem |
步骤二:部署GPU应用
节点池创建完成后,为了验证节点GPU相关指标是否正常,需要在节点上运行一些GPU测试任务。可参见GPU节点调度属性标签了解各任务所需匹配标签及调度关系。三个任务的部分信息如下:
任务名称 | 任务运行的节点池 | 申请的GPU资源 |
tensorflow-benchmark-exclusive | exclusive | nvidia.com/gpu: 1 表示申请1张GPU卡。 |
tensorflow-benchmark-share-mem | share-mem | aliyun.com/gpu-mem: 10 表示申请10 GiB显存。 |
tensorflow-benchmark-share-mem-core | share-mem-core |
表示申请10 GiB显存和1张GPU卡的30%算力。 |
创建Job文件。
使用以下YAML内容,创建tensorflow-benchmark-exclusive.yaml文件。
apiVersion: batch/v1 kind: Job metadata: name: tensorflow-benchmark-exclusive spec: parallelism: 1 template: metadata: labels: app: tensorflow-benchmark-exclusive spec: containers: - name: tensorflow-benchmark image: registry.cn-beijing.aliyuncs.com/ai-samples/gpushare-sample:benchmark-tensorflow-2.2.3 command: - bash - run.sh - --num_batches=5000000 - --batch_size=8 resources: limits: nvidia.com/gpu: 1 #申请1张GPU卡。 workingDir: /root restartPolicy: Never使用以下YAML内容,创建tensorflow-benchmark-share-mem.yaml文件。
apiVersion: batch/v1 kind: Job metadata: name: tensorflow-benchmark-share-mem spec: parallelism: 1 template: metadata: labels: app: tensorflow-benchmark-share-mem spec: containers: - name: tensorflow-benchmark image: registry.cn-beijing.aliyuncs.com/ai-samples/gpushare-sample:benchmark-tensorflow-2.2.3 command: - bash - run.sh - --num_batches=5000000 - --batch_size=8 resources: limits: aliyun.com/gpu-mem: 10 #申请10 GiB显存。 workingDir: /root restartPolicy: Never使用以下YAML内容,创建tensorflow-benchmark-share-mem-core.yaml文件。
apiVersion: batch/v1 kind: Job metadata: name: tensorflow-benchmark-share-mem-core spec: parallelism: 1 template: metadata: labels: app: tensorflow-benchmark-share-mem-core spec: containers: - name: tensorflow-benchmark image: registry.cn-beijing.aliyuncs.com/ai-samples/gpushare-sample:benchmark-tensorflow-2.2.3 command: - bash - run.sh - --num_batches=5000000 - --batch_size=8 resources: limits: aliyun.com/gpu-mem: 10 #申请10 GiB显存。 aliyun.com/gpu-core.percentage: 30 #申请1张卡的30%算力。 workingDir: /root restartPolicy: Never
执行以下命令,部署Job任务。
kubectl apply -f tensorflow-benchmark-exclusive.yaml kubectl apply -f tensorflow-benchmark-share-mem.yaml kubectl apply -f tensorflow-benchmark-share-mem-core.yaml执行以下命令,查看Pod的运行状态。
kubectl get pod预期输出:
NAME READY STATUS RESTARTS AGE tensorflow-benchmark-exclusive-7dff2 1/1 Running 0 3m13s tensorflow-benchmark-share-mem-core-k24gz 1/1 Running 0 4m22s tensorflow-benchmark-share-mem-shmpj 1/1 Running 0 3m46s由预期输出得到,Pod均处于
Running状态,表示Job任务部署成功。
步骤三:查看GPU监控大盘
查看集群GPU监控-集群维度
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
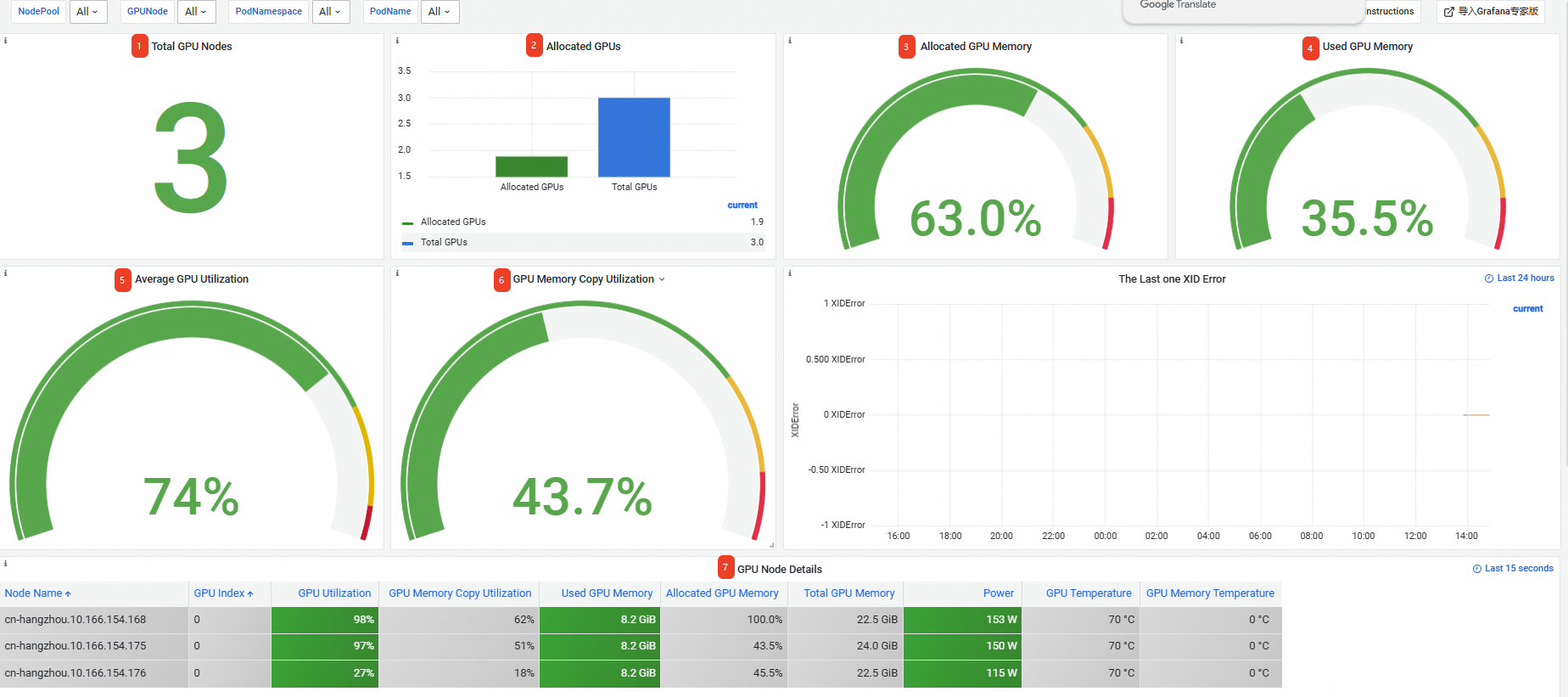
在Prometheus监控大盘列表页面,单击GPU监控页签,然后单击集群GPU监控-集群维度页签。集群维度监控大盘的信息如下,更多信息,请参见集群维度监控大盘。
序号
Panel名称
说明
①
Total GPU Nodes
共有3个GPU节点。
②
Allocated GPUs
GPU总数为3,已分配GPU数为1.9。
说明如果是按整张卡维度申请GPU,一张卡分配的比例为1;如果是共享GPU调度,分配比例为某张卡已分配的显存与这张卡总显存的比例。
③
Allocated GPU Memory
已分配63.0%的显存。
④
Used GPU Memory
已使用35.5%的显存。
⑤
Average GPU Utilization
所有卡的平均利用率为74%。
⑥
GPU Memory Copy Utilization
所有卡的平均内存复制利用率为43.7%。
⑦
GPU Node Details
集群中GPU节点的信息,包括节点名称、GPU卡索引号、GPU利用率、内存控制器利用率等。
查看集群GPU监控-节点维度
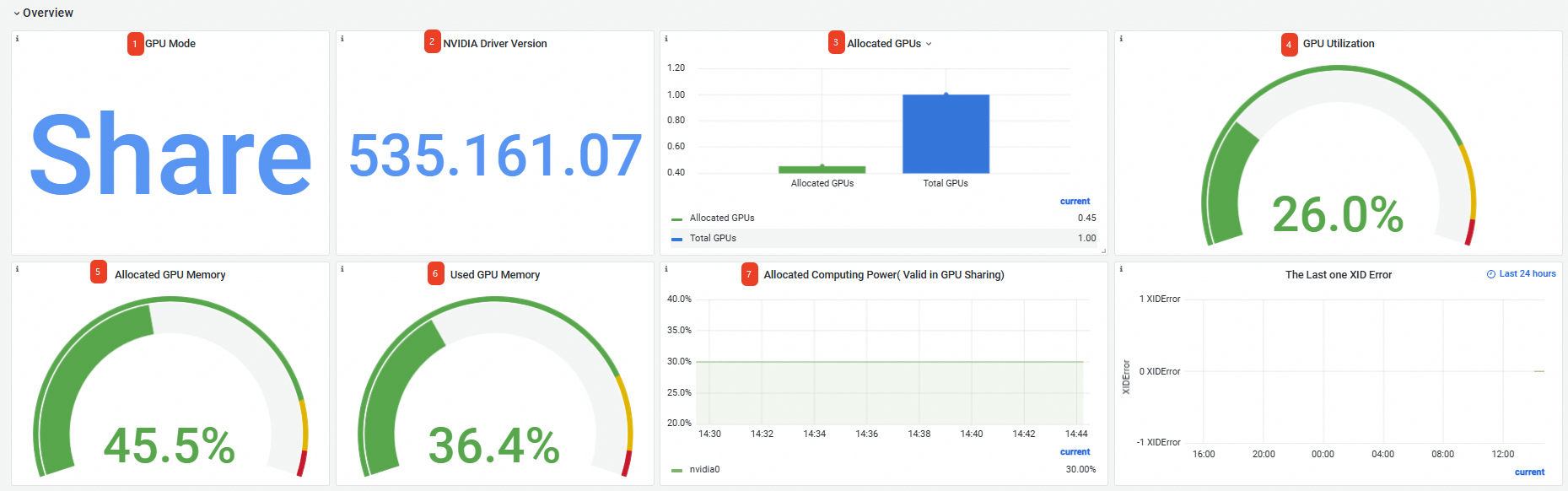
在Prometheus监控大盘列表页面,单击GPU监控页签,然后单击集群GPU监控-节点维度页签,选择GPUNode为目标节点,本文以cn-hangzhou.10.166.154.xxx为例。节点维度监控大盘的信息如下:


Panel组 | 序号 | Panel名称 | 说明 |
Overview | ① | GPU Mode | GPU模式为共享模式,按显存和算力维度申请GPU资源。 |
② | NVIDIA Driver Version | 安装的GPU驱动版本为535.161.07。 | |
③ | Allocated GPUs | 总GPU个数为1,已分配GPU个数为0.45。 | |
④ | GPU Utilization | GPU的平均利用率为26%。 | |
⑤ | Allocated GPU Memory | 已分配的GPU显存值占总显存值的45.5%。 | |
⑥ | Used GPU Memory | 当前使用的GPU显存值占总显存值的36.4%。 | |
⑦ | Allocated Computing Power | 0号GPU卡已分配30%算力。 说明 只有在节点开启算力分配的情况下,节点已分配的算力比例(Allocated Computing Power)才有数据显示,因此本文示例的三个节点,只有包含 | |
Utilization | ⑧ | GPU Utilization | 0号GPU卡利用率最小值为0%,最大值为33%,平均值为12%。 |
⑨ | Memory Copy Utilization | 0号GPU卡内存复制利用率最小值为0%,最大值为22%,平均值为8%。 | |
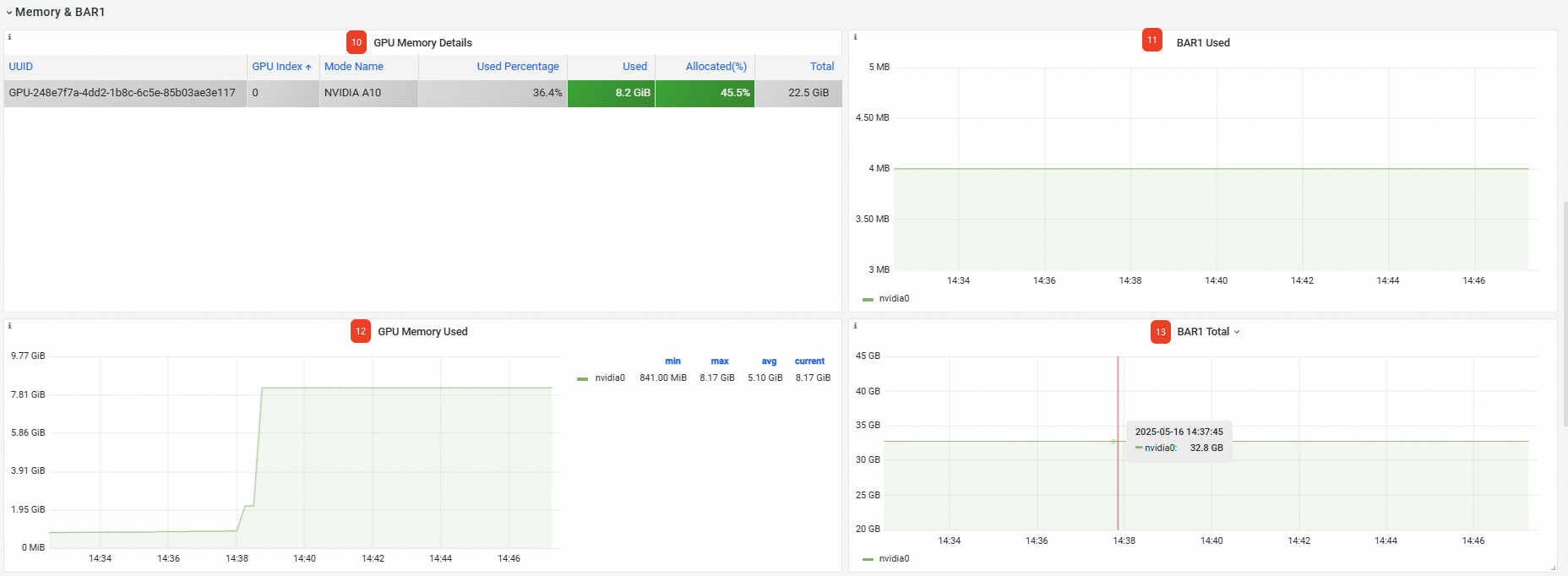
Memory&BAR1 | ⑩ | GPU Memory Details | GPU内存信息,包括GPU卡的UUID、索引号、卡型号等。 |
⑪ | BAR1 Used | 已使用BAR1为4 MB。 | |
⑫ | Memory Used | GPU卡已使用的显存大小为8.17 GB。 | |
⑬ | BAR1 Total | 总BAR1为32.8 GB。 | |
GPU Process | ⑭ | GPU Process Details | GPU线程详细信息,包括Process所属的Pod命名空间、Process所属的Pod名称等。 |
也可在下方查看更多高级指标,详情请参见节点维度监控大盘。

查看集群GPU监控-应用Pod维度
在Prometheus监控大盘列表页面,单击GPU监控页签,然后单击集群GPU监控-应用Pod维度页签。Pod维度监控大盘的信息如下:
序号 | Panel名称 | 说明 |
① | GPU Pod Details | 集群申请GPU资源的Pod信息,包括Pod所在的命名空间、Pod名称、节点名称、已使用的显存等。 说明
|
也可在下方查看更多高级指标,详情请参见监控面板说明。
