本文介绍在Spark中如何配置和使用动态资源分配(Dynamic Resource Allocation)功能,以最大化集群资源的利用效率,减少资源闲置,同时提升任务执行的灵活性和整体系统性能。
什么是动态资源分配?
动态资源分配(Dynamic Resource Allocation,简称DRA)是Spark提供的一个机制,可根据工作负载的大小动态调整作业所使用的计算资源。如果某个Executor长时间处于空闲状态,Driver会自动将其释放,将资源返还给集群;而如果某些任务等待的调度时间过长,Driver会申请更多的Executor来执行这些任务。DRA帮助Spark灵活应对工作负载变化,避免因资源不足导致作业执行时间过长或因资源过剩导致资源浪费,从而提升集群整体资源利用率。
资源分配策略
启用DRA后,当任务存在等待调度的情况时,Driver会请求额外的Executor。如果任务等待时间超过spark.dynamicAllocation.schedulerBacklogTimeout(默认1秒),Driver开始分批次申请Executor。每经过 spark.dynamicAllocation.sustainedSchedulerBacklogTimeout(默认1秒),如果仍有待调度的任务,Driver会继续申请更多的Executor。每批次申请的Executor数量以指数方式增长,如第一批申请1个,后续批次依次申请 2、4、8 个,以此类推。
资源释放策略
对于空闲的Executor,当其空闲时间超过spark.dynamicAllocation.executorIdleTimeout(默认60秒)时,Driver会自动释放这些Executors,以优化资源利用率。
启用动态资源分配
Spark的DRA机制在Standalone、YARN、Mesos和Kubernetes运行模式下都可以使用,默认情况下禁用。如需启用DRA,除了将spark.dynamicAllocation.enabled设置为true外,还需配置以下选项:
启用外部Shuffle服务:设置
spark.shuffle.service.enabled为true,并在同一集群的每个工作节点上配置External Shuffle Service(ESS)。启用Shuffle数据跟踪:将
spark.dynamicAllocation.shuffleTracking.enabled设为true,Spark会跟踪Shuffle数据的位置和状态,确保Shuffle数据不会丢失,并且可以在需要时重新计算这部分数据。启用节点退役功能:设置
spark.decommission.enabled和spark.storage.decommission.shuffleBlocks.enabled为true,确保Spark在节点被退役时会主动将该节点上的Shuffle数据块复制到其他可用节点。配置ShuffleDataIO插件:通过
spark.shuffle.sort.io.plugin.class指定ShuffleDataIO插件类,自定义Shuffle数据的IO操作以实现将Shuffle数据写入不同的存储系统中。
在不同的模式下,配置方法不同:
Spark Standalone模式:只需配置选项1。
Spark on Kubernetes模式:
不使用Celeborn作为RSS时:将
spark.dynamicAllocation.shuffleTracking.enabled设置为true(对应选项2)。使用Celeborn作为RSS时:
Spark版本3.5.0及以上:配置
spark.shuffle.sort.io.plugin.class为org.apache.spark.shuffle.celeborn.CelebornShuffleDataIO(对应选项4)。Spark版本小于3.5.0:需为Spark打上相应版本的补丁,无需额外配置。详情请参见Support Spark Dynamic Allocation。
Spark版本3.4.0及以上:建议将
spark.dynamicAllocation.shuffleTracking.enabled设置为false,可避免executor处于空闲状态时无法被及时释放。
本示例将介绍Spark on Kubernetes模式下的配置方式,包括不使用Celeborn和使用Celeborn作为RSS的场景。
前提条件
- 说明
本示例中部署时使用了
spark.jobNamespaces=["spark"]。如需不同的命名空间,请相应修改namespace字段。 已部署ack-spark-history-server组件。
说明本示例中创建名为
nas-pv的PV和nas-pvc的PVC,并配置Spark History Server从NAS的/spark/event-logs路径读取Spark事件日志。(可选)已部署ack-celeborn组件。
操作步骤
不使用Celeborn作为RSS
在以下Spark 3.5.4版本的示例中,如果不使用Celeborn作为RSS,并启用动态资源分配(DRA),请设置以下参数:
启用动态资源分配:
spark.dynamicAllocation.enabled设置为"true"。启用shuffle文件跟踪,无需依赖ESS实现动态资源分配:
spark.dynamicAllocation.shuffleTracking.enabled: "true"。
根据如下内容创建SparkApplication清单文件并保存为
spark-pagerank-dra.yaml:apiVersion: sparkoperator.k8s.io/v1beta2 kind: SparkApplication metadata: name: spark-pagerank-dra namespace: spark spec: type: Scala mode: cluster # 需将<SPARK_IMAGE>替换成您自己的Spark镜像。 image: <SPARK_IMAGE> mainApplicationFile: local:///opt/spark/examples/jars/spark-examples_2.12-3.5.4.jar mainClass: org.apache.spark.examples.SparkPageRank arguments: # 需将<OSS_BUCKET>替换成您的OSS Bucket名称。 - oss://<OSS_BUCKET>/data/pagerank_dataset.txt - "10" sparkVersion: 3.5.4 hadoopConf: # 支持使用oss://格式访问OSS数据。 fs.AbstractFileSystem.oss.impl: org.apache.hadoop.fs.aliyun.oss.OSS fs.oss.impl: org.apache.hadoop.fs.aliyun.oss.AliyunOSSFileSystem # OSS 访问端点,需将<OSS_ENDPOINT>替换成您的OSS访问端点。 # 例如,北京地域OSS内网访问端点为oss-cn-beijing-internal.aliyuncs.com fs.oss.endpoint: <OSS_ENDPOINT> # 从环境变量中读取OSS访问凭据。 fs.oss.credentials.provider: com.aliyun.oss.common.auth.EnvironmentVariableCredentialsProvider sparkConf: # ==================== # 事件日志 # ==================== spark.eventLog.enabled: "true" spark.eventLog.dir: file:///mnt/nas/spark/event-logs # ==================== # 动态资源分配 # ==================== # 启用动态资源分配 spark.dynamicAllocation.enabled: "true" # 启用shuffle文件跟踪,不依赖ESS即可实现动态资源分配。 spark.dynamicAllocation.shuffleTracking.enabled: "true" # Executor 数量的初始值。 spark.dynamicAllocation.initialExecutors: "1" # Executor 数量的最小值。 spark.dynamicAllocation.minExecutors: "0" # Executor 数量的最大值。 spark.dynamicAllocation.maxExecutors: "5" # Executor空闲超时时间,超过该时间将会被释放掉。 spark.dynamicAllocation.executorIdleTimeout: 60s # 缓存了数据块的 Executor 空闲超时时间,超过该时间将会被释放掉,默认为infinity,即不会释放。 # spark.dynamicAllocation.cachedExecutorIdleTimeout: # 当存在待调度任务超过该时间后,将会申请更多的Executor。 spark.dynamicAllocation.schedulerBacklogTimeout: 1s # 每间隔该时间后,将会开始下一批次申请Executor。 spark.dynamicAllocation.sustainedSchedulerBacklogTimeout: 1s driver: cores: 1 coreLimit: 1200m memory: 512m envFrom: - secretRef: name: spark-oss-secret volumeMounts: - name: nas mountPath: /mnt/nas serviceAccount: spark-operator-spark executor: cores: 1 coreLimit: "2" memory: 8g envFrom: - secretRef: name: spark-oss-secret volumeMounts: - name: nas mountPath: /mnt/nas volumes: - name: nas persistentVolumeClaim: claimName: nas-pvc restartPolicy: type: Never说明上述示例作业中使用到的Spark镜像需要包含Hadoop OSS SDK依赖,您可以参考如下Dockerfile自行构建镜像并推送到自己的镜像仓库中:
ARG SPARK_IMAGE=spark:3.5.4 FROM ${SPARK_IMAGE} # Add dependency for Hadoop Aliyun OSS support ADD --chown=spark:spark --chmod=644 https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-aliyun/3.3.4/hadoop-aliyun-3.3.4.jar ${SPARK_HOME}/jars ADD --chown=spark:spark --chmod=644 https://repo1.maven.org/maven2/com/aliyun/oss/aliyun-sdk-oss/3.17.4/aliyun-sdk-oss-3.17.4.jar ${SPARK_HOME}/jars ADD --chown=spark:spark --chmod=644 https://repo1.maven.org/maven2/org/jdom/jdom2/2.0.6.1/jdom2-2.0.6.1.jar ${SPARK_HOME}/jars执行如下命令提交Spark作业。
kubectl apply -f spark-pagerank-dra.yaml预期输出:
sparkapplication.sparkoperator.k8s.io/spark-pagerank-dra created查看Driver日志。
kubectl logs -n spark spark-pagerank-dra-driver | grep -a2 -b2 "Going to request"预期输出:
3544-25/01/16 03:26:04 INFO SparkKubernetesClientFactory: Auto-configuring K8S client using current context from users K8S config file 3674-25/01/16 03:26:06 INFO Utils: Using initial executors = 1, max of spark.dynamicAllocation.initialExecutors, spark.dynamicAllocation.minExecutors and spark.executor.instances 3848:25/01/16 03:26:06 INFO ExecutorPodsAllocator: Going to request 1 executors from Kubernetes for ResourceProfile Id: 0, target: 1, known: 0, sharedSlotFromPendingPods: 2147483647. 4026-25/01/16 03:26:06 INFO ExecutorPodsAllocator: Found 0 reusable PVCs from 0 PVCs 4106-25/01/16 03:26:06 INFO BasicExecutorFeatureStep: Decommissioning not enabled, skipping shutdown script -- 10410-25/01/16 03:26:15 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0) (192.168.95.190, executor 1, partition 0, PROCESS_LOCAL, 9807 bytes) 10558-25/01/16 03:26:15 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on 192.168.95.190:34327 (size: 12.5 KiB, free: 4.6 GiB) 10690:25/01/16 03:26:16 INFO ExecutorPodsAllocator: Going to request 1 executors from Kubernetes for ResourceProfile Id: 0, target: 2, known: 1, sharedSlotFromPendingPods: 2147483647. 10868-25/01/16 03:26:16 INFO ExecutorAllocationManager: Requesting 1 new executor because tasks are backlogged (new desired total will be 2 for resource profile id: 0) 11030-25/01/16 03:26:16 INFO ExecutorPodsAllocator: Found 0 reusable PVCs from 0 PVCs从日志可以看出,Driver在03:26:06和03:26:16时分别请求了1个Executor。
访问Spark History Server查看,访问步骤请参见访问Spark History Server Web UI。
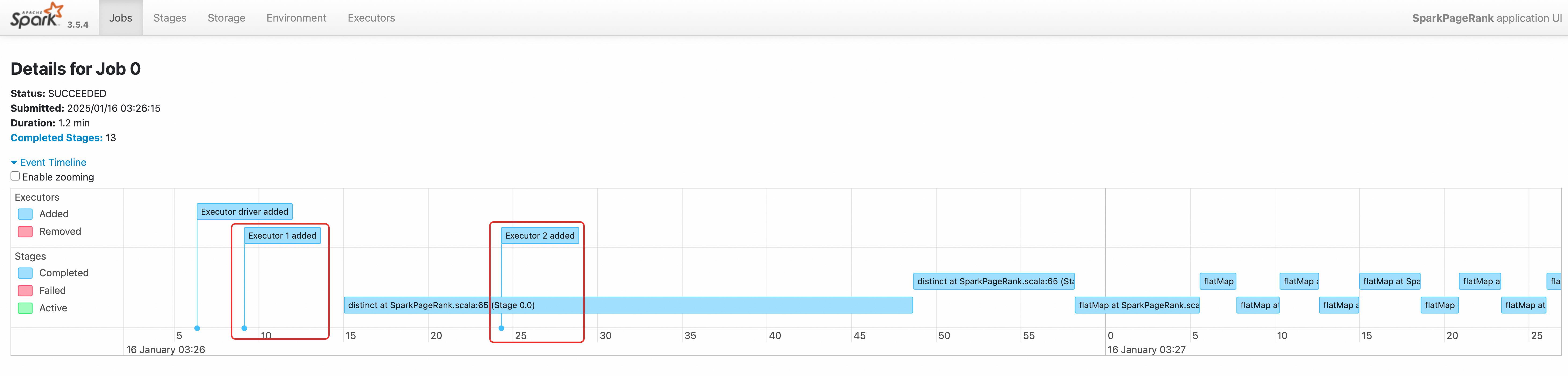
通过查看该作业的事件时间线,我们也可以看到两个Executor先后被创建。
使用Celeborn作为RSS
在以下Spark 3.5.4版本的示例中,如果使用Celeborn作为RSS,并启用动态资源分配(DRA),请设置以下参数:
启用动态资源分配:
spark.dynamicAllocation.enabled设置为"true"。支持动态资源分配的配置(适用于Spark3.5.0及以上):
spark.shuffle.sort.io.plugin.class设置为org.apache.spark.shuffle.celeborn.CelebornShuffleDataIO。确保空闲的executors及时释放:
spark.dynamicAllocation.shuffleTracking.enabled设置为"false"。
根据如下内容创建SparkApplication清单文件并保存为
spark-pagerank-celeborn-dra.yaml:apiVersion: sparkoperator.k8s.io/v1beta2 kind: SparkApplication metadata: name: spark-pagerank-celeborn-dra namespace: spark spec: type: Scala mode: cluster # 需将 <SPARK_IMAGE> 替换成您自己的Spark镜像,该镜像中需要包含JindoSDK依赖。 image: <SPARK_IMAGE> mainApplicationFile: local:///opt/spark/examples/jars/spark-examples_2.12-3.5.4.jar mainClass: org.apache.spark.examples.SparkPageRank arguments: # 需将 <OSS_BUCKET> 替换成您的 OSS Bucket名称。 - oss://<OSS_BUCKET>/data/pagerank_dataset.txt - "10" sparkVersion: 3.5.4 hadoopConf: # 支持使用 oss:// 格式访问 OSS 数据。 fs.AbstractFileSystem.oss.impl: org.apache.hadoop.fs.aliyun.oss.OSS fs.oss.impl: org.apache.hadoop.fs.aliyun.oss.AliyunOSSFileSystem # OSS 访问端点,需将 <OSS_ENDPOINT> 替换成您的 OSS 访问端点 # 例如,北京地域 OSS 内网访问端点为 oss-cn-beijing-internal.aliyuncs.com fs.oss.endpoint: <OSS_ENDPOINT> # 从环境变量中读取 OSS 访问凭据 fs.oss.credentials.provider: com.aliyun.oss.common.auth.EnvironmentVariableCredentialsProvider sparkConf: # ==================== # 事件日志 # ==================== spark.eventLog.enabled: "true" spark.eventLog.dir: file:///mnt/nas/spark/event-logs # ==================== # Celeborn # Ref: https://github.com/apache/celeborn/blob/main/README.md#spark-configuration # ==================== # Shuffle manager class name changed in 0.3.0: # before 0.3.0: `org.apache.spark.shuffle.celeborn.RssShuffleManager` # since 0.3.0: `org.apache.spark.shuffle.celeborn.SparkShuffleManager` spark.shuffle.manager: org.apache.spark.shuffle.celeborn.SparkShuffleManager # Must use kryo serializer because java serializer do not support relocation spark.serializer: org.apache.spark.serializer.KryoSerializer # 需要根据 Celeborn master 副本数量进行配置。 spark.celeborn.master.endpoints: celeborn-master-0.celeborn-master-svc.celeborn.svc.cluster.local,celeborn-master-1.celeborn-master-svc.celeborn.svc.cluster.local,celeborn-master-2.celeborn-master-svc.celeborn.svc.cluster.local # options: hash, sort # Hash shuffle writer use (partition count) * (celeborn.push.buffer.max.size) * (spark.executor.cores) memory. # Sort shuffle writer uses less memory than hash shuffle writer, if your shuffle partition count is large, try to use sort hash writer. spark.celeborn.client.spark.shuffle.writer: hash # We recommend setting `spark.celeborn.client.push.replicate.enabled` to true to enable server-side data replication # If you have only one worker, this setting must be false # If your Celeborn is using HDFS, it's recommended to set this setting to false spark.celeborn.client.push.replicate.enabled: "false" # Support for Spark AQE only tested under Spark 3 spark.sql.adaptive.localShuffleReader.enabled: "false" # we recommend enabling aqe support to gain better performance spark.sql.adaptive.enabled: "true" spark.sql.adaptive.skewJoin.enabled: "true" # 当 Spark 版本 >= 3.5.0 时,配置该选项以支持动态资源分配 spark.shuffle.sort.io.plugin.class: org.apache.spark.shuffle.celeborn.CelebornShuffleDataIO spark.executor.userClassPathFirst: "false" # ==================== # 动态资源分配 # Ref: https://spark.apache.org/docs/latest/job-scheduling.html#dynamic-resource-allocation # ==================== # 启用动态资源分配 spark.dynamicAllocation.enabled: "true" # 启用 shuffle 文件跟踪,不依赖 ESS 即可实现动态资源分配。 # 在使用 Celeborn 作为 RSS 时,当 Spark 版本 >= 3.4.0 时,强烈建议关闭该选项。 spark.dynamicAllocation.shuffleTracking.enabled: "false" # Executor 数量的初始值。 spark.dynamicAllocation.initialExecutors: "1" # Executor 数量的最小值。 spark.dynamicAllocation.minExecutors: "0" # Executor 数量的最大值。 spark.dynamicAllocation.maxExecutors: "5" # Executor 空闲超时时间,超过该时间将会被释放掉。 spark.dynamicAllocation.executorIdleTimeout: 60s # 缓存了数据块的 Executor 空闲超时时间,超过该时间将会被释放掉,默认为 infinity,即不会释放。 # spark.dynamicAllocation.cachedExecutorIdleTimeout: # 当存在待调度任务超过该时间后,将会申请更多的 executor。 spark.dynamicAllocation.schedulerBacklogTimeout: 1s # 每间隔该时间后,将会开始下一批次申请 Executor。 spark.dynamicAllocation.sustainedSchedulerBacklogTimeout: 1s driver: cores: 1 coreLimit: 1200m memory: 512m envFrom: - secretRef: name: spark-oss-secret volumeMounts: - name: nas mountPath: /mnt/nas serviceAccount: spark-operator-spark executor: cores: 1 coreLimit: "1" memory: 4g envFrom: - secretRef: name: spark-oss-secret volumeMounts: - name: nas mountPath: /mnt/nas volumes: - name: nas persistentVolumeClaim: claimName: nas-pvc restartPolicy: type: Never说明上述示例作业中使用到的Spark镜像需要包含Hadoop OSS SDK依赖,您可以参考如下Dockerfile自行构建镜像并推送到自己的镜像仓库中:
ARG SPARK_IMAGE=spark:3.5.4 FROM ${SPARK_IMAGE} # Add dependency for Hadoop Aliyun OSS support ADD --chown=spark:spark --chmod=644 https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-aliyun/3.3.4/hadoop-aliyun-3.3.4.jar ${SPARK_HOME}/jars ADD --chown=spark:spark --chmod=644 https://repo1.maven.org/maven2/com/aliyun/oss/aliyun-sdk-oss/3.17.4/aliyun-sdk-oss-3.17.4.jar ${SPARK_HOME}/jars ADD --chown=spark:spark --chmod=644 https://repo1.maven.org/maven2/org/jdom/jdom2/2.0.6.1/jdom2-2.0.6.1.jar ${SPARK_HOME}/jars # Add dependency for Celeborn ADD --chown=spark:spark --chmod=644 https://repo1.maven.org/maven2/org/apache/celeborn/celeborn-client-spark-3-shaded_2.12/0.5.3/celeborn-client-spark-3-shaded_2.12-0.5.3.jar ${SPARK_HOME}/jars执行如下命令提交SparkApplication。
kubectl apply -f spark-pagerank-celeborn-dra.yaml预期输出:
sparkapplication.sparkoperator.k8s.io/spark-pagerank-celeborn-dra created查看Driver日志。
kubectl logs -n spark spark-pagerank-celeborn-dra-driver | grep -a2 -b2 "Going to request"预期输出:
3544-25/01/16 03:51:28 INFO SparkKubernetesClientFactory: Auto-configuring K8S client using current context from users K8S config file 3674-25/01/16 03:51:30 INFO Utils: Using initial executors = 1, max of spark.dynamicAllocation.initialExecutors, spark.dynamicAllocation.minExecutors and spark.executor.instances 3848:25/01/16 03:51:30 INFO ExecutorPodsAllocator: Going to request 1 executors from Kubernetes for ResourceProfile Id: 0, target: 1, known: 0, sharedSlotFromPendingPods: 2147483647. 4026-25/01/16 03:51:30 INFO ExecutorPodsAllocator: Found 0 reusable PVCs from 0 PVCs 4106-25/01/16 03:51:30 INFO CelebornShuffleDataIO: Loading CelebornShuffleDataIO -- 11796-25/01/16 03:51:41 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0) (192.168.95.163, executor 1, partition 0, PROCESS_LOCAL, 9807 bytes) 11944-25/01/16 03:51:42 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on 192.168.95.163:37665 (size: 13.3 KiB, free: 2.1 GiB) 12076:25/01/16 03:51:42 INFO ExecutorPodsAllocator: Going to request 1 executors from Kubernetes for ResourceProfile Id: 0, target: 2, known: 1, sharedSlotFromPendingPods: 2147483647. 12254-25/01/16 03:51:42 INFO ExecutorAllocationManager: Requesting 1 new executor because tasks are backlogged (new desired total will be 2 for resource profile id: 0) 12416-25/01/16 03:51:42 INFO ExecutorPodsAllocator: Found 0 reusable PVCs from 0 PVCs可以看到driver在
03:51:30和03:51:42时分别申请了1个Executor资源。访问Spark History Server查看,访问步骤请参见访问Spark History Server Web UI。
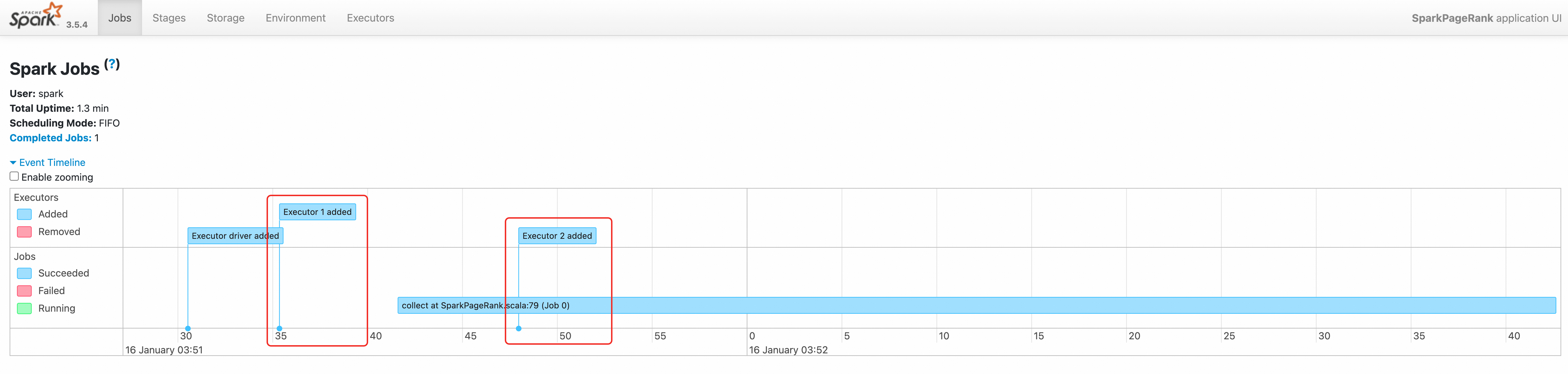
通过查看该作业的事件时间线,我们也可以看到两个executor先后被创建。