本文介紹DashVector如何通過控制台、SDK、API三種不同的方式檢索向量。
控制台方式
在左側導覽列單擊Cluster列表,選中需要檢索向量的Collection,單擊Collection詳情。

在左側二級導覽列,單擊相似向量搜尋,填寫相應內容後,單擊搜尋,即可返回相似向量結果。
單向量Collection向量檢索
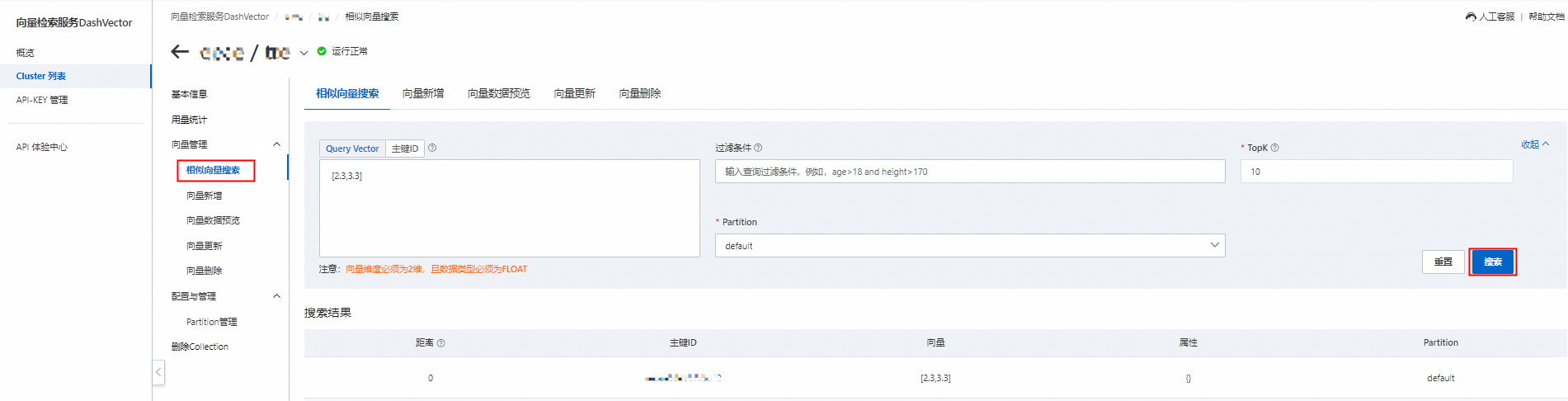 向量檢索參數設定如下所示。
向量檢索參數設定如下所示。參數
對應API參數名稱
說明
是否必選
Query Vector
vector
向量資料,例如[1.0,2.0,3.0,4.0]。
說明向量維度和資料類型必須與Collection一致。
是
過濾條件
filter
過濾條件,需滿足SQL where子句規範,請參見條件過濾檢索。
否
Partition
partition
Partition名稱。預設為default,請根據需要選擇不同的Partition。
是
TopK
topk
最大可返回的向量條數。TopK預設10,最大可支援1024。
是
返回結果參數說明如下所示。
參數
對應API參數名稱
說明
距離
score
向量相似性
不同的距離度量方式,向量間距離的數值表示並不相同,請參見什麼是向量。
返回結果根據向量相似性降序排列。
主鍵ID
id
相似向量的主鍵ID。
向量
vector
向量資料,例如
[1.0,2.0,3.0,4.0]。屬性
fileds
json欄位參數,例如
{"price":100,"type":"dress"}。Partition
partition
相似向量所在的partition。
多向量Collection向量檢索
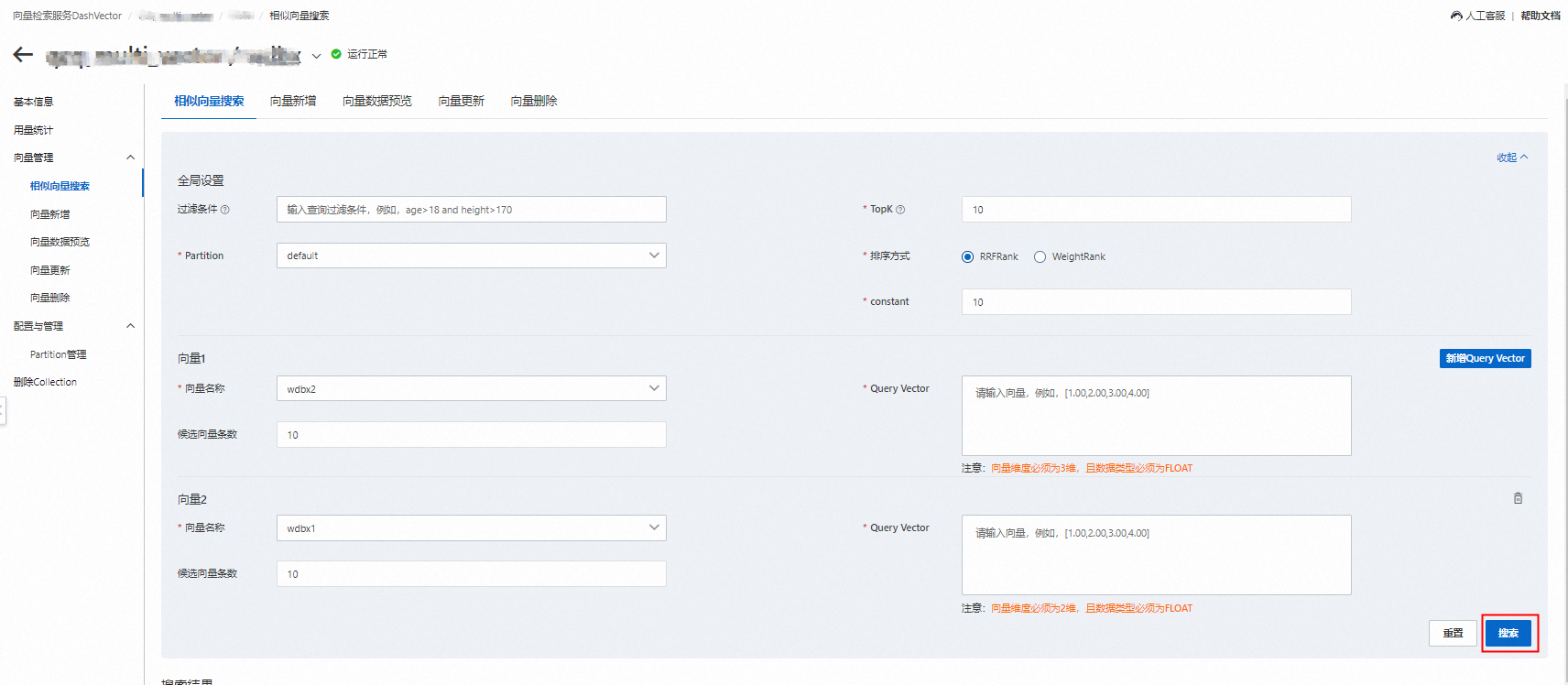 說明
說明點擊新增Query Vector,下方會多出一條記錄,向量條數不能超過Collection中定義的向量條數。
點擊右側刪除按鈕,本條記錄被刪除。
向量檢索參數設定如下所示。
參數
對應API參數名稱
說明
是否必選
向量名稱
{VectorName}
自訂。需要滿足如下要求:
命名長度為3-32個字元。
必須由大小寫字母、數字和符號(_,-)組成。例如:vector1、vector_1、vector_a_name。
向量名稱在本Collection中必須唯一,不允許兩個相同的向量名稱同時存在。
說明向量名稱只能選擇建立Collection時填寫的向量名稱。
是
Query Vector
vector
向量資料,例如[1.0,2.0,3.0,4.0]。
說明向量維度和資料類型必須與建立Collection時定義的一致。
是
候選向量條數
num_candidates
單向量召回多少條結果。預設等於topk(10)。
否
權重
Optional[Dict[str, float]
只有排序方式選擇WeightRank時,才需要設定。預設是權重相同1.0:1.0:1.0···,詳見WeightedRanker。
是
排序方式
RrfRanker/
WeightedRanker
支援RRFRank和WeightRank兩種方式。詳見RrfRanker和WeightedRanker。
是
constant
rank_constant
當排序方式選擇RRFRank時有效。例如當rank_constant=10,表示每條向量返回10條最相似的結果。預設值為60,詳見RrfRanker。
是
過濾條件
filter
過濾條件,需滿足SQL where子句規範,請參見條件過濾檢索。
否
Partition
partition
Partition名稱。預設為default,請根據需要選擇不同的Partition。
是
TopK
topk
最大可返回的向量條數。TopK預設10,最大可支援1024。
是
返回結果參數說明如下所示。
參數
對應API參數名稱
說明
距離
score
向量相似性
不同的距離度量方式,向量間距離的數值表示並不相同,請參見什麼是向量。
返回結果根據向量相似性降序排列。
主鍵ID
id
相似向量的主鍵ID。
向量
vector
向量資料,例如
[1.0,2.0,3.0,4.0]。屬性
fileds
json欄位參數,例如
{"price":100,"type":"dress"}。Partition
partition
相似向量所在的partition。
SDK方式
API方式
通過HTTP API檢索向量的方式,請參見檢索Doc。