PrestoDB是基於MPP架構的開源巨量資料分布式SQL查詢引擎,支援對接MySQL、Elasticsearch、Tablestore等多種資料來源。使用PrestoDB對接Table StoreTablestore後,基於PrestoDB on Tablestore您可以使用SQL查詢與分析Tablestore中的資料、寫入資料到Tablestore以及匯入資料到Tablestore。
背景資訊
PrestoDB是基於MPP架構的開源巨量資料分布式SQL查詢引擎,支援對接MySQL、Elasticsearch、Tablestore等多種資料來源。PrestoDB可以作為查詢工具、資料ETL工具、壓力器和統一查詢引擎來滿足不同情境的資料處理需求。
PrestoDB作為日常開發和調查問題時的查詢工具,支援通過SQL查詢或分析表中資料。
PrestoDB作為資料ETL工具,支援實現跨表或跨執行個體的資料複製以及異構資料來源的資料拷貝。
PrestoDB作為壓力器,支援批量掃描或者批量寫入資料。
PrestoDB作為資料中台內的統一查詢引擎,支援對接多種異構資料來源。
通過PrestoDB使用Tablestore前,您需要使用PrestoDB對接Tablestore。對接完成後,基於PrestoDB on Tablestore您可以使用SQL查詢與分析Tablestore中的資料、寫入資料到Tablestore以及匯入資料到Tablestore。
前提條件
已準備帶有Linux系統或者macOS系統的伺服器並完成如下軟體的安裝,本文以Linux系統為例介紹。
說明如果當前沒有帶有Linux系統的伺服器,推薦您使用Elastic Compute Service部署Linux系統後再進行操作。更多資訊,請參見通過控制台使用ECS執行個體(快捷版)。
已完成Java 8(64-bit)和Python3開發環境的安裝。
已完成PrestoDB安裝。
請根據所用PrestoDB版本下載相應的prestodb-tablestore-connector檔案並將檔案上傳到PrestoDB安裝目錄下的
plugin目錄中,然後解壓檔案。prestodb-tablestore-connector外掛程式版本與PrestoDB版本的配套關係請參見下表。
外掛程式版本
PrestoDB版本
說明
prestodb-tablestore-connector-202401
0.280
首個版本發布。本外掛程式適用於PrestoDB 0.280及之後版本。
已擷取PrestoDB要對接的Tablestore相關資訊,例如訪問帳號、執行個體資訊、表資訊等。
已為具有Tablestore操作許可權的RAM使用者建立AccessKey。具體操作,請參見擷取AccessKey。
說明如果未為RAM使用者授予操作Tablestore的許可權,請完成授權後再進行操作。具體操作,請參見通過RAM Policy為RAM使用者授權。
注意事項
只適用於寬表模型。
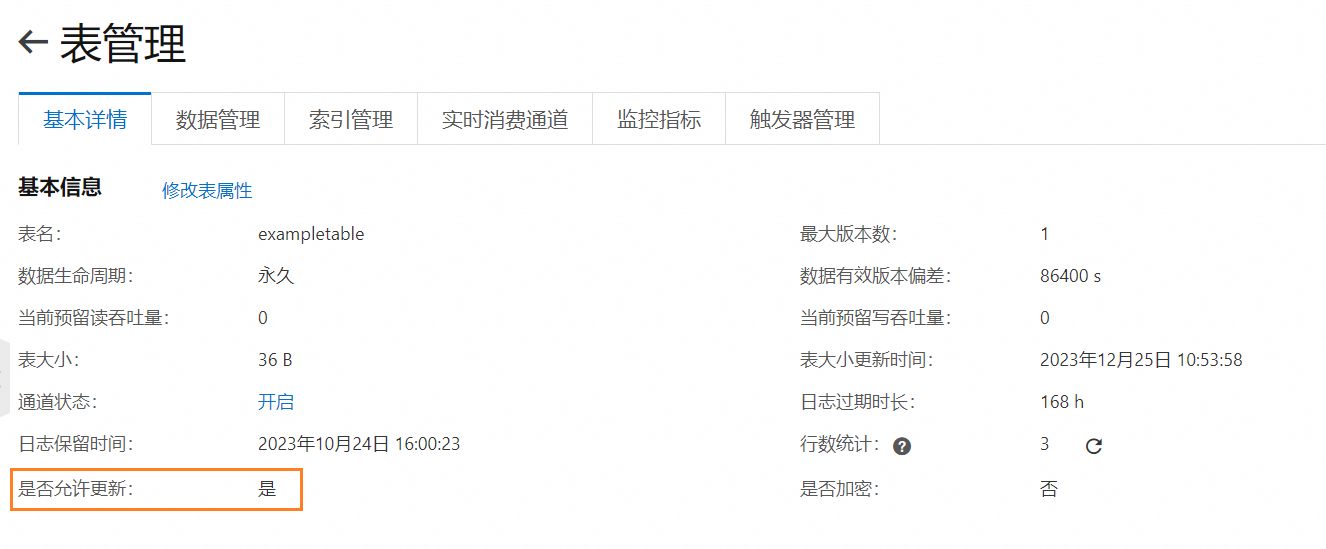
當前PrestoDB的寫入模式預設為UpdateRow,暫時不提供PutRow的寫入模式。如果需要通過PrestoDB寫入資料到Tablestore,請務必確保Tablestore資料表的是否允許更新配置為是,否則資料無法寫入。
重要由於使用了多元索引資料生命週期(即取值不為-1)時,您必須配置Tablestore資料表的是否允許更新配置為否,因此如果某個表使用了多元索引資料生命週期,則無法通過PrestoDB寫入資料到該表。
如果實際情境中有使用PutRow的寫入模式需求,請通過DingTalk搜尋36165029092(
Table Store技術交流群-3)加入聯絡我們。
您可以通過控制台在資料表的基本詳情頁簽查看是否允許更新的配置或者通過SDK調用DescribeTable介面查詢。
欄位類型映射
Table Store與PrestoDB都有其自身的類型,兩者之間的欄位類型對應關係請參見下表。
Tablestore的欄位類型 | PrestoDB的欄位類型 |
string | varchar |
integer | bigint |
double | double |
boolean | boolean |
binary | varbinary |
使用流程
通過PrestoDB使用Tablestore的主要步驟包括使用PrestoDB對接Tablestore、運行PrestoDB的SQL CLI、建立Schema和映射表以及使用SQL操作資料。
步驟一:使用PrestoDB對接Tablestore
安裝PrestoDB後,您需要進行PrestoDB的Catalog配置和Schema配置來完成PrestoDB和Tablestore的對接,其中Catalog設定檔的存放路徑為etc/catalog/tablestore.properties。
配置說明
操作步驟
在Catalog設定檔中指定Schema的配置模式並完成相應參數配置。此處以Meta表動態配置方式為例介紹對接配置操作。
進入PrestoDB安裝目錄,然後在PrestoDB安裝目錄下的
etc/catalog/路徑中建立tablestore.properties檔案。重要請確保已具有檔案的可執行許可權後再進行編輯操作。
Catalog設定檔所處的目錄如下圖所示。
編輯
tablestore.properties檔案並根據實際修改配置樣本後拷貝到檔案中。使用Meta表動態配置方式時,請配置
tablestore.schema-mode為meta-table。說明如果要使用本地靜態檔案配置方式進行Schema配置,請配置
tablestore.schema-mode為file並配置tablestore.schema-file為本地靜態檔案完整路徑,然後在靜態檔案中配置Schema資訊。更多資訊,請參見Server配置。connector.name=tablestore tablestore.schema-mode=meta-table #tablestore.schema-mode=file tablestore.schema-file=/users/test/tablestore/presto/tablestore.schema tablestore.meta-instance=metastoreinstance tablestore.endpoint=http://metastoreinstance.cn-hangzhou,ots.aliyuncs.com/ tablestore.accessid=**************** tablestore.accesskey=************************** tablestore.meta-table=meta_table tablestore.auto-create-meta-table=true具體配置項說明請參見下表。
配置項
樣本
是否必選
說明
connector.name
tablestore
是
連接器名稱。此項必須配置tablestore。
tablestore.schema-mode
meta-table
是
Schema模式配置。此處配置為
meta-table。tablestore.meta-instance
metastoreinstance
是
Tablestore中用於儲存中繼資料的執行個體,請根據實際修改。更多資訊,請參見執行個體。
重要請確保配置的執行個體已在阿里雲帳號中存在。
tablestore.endpoint
http://metastoreinstance.cn-hangzhou,ots.aliyuncs.com/
是
Tablestore中用於儲存中繼資料的執行個體的訪問地址,請修改實際修改。更多資訊,請參見服務地址。
tablestore.accessid
****************
是
具有儲存中繼資料的執行個體存取權限的使用者AccessKey ID和AccessKey Secret。
tablestore.accesskey
**************************
tablestore.meta-table
meta_table
是
Tablestore中用於儲存中繼資料的表名,請根據實際修改。
tablestore.auto-create-meta-table
true
否
是否需要自動建立中繼資料表。預設值為true,表示建立Schema時會自動建立中繼資料表。
儲存設定檔並退出。
說明您可以執行cat命令確認配置是否儲存成功。
步驟二:運行Presto的SQL CLI
對接完成後,您可以啟動Presto Server並運行SQL。
擷取client可執行程式。
下載PrestoDB用戶端。
此處以presto-cli-0.280-executable.jar為例介紹。
將PrestoDB用戶端儲存到PrestoDB安裝目錄下的
bin目錄中。在PrestoDB安裝目錄下的
bin目錄中執行如下命令擷取client可執行程式。# 將PrestoDB用戶端檔案重新命名為presto。其中presto-cli-0.280-executable.jar請替換為實際所用的用戶端版本名稱。 mv presto-cli-0.280-executable.jar presto # 為使用者授予操作presto檔案的許可權。 chmod +x prestoclient可執行程式的所處目錄如下圖所示。
在PrestoDB安裝目錄下的
bin目錄中執行命令啟動Presto Server。重要啟動Presto Server時,您必須分別啟動Coordinator和至少一個Worker。
# 支援前台運行和後台運行兩種啟動方式,其中前台運行方式更方便查看作業記錄。 # 方式一:後台運行 ./launcher start # 方式二:前台運行 ./launcher run在PrestoDB安裝目錄下的
bin目錄中執行如下命令啟動SQL CLI。說明PrestoDB預設運行在8080連接埠。如果要修改連接埠配置,請修改
etc/config.properties中的http-server.http.port配置。修改部分config配置後需要重啟伺服器使配置生效。
命令中的
./presto為client可執行程式在PrestoDB安裝目錄下的bin目錄中的相對路徑。
./presto --server localhost:8080 --catalog tablestore --schema default配置項說明請參見下表。
配置項
樣本
是否必選
說明
--server
localhost:8080
是
Presto Server的URI,請根據實際替換。此項的配置必須與PrestoDB安裝目錄下
etc/config.properties檔案中的discovery.uri參數的配置相同。--catalog
tablestore
是
Catalog設定檔的名稱,此處配置為tablestore,與建立的Catalog設定檔名稱相同。
--schema
default
是
Schema配置,保持default配置即可。
步驟三:建立Schema和映射表
使用Meta表動態配置的Schema配置模式時,您需要手動建立並使用Schema用於配置對接的Tablestore執行個體和進行使用者鑒權,然後再建立Tablestore表的映射表用於資料查詢和分析。
如果使用的是本地靜態檔案配置的Schema配置模式,則無需執行此步驟。
執行如下命令建立Schema。
建立一個訪問Tablestore myinstance執行個體的Schema,Schema名稱為testdb。
CREATE SCHEMA tablestore.testdb WITH ( endpoint = 'https://myinstance.cn-hangzhou.ots.aliyuncs.com', instance_name = 'myinstance', access_id = '************************', access_key = '********************************' );具體參數配置說明請參見下表。
參數
樣本
是否必選
說明
endpoint
https://myinstance.cn-hangzhou.ots.aliyuncs.com
是
Tablestore執行個體的訪問地址。更多資訊,請參見服務地址。
instance_name
myinstance
是
Tablestore執行個體名稱。更多資訊,請參見執行個體。
access_id
************************
是
阿里雲帳號或者RAM使用者的AccessKey ID。
access_key
********************************
是
阿里雲帳號或者RAM使用者的AccessKey Secret。
執行
use <SCHEMA_NAME>;命令使用建立的Schema。其中
<SCHEMA_NAME>請替換為實際建立的Schema名稱。您可以執行show schemas;命令擷取Schema列表。執行如下命令Tablestore資料表的映射表。
重要建立映射表時,請注意如下事項:
請確保映射表中的欄位類型和表格Tablestore資料表中的欄位類型相匹配更多資訊,請參見欄位類型映射。
映射表名稱必須與Tablestore中實際的表名稱相同。
SQL語句CREATE TABLE中的table_name用於映射到Tablestore中實際的表。您可以為Tablestore中的同一個資料表建立多個不同的映射表。
映射表中必須包括資料表的所有主鍵列,但是支援只包括部分屬性列。
映射表中主鍵列的名稱和順序必須與Tablestore資料表中主鍵列的名稱和順序保持一致。映射表中每一個屬性列可通過指定 origin_name參數來映射到Tablestore中實際表內的列名。
假設資料表名為main_table,包括gid和uid兩個主鍵列以及col1、col2和col3三個屬性列。
以下SQL樣本用於為Tablestore資料表main_table建立一個同名映射表。
CREATE TABLE if not exists main_table ( gid bigint, uid bigint, c1 boolean with (origin_name = 'col1'), c2 bigint with (origin_name = 'col2'), c3 varchar with (origin_name = 'col3') ) WITH ( table_name = 'main_table' );
步驟四:使用SQL操作資料
使用SQL操作Tablestore資料前,請確保已使用use <SCHEMA_NAME>;命令使用所需Schema。
使用SQL語句查詢Schema配置、表的中繼資料以及讀寫Tablestore表中資料。更多SQL樣本,請參見常用SQL樣本。
查詢Schema配置。
擷取Schema列表
show schemas;擷取指定Schema中表列表
show tables;
查看指定表的中繼資料
其中
<TABLE_NAME>請替換為實際的表名稱。describe <TABLE_NAME>;資料操作。
讀寫Tablestore資料。
寫入資料
插入一行資料
以下樣本用於在main_table中插入一行資料。
insert into main_table values(10001,10001,true,100,'hangzhou');大量匯入資料
重要大量匯入資料前,請確保已建立目標表,且目標表的表結構與來源資料表的表結構保持一致。
以下樣本用於將main_table表中gid大於0且uid小於10000的gid、uid、c1、c2和c3列資料大量匯入到sampletable表中。
insert into sampletable select gid, uid, c1, c2, c3 from main_table where gid > 0 and uid < 100000;
讀取資料
以下樣本用於查詢sampletable表中gid列值大於0,uid列值小於10且c1等於true的行資料。
select * from sampletable where gid > 0 and uid < 10 and c1 = true;
計費說明
使用計算引擎訪問Table Store時,Table Store會根據具體的讀寫請求按照讀寫輸送量計量計費。更多資訊,請參見計費概述。
相關文檔
您可以使用MaxCompute、Spark、Function Compute、Flink等其他計算引擎查詢與分析Tablestore表中資料。更多資訊,請參見計算與分析概述。您也可以使用Table Store的SQL查詢和多元索引統計彙總功能查詢與分析表中資料。更多資訊,請參見SQL查詢介紹和多元索引介紹。
您也可以通過DataWorksData Integration服務實現Table Store資料的跨表或者跨執行個體遷移。更多資訊,請參見將Table Store資料表中資料同步到另一個資料表。
如果要以圖表等形式可視化展示資料,您可以使用DataV或者Grafana實現。更多資訊,請參見資料視覺化工具。