Tlog是一個很大範疇,其中包括Realtime Compute、資料倉儲、離線計算等眾多點。這篇文章主要介紹在Realtime Compute情境中,如何能做到Tlog保序、不丟失、不重複,並且在上下遊業務系統不可靠(存在故障)、業務流量劇烈波動情況下,如何保持這三點。
為方便理解,本文使用《銀行的一天》作為例子將概念解釋清楚。在文檔末尾,介紹Log ServiceLogStore消費組功能,如何與Spark Streaming、Storm Spout等配合,完成日誌資料的處理過程。
什麼樣的資料可以抽象成日誌?
半世紀前說起日誌,想到的是船長、操作員手裡厚厚的筆記。如今電腦誕生使得日誌產生與消費無處不在:伺服器、路由器、感應器、GPS、訂單、及各種裝置通過不同角度描述著我們生活的世界。從船長日誌中我們可以發現,日誌除了帶一個記錄的時間戳記外,可以包含幾乎任意的內容,例如:一段記錄文字、一張圖片、天氣狀況、船行方向等。半個世紀過去了,“船長日誌”的方式已經擴充到一筆訂單、一項付款記錄、一次使用者訪問、一次資料庫操作等多樣的領域。
在電腦世界中,常用的日誌有:Metric、Binlog(Database、NoSQL)、Event、Auditing、Access Log等。
在該文檔的樣本中,我們把使用者到銀行的一次操作作為一條日誌資料。其中包括使用者、帳號名、操作時間、操作類型、操作金額等。
例如:
2016-06-28 08:00:00 張三 存款 1000元美元
2016-06-27 09:00:00 李四 取款 20000元美元LogStore資料模型
為了能抽象問題,這裡以Log ServiceLogStore作為展示模型。其包含以下內容:
Log:由時間及一組Key-Value對組成。
LogGroup:一組日誌的集合,包含相同Meta(IP、Source)等。
兩者關係如下:

Shard:分區,LogGroup讀寫基本單元,可以理解以48小時為周期的FIFO隊列。每個Shard提供5 MB/s寫資料和10 MB/s讀資料能力。Shard有邏輯區間(BeginKey,EndKey)用以歸納不同類型資料。
LogStore:日誌庫,用以存放同一類日誌資料。LogStore是一個載體,通過由
[0000,FFFF..)區間Shard組合構建而成,LogStore會包含1個或多個Shard。Project:儲存LogStore的容器。
這些概念相互關係如下。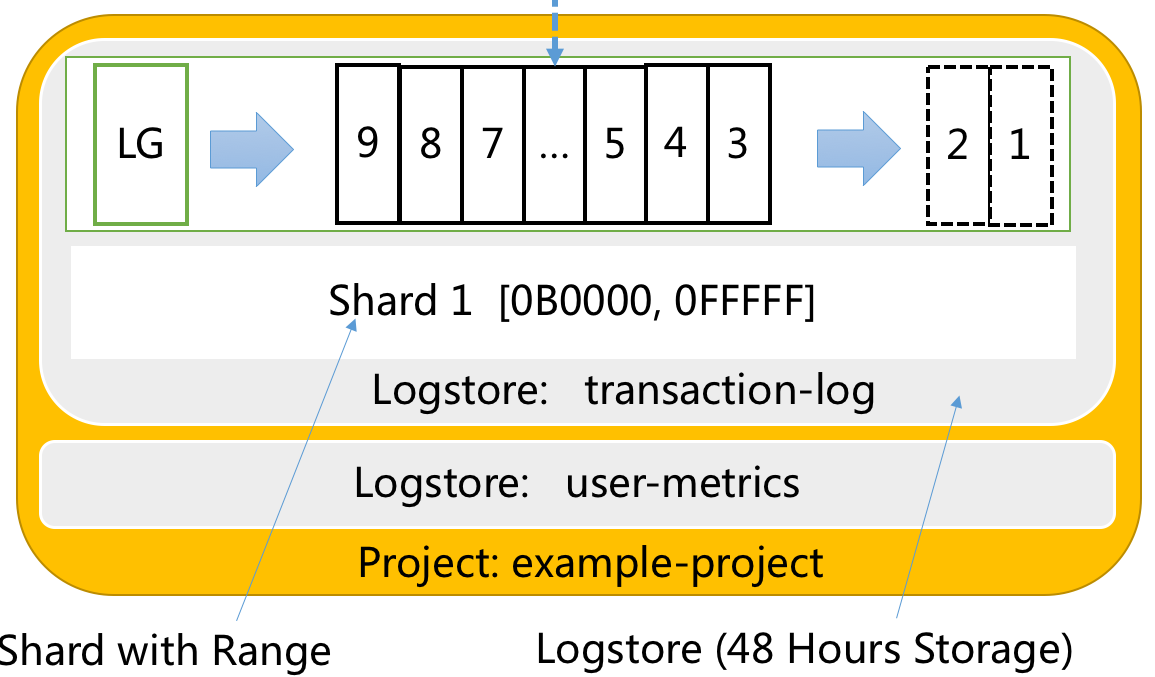
銀行的一天
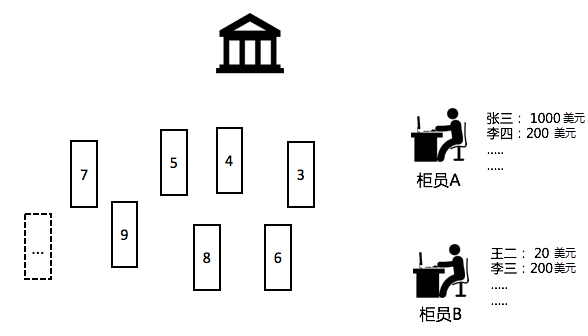
以19世紀銀行為例。某個城市有若干使用者(Producer),到銀行去存取錢(User Operation),銀行有若干個櫃員(Consumer)。因為19世紀還沒有電腦可以即時同步,因此每個櫃員都有一個小賬本能夠記錄對應資訊,每天晚上把錢和賬本拿到公司去對賬。
在分布式世界裡,我們可以把櫃員認為是固定記憶體和計算能力單機。使用者是來自各個資料來源的請求,Bank大廳是處理使用者存取資料的日誌庫(LogStore)。

該情境中,各角色及其主要操作包括:
Log/LogGroup:使用者發出的存取款等操作。
使用者(User):Log/LogGroup生產者。
櫃員(Clerk):銀行處理使用者請求的員工。
銀行大廳(LogStore):使用者產生的操作請求先進入銀行大廳,再交給櫃員處理。
分區(Shard):銀行大廳用以安排使用者請求的組織方式。
問題1:保序(Ordering)
銀行有2個櫃員(A,B),張三進了銀行,在櫃檯A上存了1000美元,A把張三1000美元存在自己的賬本上。張三到了下午覺得手頭緊到B櫃檯取錢,B櫃員一看賬本,發現不對,張三並沒有在這裡存錢。
從這個例子可以看到,存取款是一個嚴格有序的操作,需要同一個櫃員(處理器)來處理同一個使用者的操作,這樣才能保持狀態一致性。
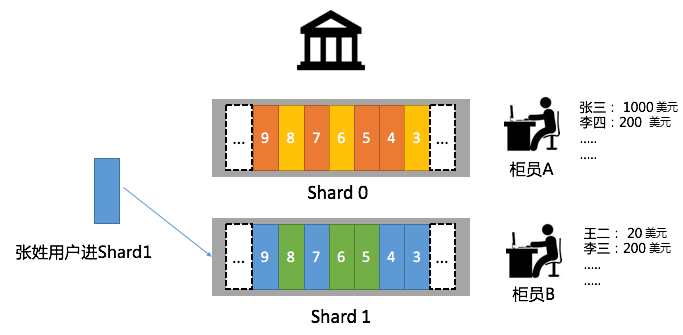
實現保序的方法很簡單:排隊,建立一個Shard,終端只有一個櫃員A來處理。使用者請求先進先出,一點問題都沒有。但帶來的問題是效率低下,假設有1000個使用者來進行操作,即使有10個櫃員也無濟於事。這種情境怎麼辦?
假設有10個櫃員,我們可以建立10個Shard。要保證10個櫃員對同一個賬戶的操作是有序的,可以根據一致性Hash方式將使用者進行映射。例如我們開10個隊伍(Shard),每個櫃員處理一個Shard,把不同銀行帳號或使用者姓名,映射到特定Shard中。在這種情況下張三Hash(Zhang)= Z落在一個特定Shard中(區間包含Z),處理端面對的一直是櫃員A。
當然如果張姓使用者比較多,也可以換其他策略。例如根據使用者AccountID、ZipCode進行Hash,這樣就可以使得每個Shard中操作請求更均勻。
問題2:不丟失(At-Least Once)
張三拿著存款在櫃檯A處理,櫃員A處理到一半去接了個電話,等回來後以為業務已經辦理好了,於是開始處理下一個使用者的請求,張三的存款請求因此被丟失。
雖然機器不會犯錯,線上時間和可靠性要比櫃員高。但難免也會遇到電腦故障、或因負載高導致的處理中斷,因為這樣的情境丟失使用者的存款,後果是無法容忍的。
A可以在自己日記本上(非賬本)記錄一個專案:當前已處理到Shard哪個位置,只有當張三的這個存款請求被完全確認後,櫃員A才能叫下一個。

帶來問題是什嗎?可能會重複。例如A已經處理完張三請求(更新賬本),準備在日記本上記錄處理到哪個位置之時,突然被叫開了,當A回來後,發現張三請求沒有記錄下來,A會把張三請求再次處理一遍,這就會造成重複。
問題3:不重複(Exactly Once)
重複是否一定會帶來問題?答案是不一定。
在等冪情況下,重複雖然會有浪費,但對結果沒有影響。什麼叫等冪:重複消費不對結果產生影響的操作叫做等冪。例如使用者有一個操作“查詢餘額”,該操作是一個唯讀操作,重複做不影響結果。對於非唯讀操作,例如登出使用者這類操作,可以連續做兩次。
但現實生活中大部分操作不是等冪的,例如存款、取款等,重複進行計算會對結果帶來致命的影響。解決的方式是什麼呢?櫃員(A)需要把賬本完成+日記本標記Shard中處理完成作為一個事務合併作業,並記錄下來(CheckPoint)。
如果A暫時離開或永久離開,其他櫃員只要使用相同的規範:記錄中已操作則處理下一個即可,如果沒有則重複做,過程中需要保證原子性。

CheckPoint可以將Shard中的元素位置(或時間)作為Key,放入一個可以持久化的對象中。代表當前元素已經被處理完成。
業務挑戰
以上三個概念解釋完成後,原理並不複雜。但在現實世界中,使用者數、處理量規模的變化與不確定性會使得以上三個問題變得更複雜。
遇到發工資的日期,使用者數會大漲。
櫃員(Clerk)畢竟不是機器人,也需要休假,需要吃午飯。
銀行經理為了整體服務體驗,需要增加櫃員。那以什麼作為判斷標準增加櫃員呢?
櫃員在交接過程中,能否非常容易地傳遞賬本與記錄?
現實中的一天
8點銀行開門。
只有一個Shard0,使用者請求全部排在Shard0下,櫃員A也正好可以處理。

10點進入高峰期。
銀行經理決定把10點後Shard0分裂成2個新Shard(Shard1,Shard2),並且給了如下規定,姓名是[A-W]使用者到Shard1中排隊,姓名是
[X, Y, Z]到Shard2中排隊等待處理。這兩個Shard區間明顯是不均勻的,因為使用者的姓氏分布就是不均勻的,通過這種映射方式可以保證櫃員處理的均衡。10~12點請求消費狀態。

櫃員A處理2個Shard非常吃力,於是經理派出櫃員B、C出場。因為只有2個Shard,B開始接管A負責一個Shard,C處於閑置狀態。
中午12點人越來越多。
銀行經理覺得Shard1下櫃員A壓力太大,因此從Shard1中拆分出(Shard3,Shard4)兩個新的Shard,Shard3由櫃員A處理、Shard4由櫃員C處理。在12點後原來排在Shard1中的請求,分別到Shard3,Shard4中。
12點後請求消費狀態。

流量持續到下午4點後,開始逐漸減少。
因此銀行經理讓櫃員A、B休息,讓C同事處理Shard2、Shard3、Shard4中的請求。並逐步將Shard2與Shard3合并成Shard5,最後將Shard5和Shard4合并成一個Shard,當處理完成Shard中所有請求後銀行關門。
現實中的Tlog
上述過程可以抽象成Tlog的經典情境,如果要解決銀行的業務需求,我們要提供Auto Scaling、並且靈活適配的日誌基礎架構,包括:
對Shard進行Auto Scaling。
消費者上線與下線能夠對Shard自動適配,過程中資料不丟失。過程中支援保序。
過程中不重複(需要消費者配合)。
觀察到消費進度,以便合理調配計算資源。
支援更多渠道日誌接入(對銀行而言開通網上銀行、手機銀行、支票等渠道,可以接入更多的使用者請求)。
您可以通過LogStore消費組解決日誌即時處理中的這些經典問題,只需把精力放在商務邏輯上,而不用去擔心流量擴容、Failover等瑣事。更多資訊,請參見通過消費組消費日誌。
另外,Spark Streaming已經通過消費組實現了對應的介面,歡迎使用。更多資訊,請參見Spark Streaming消費。