本文介紹資料加工(新版)任務啟動並執行指標詳情,如何查看資料加工儀錶盤、以及配置任務監控。
指標資料
資料加工(新版)任務的運行指標需要開啟SLS任務作業記錄,開啟任務作業記錄的具體步驟請參見管理服務日誌。
儀錶盤
建立資料加工任務後,Log Service預設為每個加工任務建立一個儀錶盤,位於資料加工任務詳情頁面。您可以在儀錶盤中查看資料加工任務運行指標。
操作步驟
在Project列表地區,單擊目標Project。

在左側導覽列中,選擇。
-
單擊目標資料加工任務,在執行狀態地區,查看儀錶盤資訊。
總覽指標
總覽指標資訊如下所示。
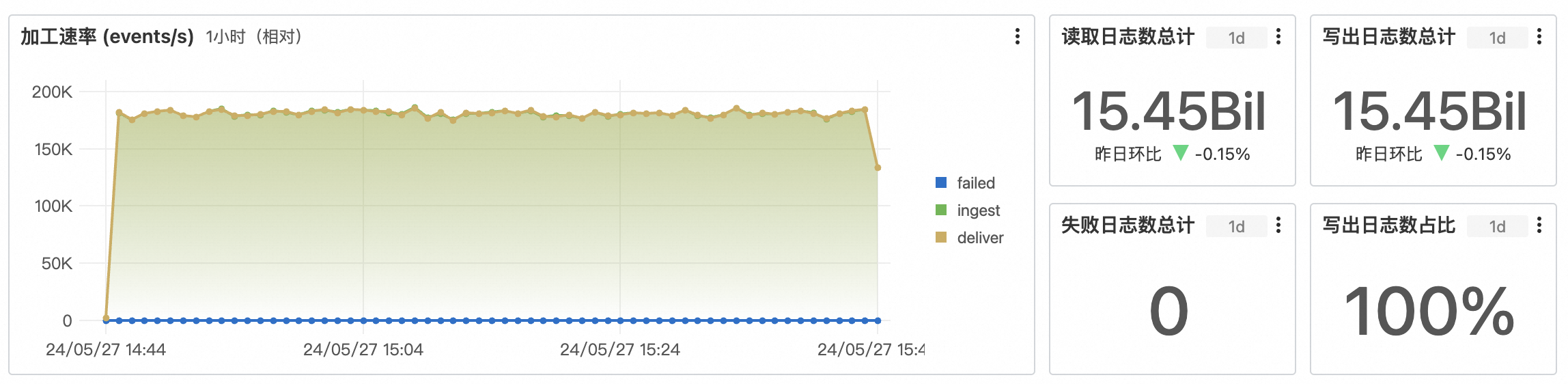
-
加工速率:預設時間周期為1小時,統計視窗為1分鐘,速率為資料條目數/秒。
-
ingest:從源LogStore的各個shard中讀到的資料條數。
-
deliver:成功寫入到目標LogStore的資料條數。
-
failed:從源LogStore的各個shard中讀取,在加工過程中發生失敗的資料條數。
-
-
讀取日誌數總計:從源LogStore的各個shard中讀取到的資料條數總計,預設時間周期為1天。
-
寫出日誌數總計:成功寫入到所有目標LogStore的資料條數總計,預設時間周期為1天。
-
失敗日誌數總計:從源LogStore的各個shard中讀取、並在加工過程中發生失敗的資料條數總計,預設時間周期為1天。
-
寫出日誌數佔比:成功投遞到目標LogStore的資料條數占源LogStore讀取到資料條數的比例,預設時間周期為1天。
Shard詳情分析
統計每分鐘視窗內,加工任務讀取源LogStore資料時,每個Shard的指標。
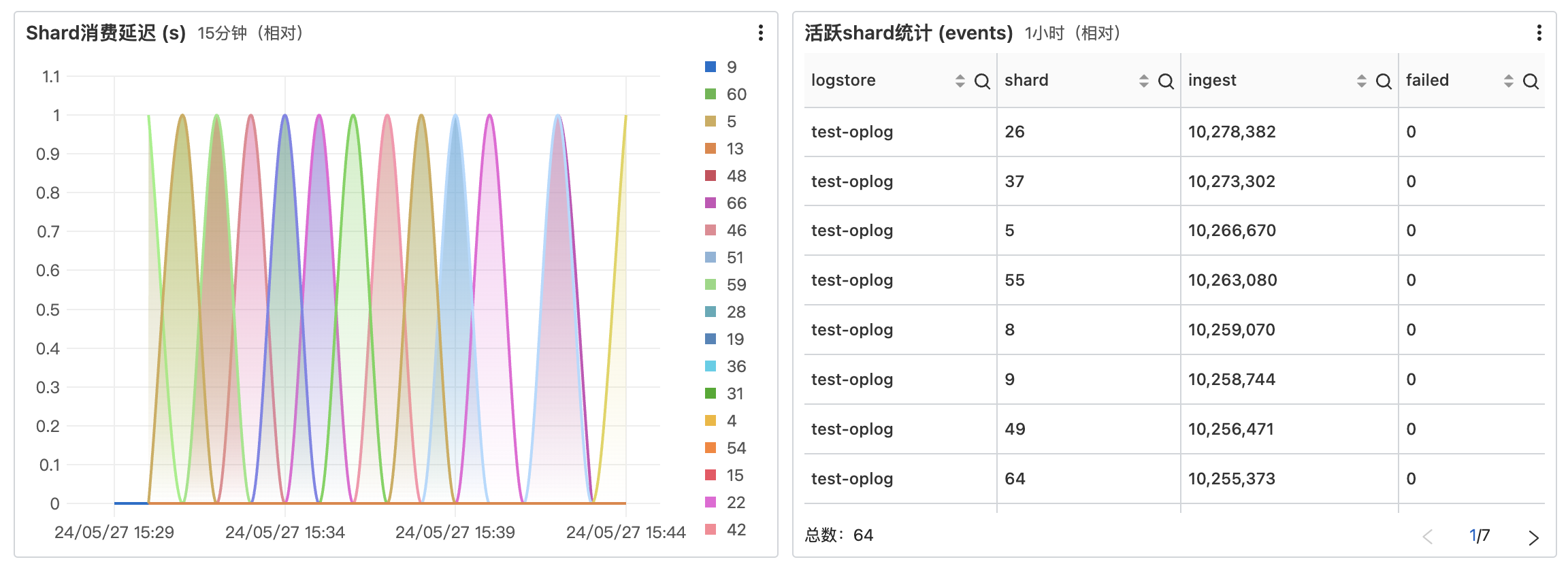
-
Shard消費延遲(s):每一個Shard中寫入的最後一條資料的接收時間,與資料加工中該Shard正在處理的資料接收時間之差,單位為秒。
-
活躍Shard統計:預設統計周期為1小時。
-
shard: 指定統計的Shard編號。
-
ingest:從該Shard中讀到的未經處理資料條數。
-
failed:從該Shard中讀到未經處理資料,並在加工過程中發生失敗的資料條數。
-
運行異常
您可以根據message欄位,查看運行報錯的細節。

警示規則
監控資料加工(新版)任務,依賴於任務運行指標,請參見指標資料。可以使用Log Service警示功能實現任務監控,請參見警示。這裡介紹如下的資料加工(新版)警示規則:處理延遲監控、處理異常報錯監控、處理流量(絕對值)監控、處理流量(同比)監控。建立警示規則請參見建立日誌警示規則。
建立資料加工(新版)警示規則添加的查詢統計的專案和日誌庫為該專案工作作業記錄儲存的專案和日誌庫。任務作業記錄儲存請參見管理服務日誌。
處理延遲監控
|
專案 |
說明 |
|
作用 |
用於監控資料加工任務中Shard消費延遲情況。當加工延遲時間長度大於規則參數中延遲監控閾值時觸發警示。 |
|
關聯儀錶盤 |
請參見Shard訊息延遲。 |
|
分析SQL範例 |
以下模板 |
|
監控規則 |
說明
為了避免資料加工(新版)按1分鐘周期更新處理指標,以及資料洪峰導致的延遲情況,導致的警示誤判,建議按照以上規則配置。 |
|
消除方法 |
請按照如下原則進行處理:
|
處理異常報錯監控
|
專案 |
說明 |
|
作用 |
用於監控資料加工任務中異常報錯。當資料加工出現異常報錯時觸發警示。 |
|
關聯儀錶盤 |
請參見運行異常。 |
|
分析SQL範例 |
以下模板 |
|
監控規則 |
|
|
消除方法 |
請按照如下對應報錯資訊進行處理:
|
寫出資料量佔比(同比)監控
|
專案 |
說明 |
|
作用 |
用於監控資料加工任務寫出至目標LogStore的處理結果資料量,與從源LogStore讀取的未經處理資料量的比例,相比昨日、以及上一周的增長閾值和下跌閾值情況。當增長大於規則參數中日/周同比增長閾值或下跌超過規則參數中日/周同比下跌閾值時觸發警示。 |
|
關聯儀錶盤 |
寫出日誌數佔比:成功投遞到目標LogStore的資料條數占源LogStore讀取到資料條數的比例,預設時間周期為1天。 |
|
分析SQL範例 |
建立警示規則的查詢統計對話方塊中輸入以下SQL。 以下模板 |
|
監控規則 |
說明
為了避免未經處理資料流量的周期性波動導致的警示誤判,建議日/周同比增長閾值和日/周同比下跌閾值設定不小於20%,或者調整同比周期,使其與未經處理資料流量的周期匹配。 |
|
消除方法 |
請按照如下原則進行處理:
|
讀取來源資料量(同比)監控
|
專案 |
說明 |
|
作用 |
用於監控資料加工任務讀取資料量相比昨日、以及上一周的增長閾值和下跌閾值情況。當增長大於規則參數中日/周同比增長閾值或下跌超過規則參數中日/周同比下跌閾值時觸發警示。 |
|
關聯儀錶盤 |
讀取日誌數總計:從源LogStore的各個shard中讀取到的資料條數總計,預設時間周期為1天。 |
|
分析SQL範例 |
建立警示規則的查詢統計對話方塊中輸入以下SQL。 以下模板 |
|
監控規則 |
說明
為了避免未經處理資料流量的周期性波動導致的警示誤判,建議日/周同比增長閾值和日/周同比下跌閾值設定不小於20%,或者調整同比周期,使其與未經處理資料流量的周期匹配。 |
|
消除方法 |
請按照如下原則進行處理:
|
寫出結果量(同比)監控
|
專案 |
說明 |
|
作用 |
用於監控資料加工任務寫出資料量相比昨日、以及上一周的增長閾值和下跌閾值情況。當增長大於規則參數中日/周同比增長閾值或下跌超過規則參數中日/周同比下跌閾值時觸發警示。 |
|
關聯儀錶盤 |
寫出日誌數總計:成功寫入到所有目標LogStore的資料條數總計,預設時間周期為1天。 |
|
分析SQL範例 |
建立警示規則的查詢統計對話方塊中輸入以下SQL。 以下模板 |
|
監控規則 |
說明
為了避免未經處理資料流量的周期性波動導致的警示誤判,建議日/周同比增長閾值和日/周同比下跌閾值設定不小於20%,或者調整同比周期,使其與未經處理資料流量的周期匹配。 |
|
消除方法 |
請按照如下原則進行處理:
|