Log Service支援聯合監控與無資料警示,本文將指導如何配置。
監控時效性說明
警示監控原理
基於警示的查詢時間範圍,根據檢查頻率定時執行配置的查詢語句,並將查詢結果作為警示條件的參數進行計算,如果計算結果為true,則觸發警示。
監控時效性問題分析
資料索引延遲:資料從寫入Log Service到被查詢之間存在延時,即便延時很低,也存在資料漏查的風險。
例如:警示執行時間為12:03:30,查詢範圍為相對一分鐘時,檢查頻率為固定間隔1分鐘。則查詢時間範圍為[12:02:30,12:03:30),對於12:03:29秒寫入的日誌,無法保證在12:03:30這個時間點查詢到。
查詢準確性:寫入包含同一分鐘不同時間的日誌時,由於Log Service的索引構建方式,可能會存在較晚的日誌的索引寫入較早的日誌時間點。
例如:警示執行時間為12:03:30,查詢範圍為相對一分鐘則為[12:02:30,12:03:30),如果在12:02:50秒寫入多條日誌,這些日誌的時間有12:02:20,12:02:50等,那麼這一批日誌的索引可能會落入12:02:20這個時間點,導致使用時間範圍[12:02:30,12:03:30)查詢不到日誌。
時效性最佳化建議
追求準確性:如果您對警示的準確性要求高(不重複警示,不漏報)。
資料索引延遲問題:建議在查詢統計時,查詢區間的相對起始時間和相對結束時間設定早一點,如70秒前~10s前(相對),通過設定10秒的緩衝時間來避免因為索引速度過低導致漏查。
查詢不準確的問題:建議在查詢統計時,查詢區間選擇整點時間,如整點1分鐘、整點5分鐘和整點1小時等,並且將檢查頻率設定成一樣的時間,如1分鐘、5分鐘和1小時等。
追求即時性:如果對警示的即時性要求高(第一時間收到警示,能夠容忍重複警示)。
資料索引延遲問題:建議在查詢統計時,查詢區間的相對起始時間往前推移,如70秒(相對)。
查詢不準確的問題:建議在查詢統計時,查詢區間至少需要包含前一分鐘,如90秒(相對),同時設定檢查頻率為1分鐘。
關聯多個查詢分析結果
Log Service警示監控系統將一個查詢和分析結果當作一個集合,並支援多個集合關聯監控,如下圖所示。
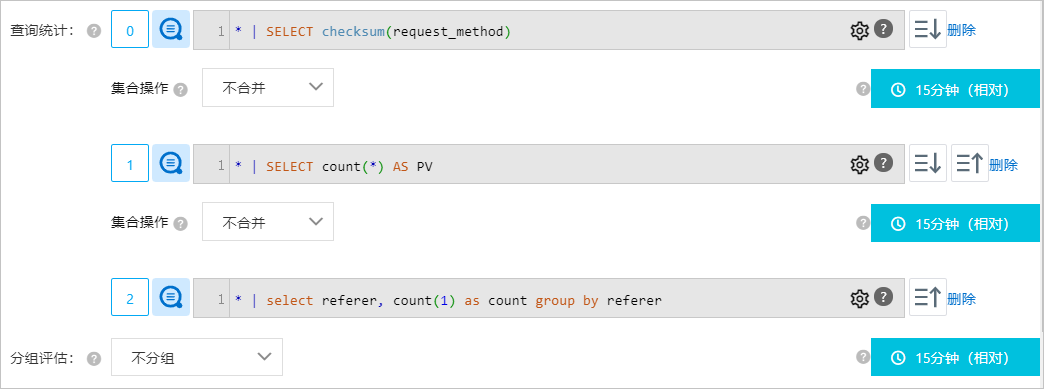
Log Service最多支援3個集合關聯監控。
預設只選取查詢和統計結果中的前1000條資料用於集合操作。當存在三個查詢和分析操作且集合操作不存在不合并選項時,只選取查詢和統計結果中的前100條資料。
當存在三個集合時,先對前兩個集合進行操作,該操作結果再與第三個集合進行集合操作。例如:
集合A左聯集合B左聯集合C:集合A和集合B先完成左聯操作,該結果再左聯集合C。
集合A拼接集合B內聯集合C:集合A和集合B完成拼接操作,該結果再內聯集合C。
集合A左斥集合B不合并集合C:集合A和集合B完成左斥操作,忽略集合C。
集合操作支援9種配置,具體如下所示:
集合操作 | 圖示 | 說明 |
| 兩個集合之間無關聯。 集合A為查詢和分析結果,集合B僅在警示資訊中作為內容範本的變數被引用。 | |
無 | 集合A與集合B任意資料互相交叉組合,一般用於過濾評估。 | |
| 集合B中的資料添加到集合A中,根據欄位對齊。 | |
| 集合A中僅保留在集合B中存在的資料,即集合B是集合A的白名單。 | |
| 在集合A中補充部分來自集合B的資訊,即集合B是A的維表。 | |
| 在集合B中補充部分來自集合A的資訊,即集合A是集合B的維表。 | |
| 集合A和集合B互相補充資訊。 | |
| 在集合A中刪除集合B中存在的資料,即集合B是集合A的黑名單。 | |
| 在集合B中刪除集合A中存在的資料,即集合A是集合B的黑名單。 |





不合并
需求
監控Nginx訪問日誌,每15分鐘的5xx錯誤超過500次則觸發警示,並且在警示內容中列出具體的出錯的主機資訊。
配置
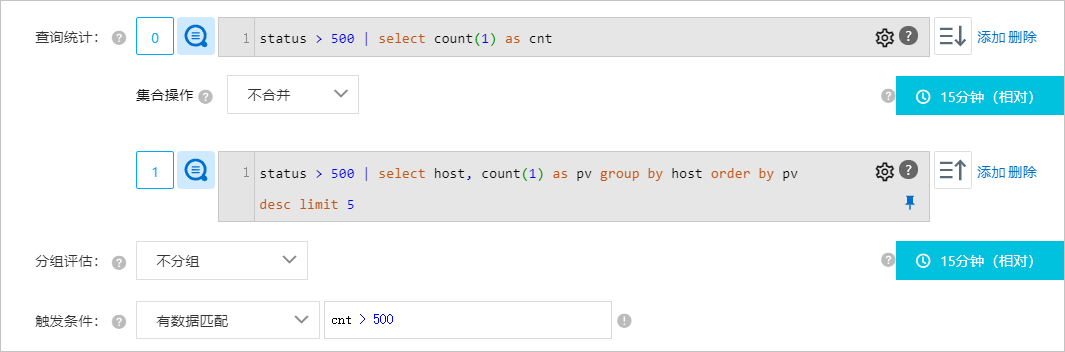
結果
查詢統計0的結果
統計15分鐘內發生5xx錯誤的次數。
cnt
1234
查詢統計1的結果
統計15分鐘內發生5xx錯誤最多的Top5主機及對應的錯誤次數。
host
pv
host1
60
host2
55
host3
47
host4
45
host5
30
集合操作結果
當選擇集合操作為不合并時,集合操作結果為查詢統計0的結果。
笛卡爾積
樣本1
需求:
同時監控OSS訪問日誌和SLB訪問日誌,每15分鐘統計一次OSS的4xx錯誤和SLB的5xx錯誤,當總次數達到1000次時觸發警示。
配置:

結果:
查詢統計0的結果
統計15分鐘內出現OSS 4xx錯誤的次數。
pv
890
查詢統計1的結果
統計15分鐘內出現SLB 5xx錯誤的次數。
pv
567
集合操作結果
當選擇集合操作為笛卡爾積時,集合操作結果如下:
$0.pv
$1.pv
890
567
其他樣本
查詢統計0結果
a
b
a1
b1
a2
b2
a5
b5
查詢統計1結果
a
c
a1
c1
a3
c3
集合操作結果
當選擇集合操作為笛卡爾積時,集合操作結果如下:
$0.a
b
$1.a
c
a1
b1
a1
c1
a1
b1
a3
c3
a2
b2
a1
c1
a2
b2
a3
c3
a5
b5
a1
c1
a5
b5
a3
c3
拼接
樣本1
需求
北京和上海地區分別有2個用於儲存Nginx訪問日誌的LogStore,每15分鐘統計一次5xx錯誤超過30次的主機數。當兩個LogStore中合格主機數超過10個時,觸發警示。
配置

結果
查詢統計0的結果
統計15分鐘內發生5xx錯誤超過30次的主機及對應的錯誤次數。
host
pv
host1
60
host2
55
host3
47
host4
45
host5
31
查詢統計1的結果
統計15分鐘內發生5xx錯誤超過30次的主機及對應的錯誤次數。
host
pv
hosta
70
hostb
45
hostc
44
hostd
42
集合操作結果
當選擇集合操作為拼接時,集合操作結果如下:
host
pv
host1
60
host2
55
host3
47
host4
45
hosg5
31
hosta
70
hostb
45
hostc
44
hostd
42
其他樣本
當2個查詢統計結果中的欄位不完全一致時,進行拼接後,無匹配的欄位留空。
查詢統計0結果
a
b
a1
b1
a2
b2
查詢統計1結果
b
c
b1
c1
b2
c2
集合操作結果
a
b
c
a1
b1
無
a2
b2
無
無
b1
c1
無
b2
c2
當存在3個查詢統計時,查詢統計0和查詢統計1的結果先完成集合操作,再與查詢統計2結果拼接。
查詢統計0結果
a
b
a1
b1
a2
b2
查詢統計1結果
a
b
a1
b11
a2
b22
a3
b33
查詢統計0結果與查詢統計1結果的拼接結果
當選擇集合操作為內聯,$0.a == $1.a時,集合操作結果如下:
a
$0.b
$1.b
a1
b1
b11
a2
b2
b22
查詢統計2結果
a
b
a3
b333
a4
b444
集合操作結果
當選擇集合操作為拼接時,集合操作結果如下:
說明查詢統計2結果中欄位b與欄位$0.b對齊。
a
$0.b
$1.b
a1
b1
b11
a2
b2
b22
a3
b333
無
a4
b444
無
內聯
樣本1
需求
監控指定Bucket中發生5xx錯誤的次數,當每15分鐘內出現1000次5xx錯誤時觸發警示。此需求中,需添加資源資料,用於維護Bucket白名單。
配置
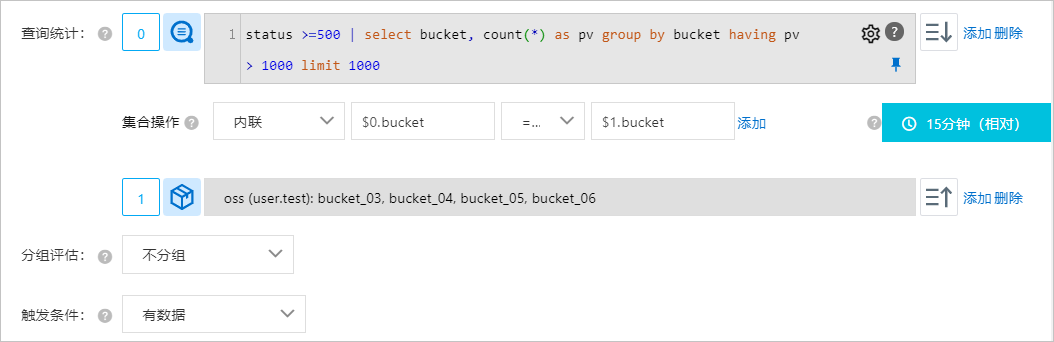
結果
查詢統計0的結果
統計15分鐘內發生5xx錯誤次數超過1000次的Bucket。
bucket
pv
bucket_01
1600
bucket_02
1550
bucket_03
1470
bucket_04
1450
查詢統計1的結果
Bucket的資源資料。
bucket
desc
bucket_03
for dev team
bucket_04
for test team
bucket_05
for service team
bucket_06
for support team
集合操作結果
當選擇集合操作為內聯,$0.bucket == $1.bucket時,集合操作結果如下:
bucket
pv
desc
bucket_03
1470
for dev team
bucket_04
1450
for test team
樣本2
需求
北京和上海地區分別有2個用於儲存Nginx訪問日誌的LogStore,每15分鐘統計一次發生5xx錯誤超過30次的用戶端。北京和上海同時發生5xx錯誤,且北京的錯誤次數大於上海時觸發警示。
配置

結果
查詢統計0結果
統計15分鐘內北京地區發生5xx錯誤超過30次的用戶端及對應的錯誤數。
client_ip
pv
192.0.2.4
60
192.0.2.5
55
192.0.2.6
47
192.0.2.7
45
192.0.2.8
31
查詢統計1結果
統計15分鐘內上海地區發生5xx錯誤超過30次的用戶端及對應的錯誤數。
client_ip
pv
192.0.2.5
70
192.0.2.6
45
192.0.2.7
44
192.0.2.8
42
192.0.2.9
42
集合操作結果
當選擇集合操作為內聯,$0.client_ip == $1.client_ip,$0.pv > $1.pv時,集合操作結果如下:
client_ip
pv
192.0.2.6
47
192.0.2.7
45
其他樣本
當2個查詢統計結果中的非關聯欄位存在同名時,集合操作的結果集合自動為欄位添加$0、$1首碼。
查詢統計0結果
a
b
c
d
a1
b1
c1
d1
a2
b2
c2
d2
a3
b3
c3
d3
查詢統計1結果
a
b
c
a1
b11
c11
a2
b22
c22
集合操作結果
當選擇集合操作為內聯,$0.a == $1.a時,集合操作結果如下:
a
$0.b
$0.c
d
$1.b
$1.c
a1
b1
c1
d1
b11
c11
a2
b2
c2
d2
b22
c22
左聯
查詢統計0結果
a
b
a1
b1
a2
b2
a3
b3
查詢統計1結果
a
b
c
a1
b11
c1
a2
b22
c2
集合操作結果
當選擇集合操作為左聯,$0.a == $1.a時,集合操作結果如下:
a
$0.b
$1.b
c
a1
b1
b11
c1
a2
b2
b22
c2
a3
b3
無
無
右聯
查詢統計0結果
a
b
c
a1
b11
c1
a2
b22
c2
查詢統計1結果
a
b
a1
b1
a2
b2
a3
b3
集合操作結果
當選擇集合操作為右聯,$0.a == $1.a時,集合操作結果如下:
a
$0.b
c
$1.b
a1
b11
c1
b1
a2
b22
c2
b2
a3
無
無
b3
全聯
查詢統計0
a
b
c
a1
b1
c1
a2
b2
c2
a5
b5
c3
查詢統計1結果
a
b
d
a1
b11
d1
a2
b22
d2
a3
b33
d3
集合操作結果
當選擇集合操作為全聯,$0.a == $1.a時,集合操作結果如下:
a
$0.b
c
$1.b
d
a1
b1
c1
b11
d1
a2
b2
c2
b22
d2
a5
b5
c3
無
無
a3
無
無
b33
d3
左斥
需求
監控除指定Bucket外的其他Bucket發生5xx錯誤的次數,當每15分鐘內出現1000次5xx錯誤時觸發警示。此需求中,需添加資源資料,用於維護Bucket黑名單。
配置

結果
查詢統計0的結果
統計15分鐘內出現5xx錯誤超過1000次的Bucket。
bucket
pv
bucket_01
60
bucket_02
55
bucket_03
47
bucket_04
45
查詢統計1的結果
Bucket的資源資料。
bucket
desc
bucket_03
for dev team
bucket_04
for test team
集合操作結果
當選擇集合操作為左斥,$0.bucket == $1.bucket時,集合操作結果如下:
bucket
pv
bucket_01
60
bucket_02
55
右斥
需求
監控除指定Bucket外的其他Bucket發生5xx錯誤的次數,當每15分鐘內出現1000次5xx錯誤時觸發警示。此需求中,需添加資源資料,用於維護Bucket黑名單。
配置

結果
查詢統計0的結果
Bucket的資源資料。
bucket
desc
bucket_03
for dev team
bucket_04
for test team
查詢統計1的結果
統計15分鐘內出現5xx錯誤超過1000次的Bucket。
bucket
pv
bucket_01
60
bucket_02
55
bucket_03
47
bucket_04
45
集合操作結果
當選擇集合操作為右斥,$0.bucket == $1.bucket時,集合操作結果如下:
bucket
pv
bucket_01
60
bucket_02
55
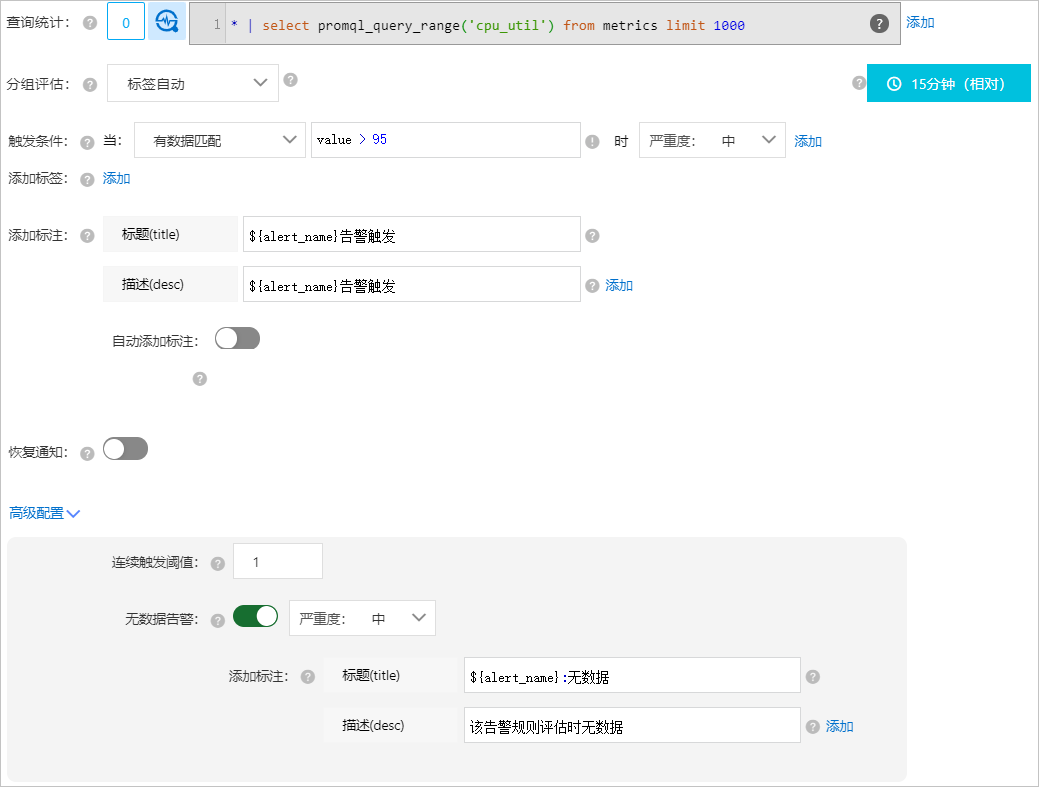
無資料警示
您可以使用無資料警示功能,避免採集過程中資料丟失無感知問題。例如您建立了一個警示監控規則用於監控各個主機的CPU指標,並希望發生如下情況時,收到警示通知。
CPU使用率超過95%。
查詢和分析結果中無資料。
具體配置如下所示:
查詢統計:例如統計CPU的使用率。
* | select promql_query_range('cpu_util') from metrics limit 1000觸發條件:有資料匹配,value>95,嚴重度:中
當查詢和分析結果中存在value的值大於95時,觸發中層級的警示。
連續觸發閾值:當累計觸發的警示次數達到該值時,產生一條警示。
無資料警示:開啟無資料警示開關,並設定嚴重度和標註資訊。
開啟無資料警示功能後,如果查詢和分析結果中無資料的次數超過連續觸發閾值,將觸發警示。
無資料警示具備獨立的警示嚴重度和標註資訊。
頁面配置展示如下圖: