在配置Logtail採集文本日誌時,如果選擇完整正則模式解析和採集日誌,需要根據您的日誌範例配置Regex。本文主要介紹在配置Regex過程中如何進行調試。
重要
本文檔可能包含第三方產品資訊,該資訊僅供參考。阿里雲對第三方產品的效能、可靠性以及操作可能帶來的潛在影響,不做任何暗示或其他形式的承諾。
功能說明
在配置Regex時,您可以使用驗證功能進行調試。
行首Regex:檢查當前設定能否正確匹配出您期望的日誌數量。
提取欄位:檢查各個欄位中的值是否是您預期的值。
如果您希望進行更多的Regex調試功能,您可以利用如Regex101等工具,將控制台為您自動產生的Regex粘貼到這些工具上,然後填充您的實際日誌範例進行檢查、調試。
說明
完整正則模式提供自動產生Regex功能,但是在為多行日誌產生Regex時,會存在問題,本文以Regex101為例進行Regex的調試和修改。
具體操作
訪問Regex101,將Log Service根據日誌範例自動產生的完整Regex拷貝到REGULAR EXPRESSION,如何產生Regex,請參見完整正則模式。
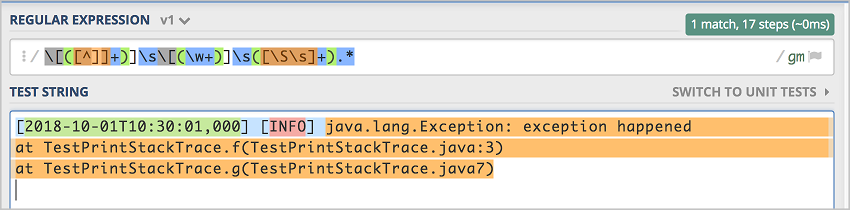
\[([^]]+)]\s\[(\w+)]\s([^:]+:\s\w+\s\w+\s[^:]+:\S+\s[^:]+:\S+\s\S+).*在介面的右側,您還可以看到該Regex的含義。

在TEST STRING中粘貼日誌範例中的日誌,at之後的內容並沒有被包含到message欄位中(藍色部分),因此該運算式不能完全符合範例日誌,即對於該範例日誌來說,這條Regex是錯誤的,使用這條Regex無法正常採集到所有日誌資料。
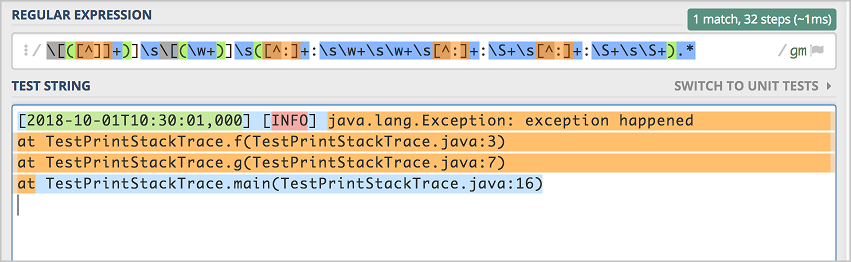
如果日誌中只有兩個冒號的情況,發現完全符合失敗。

此時將最後一個Regex替換為
[\S\s]+,並再次嘗試檢查匹配程度,能完整的匹配。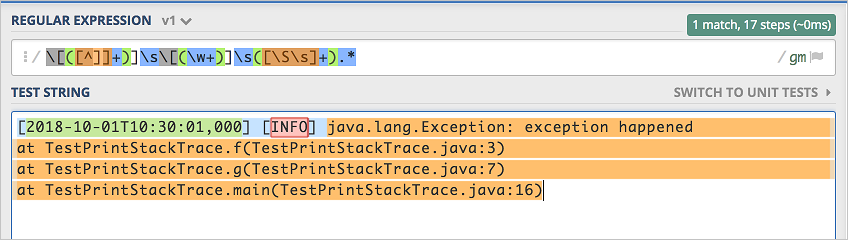 且只有兩個冒號的日誌也能完整匹配。
且只有兩個冒號的日誌也能完整匹配。