日誌審計提供一鍵式跨帳號採集雲產品日誌及中心化儲存功能。對於已開通日誌審計的阿里雲產品,Log Service預設採集所有符合限定條件的雲產品日誌。而通過採集策略,可對帳號、地區或執行個體等因素進行限制,實現精細化的日誌採集目的。本文介紹如何配置採集策略。
產品支援
採集策略目前支援RDS、PolarDB-X 1.0、PolarDB、SLB、ALB、DNS、Kubernetes容器,詳細說明如下所示。
雲產品 | 採集對象 | 屬性 | 說明 |
RDS | RDS執行個體 | 帳號:account.id | RDS執行個體所屬的阿里雲帳號ID。 |
地區:region | RDS執行個體所屬的地區,例如:cn-shanghai。 | ||
執行個體ID:instance.id | RDS執行個體ID。 | ||
執行個體名:instance.name | RDS執行個體名。 | ||
DB類型:instance.db_type | DB類型,可取值為mysql、pgsql、mssql。 | ||
DB版本號碼:instance.db_version | DB版本號碼,例如:8.0。 | ||
標籤:tag.* | 使用者自訂的標籤名。 將tag.*中的星號(*)替換為您自訂的標籤名。 | ||
PolarDB | PolarDB叢集 | 帳號:account.id | PolarDB叢集所屬的阿里雲帳號ID。 |
地區:region | PolarDB叢集所屬的地區,如cn-shanghai。 | ||
叢集ID:cluster.id | PolarDB叢集ID。 | ||
叢集名:cluster.name | PolarDB叢集名稱。 | ||
叢集相容的DB類型:cluster.db_type | PolarDB叢集相容的DB類型,目前只支援MySQL。 | ||
叢集相容的DB版本:cluster.db_version | DB版本號碼,可選值為8.0、5.7和5.6。 | ||
標籤:tag.* | 使用者自訂的標籤名。 將tag.*中的星號(*)替換為您自訂的標籤名。 | ||
PolarDB-X 1.0 | PolarDB-X 1.0執行個體 | 帳號:account.id | PolarDB-X 1.0執行個體所屬的阿里雲帳號ID。 |
地區:region | PolarDB-X 1.0執行個體所屬的地區,例如:cn-shanghai。 | ||
執行個體ID:instance.id | PolarDB-X 1.0執行個體ID。 | ||
執行個體名:instance.name | PolarDB-X 1.0執行個體名。 | ||
SLB | SLB執行個體 | 帳號:account.id | SLB執行個體所屬的阿里雲帳號ID。 |
地區:region | SLB執行個體所屬的地區,例如:cn-shanghai。 | ||
執行個體ID:instance.id | SLB執行個體ID。 | ||
執行個體名:instance.name | SLB執行個體名。 | ||
網路類型:instance.network_type | SLB網路類型,包括Virtual Private Cloud和傳統網路(Classic)。 | ||
VPC ID:instance.vpc_id | SLB執行個體所屬的Virtual Private Cloud ID。 | ||
地址類型:instance.address_type | SLB執行個體的地址類型,包括阿里雲內網(intranet)和公網(internet)。 | ||
標籤:tag.* | 使用者自訂的標籤名。 將tag.*中的星號(*)替換為您自訂的標籤名。 | ||
ALB | ALB執行個體 | 帳號:account.id | ALB執行個體所屬的阿里雲帳號ID。 |
地區:region | ALB執行個體所屬的地區,例如:cn-shanghai。 | ||
執行個體ID:instance.id | ALB執行個體ID。 | ||
執行個體名:instance.name | ALB執行個體名。 | ||
VPC ID:instance.vpc_id | ALB執行個體所屬的Virtual Private Cloud ID。 | ||
地址類型:instance.address_type | ALB執行個體的地址類型,包括阿里雲內網(Intranet)和公網(Internet)。 | ||
標籤:tag.* | 使用者自訂的標籤名。 將tag.*中的星號(*)替換為您自訂的標籤名。 | ||
DNS內網 | VPC執行個體 | 帳號:account.id | VPC執行個體所屬的阿里雲帳號ID。 |
地區:region | VPC執行個體所在的地區。 | ||
執行個體ID:instance.id | VPC執行個體ID。 | ||
執行個體名:instance.name | VPC執行個體名。 | ||
標籤:tag.* | 使用者自訂的標籤名。 將tag.*中的星號(*)替換為您自訂的標籤名。 | ||
DNS 公網解析日誌和全域流量管理日誌 | 網域名稱 | 帳號:account.id | 網域名稱所屬的阿里雲帳號ID。 |
網域名稱:domain | 網域名稱Domain。 | ||
Kubernetes容器(Kubernetes審計日誌) | Kubernetes叢集 | 地區:region | Kubernetes叢集所屬地區,例如:cn-shanghai。 |
叢集ID:cluster.id | Kubernetes叢集ID。 | ||
叢集名:cluster.name | Kubernetes叢集名稱。 | ||
叢集類型:cluster.type | Kubernetes叢集類型,包括專有版Kubernetes Kubernetes、託管版Kubernetes ManagedKubernetes、Serverless Kubernetes ASK。 | ||
網路類型:cluster.network_mode | Kubernetes叢集的網路類型,包括Virtual Private Cloud和傳統網路(Classic)。 | ||
標籤:tag.* | 使用者自訂的標籤名。 將tag.*中的星號(*)替換為您自訂的標籤名。 | ||
Kubernetes容器(Kubernetes事件中心) | Kubernetes叢集 | 地區:region | Kubernetes叢集所屬地區,例如:cn-shanghai。 |
叢集ID:cluster.id | Kubernetes叢集ID。 | ||
叢集名:cluster.name | Kubernetes叢集名稱。 | ||
叢集類型:cluster.type | Kubernetes叢集類型,包括專有版Kubernetes、託管版Kubernetes、Serverless Kubernetes。 | ||
網路類型:cluster.network_mode | Kubernetes叢集的網路類型,包括專用網路和傳統網路。 | ||
標籤:tag.* | 使用者自訂的標籤名。 將tag.*中的星號(*)替換為您自訂的標籤名。 | ||
Kubernetes容器( Ingress訪問日誌) | Kubernetes叢集 | 地區:region | Kubernetes叢集所屬地區,例如:cn-shanghai。 |
叢集ID:cluster.id | Kubernetes叢集ID。 | ||
叢集名:cluster.name | Kubernetes叢集名稱。 | ||
叢集類型:cluster.type | Kubernetes叢集類型,包括專有版Kubernetes、託管版Kubernetes、Serverless Kubernetes。 | ||
網路類型:cluster.network_mode | Kubernetes叢集的網路類型,包括Virtual Private Cloud和傳統網路(Classic)。 | ||
標籤:tag.* | 使用者自訂的標籤名。 將tag.*中的星號(*)替換為您自訂的標籤名。 | ||
日誌內容:log.* | 日誌內容。 |
配置採集策略
進入日誌審計服務頁面。
說明自2025年1月21日起,日誌審計服務控制台入口已移除。但存量使用者(2025年1月21日前開通)仍可見。新增使用者如需使用舊版,可訪問新版日誌審計服務,利用其返回舊版功能。
在日誌應用地區的審計與安全頁簽,單擊新版日誌審計服務。

在新版日誌審計頁面右上方,單擊返回舊版,您可以繼續使用日誌審計(舊版)的各項功能。

選擇,單擊修改。
單擊目標雲產品右側的採集策略。
配置採集策略。
Log Service支援通過預設採集策略模式或進階編輯模式配置採集策略。預設採集策略模式配置簡單,當預設採集策略模式無法滿足您的需求時,可開啟進階編輯模式,靈活配置複雜的採集策略。
說明您可以根據實際需求,配置多條採集策略。
在進階編輯模式下,您可以手動編輯策略語句,但在手動編輯策略語句後,無法返回到預設採集策略模式。
在進階編輯模式下,清空策略語句並儲存,再次開啟可恢複到預設採集策略模式。
預設採集策略
在待添加策略地區,配置如下參數,並單擊添加策略。
說明如果開啟預設採集策略的保留開關,則說明採集策略的最後一行為
accept "*"(預設策略--接受);如果關閉預設採集策略的保留開關,則說明採集策略的最後一行為drop "*"(預設策略--丟棄)。
參數
說明
動作
通過您配置的採集策略,執行相應的動作。更多資訊,請參見策略文法。
屬性
選擇採集對象的屬性,不同採集對象對應的屬性不同。更多資訊,請參見產品支援。
操作符
選擇操作符,例如選擇完全符合,則對應的操作符為==。更多資訊,請參見策略文法。
屬性取值
輸入屬性的值,支援配置多個屬性值。
在已添加策略地區,確認策略配置結果。
您也可以修改已添加的採集策略以及調整採集策略的順序。
單擊目標採集策略右側的編輯,修改已添加的採集策略。
單擊目標採集策略右側的上下箭頭,調整採集策略的順序。

確認無誤後,單擊確定。
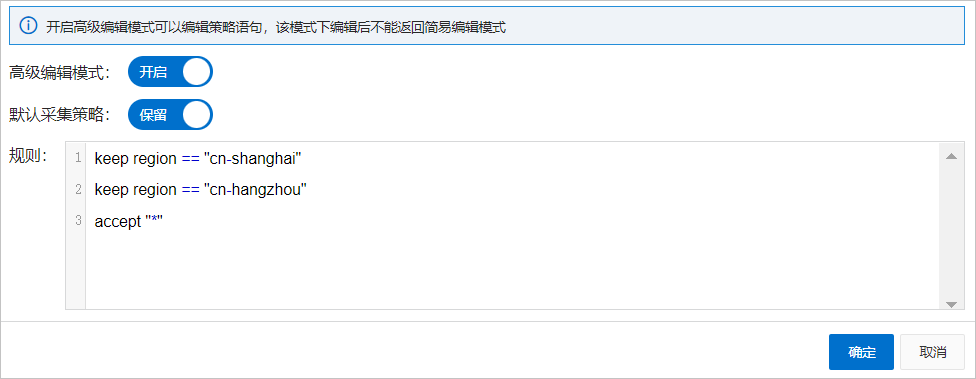
進階編輯模式
開啟進階編輯模式。
在規則文字框中,配置採集策略,並單擊確定。
詳細的文法說明請參見策略文法。
在全域配置頁面,單擊確定。
策略文法
動作
保持(keep):當採集對象滿足採集策略時繼續執行下一條策略,由後續策略判斷是否採集日誌。不滿足則拒絕採集日誌,不再做後續策略判斷。
拒絕(drop):當採集對象滿足採集策略時拒絕採集日誌,不再執行下一條策略。不滿足則繼續執行下一條策略,由後續策略判斷是否採集。
接受(accept):當採集對象滿足採集策略時採集日誌,不再執行下一條策略。不滿足則繼續執行下一條策略,由後續策略判斷是否採集。
匹配模式
匹配模式
說明
完全符合
通過字串的完全符合,進行採集策略的匹配。
操作符:==
樣本:keep instance.db_type == "mysql"表示MySQL類型的RDS執行個體通過當前判斷。
萬用字元匹配
通過萬用字元星號(*)和半形問號(?)進行採集策略的匹配。星號(*) 表示0個或多個字元,半形問號(?)表示一個字元。
操作符:==
樣本:
keep instance.name == "backend*" 表示執行個體名以backend開頭的執行個體,通過當前判斷。
keep instance.name == "active?"表示執行個體名以active開頭且其後面還有一個任一字元的執行個體,通過當前判斷。
Regex匹配
通過Regex進行採集策略的匹配。
操作符:~=
樣本:keep instance.name ~= "^\d+$"表示純數位執行個體名通過當前判斷。
說明預設為部分匹配,如果需要完全符合,需要在開頭和結尾加上^和$。
數值比較
對數值進行比較。
操作符:
直接比較:>、>=、=、<=、<
閉區間比較:: [*, 100],支援用星號(*)表示無邊界。
樣本:
keep tag.level >= 2表示tag.level大於等於2的執行個體,通過當前判斷。
keep tag.level : [*, 10]表示tag.level小於等於10的執行個體,通過當前判斷。
keep tag.level : [1, 10]表示tag.level位於[1, 10]之間的執行個體,通過當前判斷。
邏輯關係
關鍵字:
且:使用and、AND、&&等關鍵詞,不區分大小寫。
或:使用or、OR等關鍵詞,不區分大小寫。
否:使用not,NOT,驚嘆號(!)等關鍵詞,不區分大小寫。
樣本:
keep (tag.level > 10) and (region == "cn-shanghai")表示tag.level大於10且位於上海的執行個體,通過當前判斷。
keep (tag.level > 10) or (region == "cn-shanghai")表示tag.level大於10或位於上海的執行個體,通過當前判斷。
keep not region == "cn-shanghai"表示非上海的樣本,通過當前判斷。
全域匹配
如果策略中沒有指定屬性名稱,則表示全域匹配。例如:
keep "abc"表示含有abc字串的採集項都可以通過當前判斷。
accept "*"表示接受所有採集項。
說明全域匹配,必須帶雙引號(" ")。
僅在進階編輯模式下,支援全域匹配。
字元轉義
採集策略中,需要對星號(*)、反斜線(\)等特殊字元進行轉義,例如:keep instance.name == "abc\*"表示執行個體名為abc*的執行個體通過當前判斷。
常見案例
採集特定地區的執行個體日誌
例如:只採集中國地區的執行個體日誌,採集策略如下所示。
# only scan cn region keep region == "cn-*" # accept by default accept "*"採集特定標籤的執行個體日誌
例如:只採集所有標籤打上type值是production(大小寫不敏感)的執行個體日誌,採集策略如下所示。
# only scan "production" instances keep tag.type ~= "(?i)^production$" # accept by default accept "*"複雜情境
例如:只採集RDS MySQL執行個體日誌,但是如果標籤打上level: high的執行個體,無論資料庫類型是MySQL、SQL Server或PostgreSQL,都採集,採集策略如下所示。
# accept all high level instances accept tag.level == "high" # only scan mysql keep instance.db_type == "mysql" # accept by default accept "*"