負載平衡會根據配置的調度演算法,將來自用戶端的請求按照對應的演算法規則轉寄至相應的後端伺服器。負載平衡支援輪詢、加權輪詢、加權最小串連數、一致性雜湊等多種調度演算法,用於支援不同的業務情境。
本文列出所有負載平衡系列產品支援的調度演算法,不同負載平衡產品支援的調度演算法不同。
應用型負載平衡ALB:加權輪詢、加權最小串連數、一致性雜湊(源IP、URL參數)。
網路型負載平衡NLB:輪詢、加權輪詢、加權最小串連數、一致性雜湊(源IP、四元組、QUIC ID)。
傳統型負載平衡CLB:輪詢、加權輪詢、一致性雜湊(源IP、四元組、QUIC ID)。
輪詢演算法
介紹
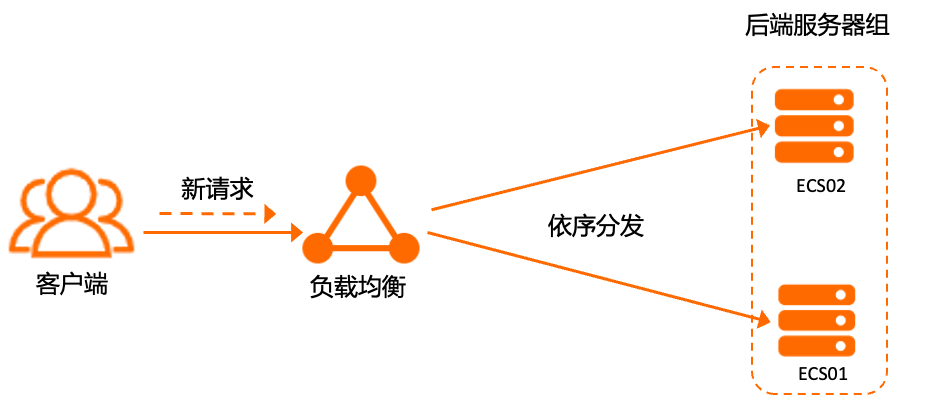
輪詢演算法按照訪問順序將外部請求依序分發到後端伺服器。輪詢演算法常用於短串連服務,例如HTTP等服務。
例如負載平衡後端伺服器組掛載了2個ECS,則用戶端新請求將在後端伺服器之間輪流分發。
優點
實現簡單:輪詢演算法是一種最基本的負載平衡演算法,實現非常簡單,容易理解和維護。
均衡性好:輪詢演算法可以很好地將請求均勻地分配到各個伺服器上,使得各個伺服器的負載相對平均。
缺點
伺服器效能不能有較大差異:輪詢演算法無法區分伺服器的實際負載情況,如果伺服器的效能不同,可能會導致某些伺服器過載,而其他伺服器處於空閑狀態。
串連可能被長時間佔用:輪詢演算法無法考慮串連的期間,如果某些串連需要較長時間才能完成,可能會導致其他串連需要等待較長時間。
適用情境
伺服器效能相似:如果伺服器的效能相似,輪詢演算法可以很好地實現負載平衡,將請求均勻地分配到各個伺服器上。
簡單情境:對於簡單的應用情境,不需要考慮伺服器的實際負載情況或串連的期間,輪詢演算法可以是一個簡單且有效選擇。
加權輪詢演算法
介紹
加權輪詢演算法在輪詢演算法的基礎上引入了權重的概念,對伺服器的負載分配更加靈活。權重值越高的後端伺服器,被輪詢到的機率也越高。加權輪詢演算法常用於短串連服務,例如HTTP等服務。
例如負載平衡後端伺服器組掛載了2個ECS,分配的權重分別為60、40,則用戶端新請求轉寄到相應後端伺服器的機率為60%、40%。

優點
靈活性:加權輪詢演算法可以根據伺服器的效能和處理能力設定不同的權重,實現對不同伺服器的靈活調度,使得效能較好的伺服器能夠處理更多的請求。
均衡性:加權輪詢演算法仍然能夠保持請求的均衡性,將請求按照權重進行分配,使得各個伺服器的負載相對平均。
缺點
配置複雜:相比於簡單的輪詢演算法,加權輪詢演算法需要配置每個伺服器的權重,對於大量伺服器或頻繁變動的情境,配置和維護工作量較大。
需要準確的權重設定:權重設定不準確可能會導致負載不均衡的情況,需要根據伺服器的實際效能進行調整。
適用情境
伺服器效能不同:當伺服器的效能存在差異時,可以通過設定不同的權重來實現負載平衡,使得效能較好的伺服器能夠處理更多的請求。
動態負載調度:當伺服器的效能和負載情況經常發生變化時,可以通過動態調整權重來適應不同的情境,實現負載平衡。
需要更精細的負載分配:當對伺服器的負載分配有更精細的要求時,可以通過設定不同的權重來實現對伺服器的靈活調度。
加權最小串連數演算法
介紹
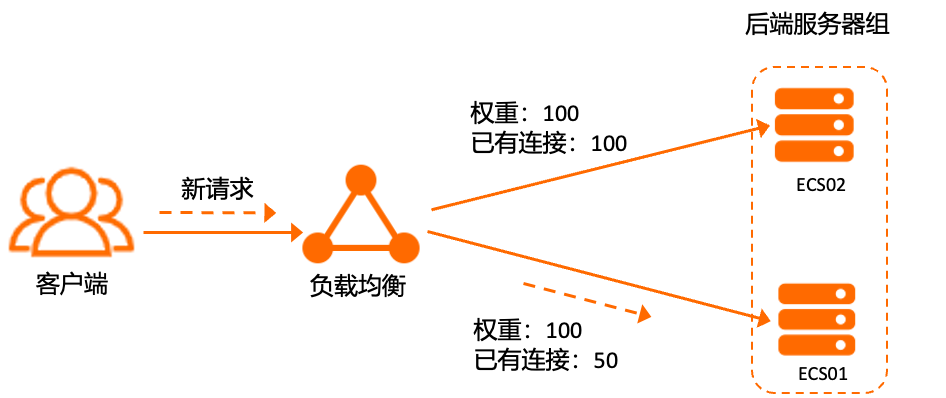
加權最小串連數演算法除了根據每台後端伺服器設定的權重值來進行輪詢,同時還考慮負載平衡服務與後端伺服器的實際串連數。當權重值相同時,當前串連數越小的後端伺服器被輪詢到的次數(機率)也越高。加權最小串連數演算法常用於長串連服務,例如資料庫連接等服務。
例如負載平衡後端伺服器組掛載了2個ECS,分配的權重均為100,當前串連數分別為100、50,則用戶端新請求將優先轉寄到串連數較少的後端伺服器。
優點
動態效能調整:加權最小串連數演算法可以根據伺服器的當前串連數和權重來進行動態調整,將請求發送到串連數最少且效能較好的伺服器上,實現負載平衡。
負載平衡效果好:由於演算法會考慮伺服器的串連數和權重,加權最小串連數演算法可以實現更精確的負載平衡,將請求合理地分配到各個伺服器上,避免出現過載或閒置情況。
缺點
演算法複雜性高:相比於輪詢演算法或加權輪詢演算法,加權最小串連數演算法的實現較為複雜,需要即時監控負載平衡服務與後端伺服器之間的串連數,並進行計算和選擇。
對伺服器串連數的依賴:演算法依賴於準確擷取負載平衡服務和後端伺服器的串連數,如果擷取不準確或監控不及時,可能導致負載分配不均衡。同時由於演算法只能統計到負載平衡服務與後端伺服器之間的串連,後端伺服器整體串連數無法擷取,因此對於後端伺服器掛載到多個Server Load Balancer執行個體的情境,也可能導致負載分配不均衡。
新增後端伺服器時可能導致新伺服器瞬間壓力過大:如果存量的串連數過大,當有新的伺服器加入時,大量的建立串連會被調度到新加入的伺服器上,可能會導致新伺服器瞬間壓力過大影響系統穩定性。
適用情境
伺服器效能差異較大:當伺服器的效能差異較大時,通過考慮串連數和權重來進行負載平衡,可以更精確地將請求分配到效能較好的伺服器上。
動態負載調度:當伺服器的串連數和負載情況經常發生變化時,可以通過即時監控串連數並進行動態調整,實現動態負載平衡。
高穩定性要求:對於需要即時響應和高穩定性的應用情境,通過加權最小串連數演算法可以降低伺服器的負載,提高系統的穩定性和可靠性。
一致性雜湊演算法
介紹
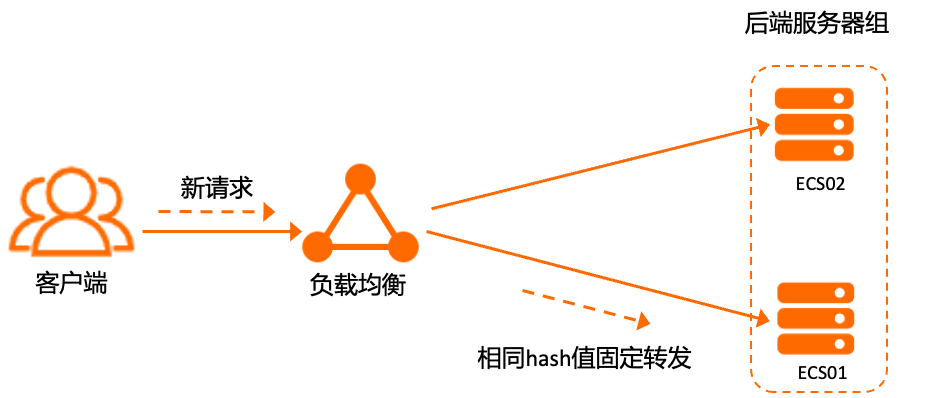
一致性雜湊演算法根據不同的雜湊因子將訪問請求均勻地分配到後端伺服器,並在後端伺服器個數發生變化時,依然保持均勻分配。相同雜湊因子計算結果的請求,將會調度到相同的後端伺服器。
包括如下雜湊因子:
源IP雜湊:根據請求的源IP地址進行雜湊計算。相同源IP的請求會分發到同一台後端伺服器。
四元組雜湊:根據請求的四元組(源IP、源連接埠、目標IP、目標連接埠)進行雜湊計算。相同四元組的請求會分發到同一台後端伺服器。
QUIC ID雜湊:根據請求的QUIC ID進行雜湊計算。由於QUIC ID是QUIC串連的唯一識別碼,使用它進行負載平衡可以實現基於串連層級的負載分配。相同QUIC串連的請求會分發到同一台後端伺服器。
URL參數雜湊:根據請求的URL參數進行雜湊計算。相同URL參數的請求會分發到同一台後端伺服器。
例如負載平衡後端伺服器組掛載了2個ECS,上次請求已轉寄至ECS01進行處理,如果新請求計算後的hash值相同,則用戶端新請求將轉寄到ECS01上。
優點
會話保持:一致性雜湊演算法可以確保同一hash值的請求會被分配到同一台伺服器上,從而實現了會話的保持。這對於需要保持使用者狀態或會話的應用非常重要。
均衡性:一致性雜湊演算法能夠提供較好的負載平衡效果,因為相同的雜湊因子經過雜湊計算後,會被分配到同一台伺服器上,使得負載相對均衡。
缺點
後端伺服器變動可能導致資料不均衡:一致性雜湊演算法在伺服器數量變動時,演算法會儘力保障請求一致性,部分請求會重新調度,當後端伺服器數量越多時,重新調度的請求會越少。當後端伺服器數量較少時,重新分配過程中有可能導致資料不均衡的情況發生。
擴充複雜性增加:由於一致性雜湊演算法將請求根據雜湊因子進行雜湊計算,當有新的伺服器加入或舊的伺服器離開時,會導致一部分請求需要重新分配,這會引入一定的複雜性。
適用情境
會話保持:對於需要保持使用者狀態或會話的應用,一致性雜湊演算法可以確保相同雜湊因子的請求會被分配到同一台伺服器上,實現會話的連續性。
均衡性要求較高:對於負載平衡要求較高的情境,一致性雜湊演算法能夠提供相對均衡的負載分配效果,減少伺服器的負載差異。
需要保持資料一致性:對於某些應用情境,需要保持資料的一致性,將相同雜湊因子的請求分配到同一台伺服器上可以避免資料不一致的問題。
QUIC ID雜湊演算法,僅適用於基於QUIC協議的應用,對於其他協議不適用。QUIC協議正在快速演化,無法保證所有QUIC版本的相容性,建議充分測試後再用於生產環境。
NLB與CLB支援QUIC ID雜湊演算法,支援的QUIC協議版本為Q10、Q29。
相關文檔
您可參考下列文檔瞭解相應的負載平衡產品及差異: