您在使用CLB的過程中如果遇到健全狀態檢查相關的問題,您可參考本文進行定位及處理。
包含以下問題:
問題類別 | 常見問題 |
原理配置 | |
異常處理 | |
日誌問題 |
健全狀態檢查的原理是什嗎?
健全狀態檢查是通過定期發送請求來確認伺服器的狀態。
CLB採用叢集部署,叢集內的節點伺服器同時負責資料轉寄和健全狀態檢查。如果某台伺服器健全狀態檢查失敗,則不會再將新的用戶端請求分發給該異常伺服器。
CLB健全狀態檢查使用的位址區段是100.64.0.0/10,後端伺服器務必不能屏蔽該位址區段。您無需在ECS安全性群組中額外配置允許存取策略,但如有配置iptables等安全性原則,請務必允許存取(100.64.0.0/10 是阿里雲保留地址,不會存在安全風險)。

更多資訊,請參見CLB健全狀態檢查。
推薦的健全狀態檢查配置是什嗎?
以下是建議使用的健全狀態檢查配置。
配置 | TCP/HTTP/HTTPS監聽推薦值 | UDP監聽推薦值 |
健全狀態檢查響應逾時時間 | 5秒 | 10秒 |
健全狀態檢查間隔時間 | 2秒 | 5秒 |
健全狀態檢查健康閾值 | 3次 | 3次 |
健全狀態檢查不健康閾值 | 3次 | 3次 |
為了避免頻繁切換影響系統可用性,健全狀態檢查需在時間視窗內連續多次成功或失敗後才會切換狀態。更多資訊,請參見配置和管理CLB健全狀態檢查。
此配置有助於服務和應用狀態的快速收斂。如有更高要求,可適當降低響應逾時時間,但需確保服務處理時間小於該值。
是否可以關閉健全狀態檢查?
可以關閉。具體操作,請參見關閉健全狀態檢查。
關閉健全狀態檢查後,負載平衡仍會將請求轉寄到異常的ECS執行個體,可能導致部分業務不可訪問。
如果您的業務對負載敏感性高,高頻率的健全狀態檢查可能影響正常業務訪問。您可以通過降低健全狀態檢查頻率、增大間隔、或改為四層檢查來減少影響。但為了保障業務的持續可用,不建議關閉健全狀態檢查。
TCP監聽如何選擇健全狀態檢查方式?
TCP監聽支援HTTP和TCP兩種健全狀態檢查方式:
TCP協議健全狀態檢查通過發送SYN握手報文,檢測伺服器連接埠是否存活。
HTTP協議健全狀態檢查通過發送HEAD或GET請求,類比瀏覽器的訪問行為來檢查伺服器應用是否健康。
TCP健全狀態檢查方式對伺服器的效能資源消耗相對要少一些。如果您對後端伺服器的負載高度敏感且只需確認連接埠存活,則選擇TCP健全狀態檢查;如果需要更準確地確認應用的健康狀態,則選擇HTTP健全狀態檢查。
ECS執行個體權重設定為零對健全狀態檢查有什麼影響?
首先,負載平衡不會再將流量轉寄給權重為零的ECS執行個體,監聽的後端伺服器健全狀態檢查不會顯示異常。然後,將負載平衡後端ECS執行個體的權重設為零,相當於將該ECS執行個體移出負載平衡。一般是在ECS執行個體進行重啟和配置調整等主動營運時將其權重設定為零。
HTTP監聽向後端ECS執行個體執行健全狀態檢查預設使用的方法是什嗎?
HEAD方法。
如果後端ECS執行個體的服務關閉HEAD方法,會導致健全狀態檢查失敗。建議在ECS執行個體上用HEAD方法訪問自己IP地址進行測試:
curl -v -0 -I -H "Host:" -X HEAD http://IP:portHTTP監聽向後端ECS執行個體執行健全狀態檢查的IP地址是什嗎?
CLB健全狀態檢查使用的位址區段是100.64.0.0/10。後端伺服器務必不能屏蔽該位址區段。您無需在ECS安全性群組中額外配置允許存取策略,但如有配置iptables等安全性原則,請務必允許存取。100.64.0.0/10是阿里雲保留地址,其他使用者無法分配到該網段內,不會存在安全風險。
CLB健全狀態檢查何時啟動?
CLB配置健全狀態檢查後,健全狀態檢查會立即啟動,並按照設定的健全狀態檢查周期定期發送健全狀態檢查請求。
負載平衡因後端資料庫故障導致健全狀態檢查失敗,如何處理?
問題現象
ECS執行個體內配置了兩個網站:
www.example.com(靜態網站)和aliyundoc.com(動態網站),且都配置了負載平衡。後端資料庫服務異常,導致訪問www.example.com出現502錯誤。問題原因
負載平衡健全狀態檢查配置的檢查網域名稱是
aliyundoc.com,由於RDS或自建資料庫故障,導致aliyundoc.com訪問異常,健全狀態檢查失敗。解決方案
將負載平衡健全狀態檢查網域名稱配置為
www.example.com即可。
負載平衡服務TCP連接埠健全狀態檢查成功,為什麼在後端業務日誌中出現網路連接異常資訊?
問題現象
負載平衡後端配置TCP服務連接埠後,後端業務日誌中頻繁出現網路連接異常錯誤資訊。抓包分析發現請求來自負載平衡伺服器,且負載平衡主動發送了RST資料包。
問題原因
該問題與負載平衡的健全狀態檢查機制有關。負載平衡對TCP協議服務連接埠的健全狀態檢查只做TCP三向交握,然後發送RST包中斷連線。具體流程如下:
負載平衡伺服器發送SYN請求包。
後端伺服器返回SYN+ACK應答包。
負載平衡伺服器收到應答後,認為連接埠正常,健全狀態檢查成功。
負載平衡伺服器發送RST包關閉串連,未繼續發送業務資料。
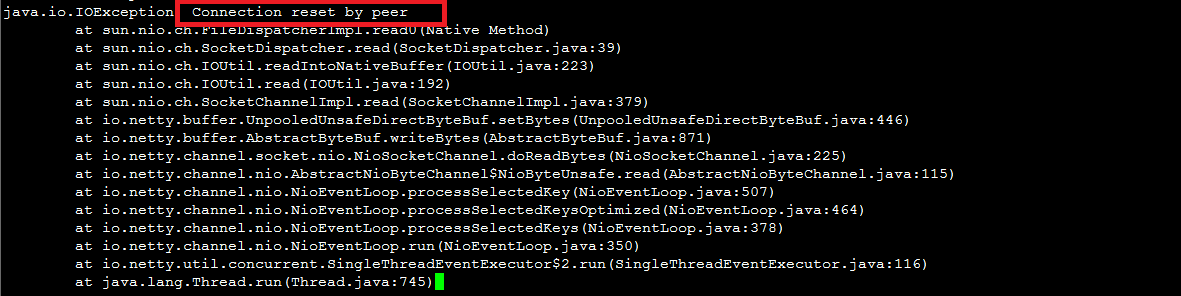
由於健全狀態檢查成功後直接中斷連線,上層業務(如Java串連池)認為串連異常,出現
Connection reset by peer等錯誤資訊。解決方案
更換TCP協議為HTTP協議。
在業務層面,對來自SLB伺服器IP位址區段的請求做日誌過濾,忽略相關錯誤資訊。
為什麼業務本身沒有異常但是健全狀態檢查顯示異常?
問題現象
負載平衡HTTP方式的健全狀態檢查始終失敗,但測試
curl得到的狀態代碼是正常的。問題原因
如果返回的狀態代碼與控制台配置的正常狀態代碼不一致,則判定健全狀態檢查異常。例如,配置的正常狀態代碼為http_2xx時,所有非HTTP 2xx狀態代碼均被認為是健全狀態檢查失敗。
Tengine/Nginx配置中,執行
curl命令沒有問題,但執行echo命令會匹配到預設網站,導致測試檔案test.html返回404錯誤。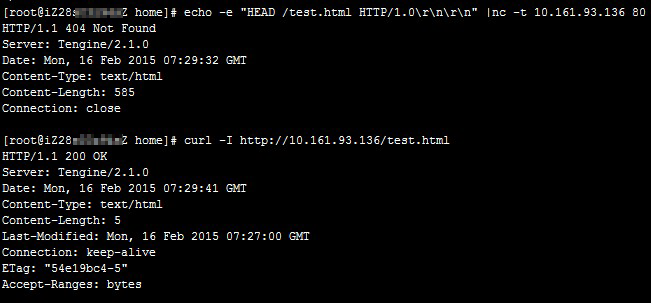
解決方案
修改主設定檔,注釋預設網站。
在健全狀態檢查配置中添加檢查網域名稱。
為什麼健全狀態檢查監控頻率與Web日誌記錄不一致?
負載平衡健全狀態檢查服務也是叢集方式的,這樣可以避免單點故障。負載平衡的代理分布到很多節點上,每個節點獨立進行健全狀態檢查,導致總的健全狀態檢查請求數增加,因此看到的健全狀態檢查日誌訪問頻率和控制台設定的頻率不一致,這是正常現象。
如何有效區分後端服務中的健全狀態檢查日誌與業務日誌?
問題現象
後端服務的日誌中,健全狀態檢查請求日誌與正常業務日誌混合記錄,導致記錄檔龐大且難以篩選。
問題原因
健全狀態檢查通過向後端服務發送HTTP、TCP或者UDP請求來測試後端服務可用性。這些請求會被後端服務記錄為普通日誌,與正常業務日誌混合。
解決方案
減少健全狀態檢查頻率:增大健全狀態檢查間隔時間、降低檢查頻率,來減少健全狀態檢查日誌產生。
調整健全狀態檢查路徑(適用HTTP健全狀態檢查):將健全狀態檢查路徑設定為非業務路徑(如
/health),並通過日誌中的路徑欄位區分健全狀態檢查日誌。關閉健全狀態檢查(不推薦):若確定不需要健全狀態檢查功能,可以關閉健全狀態檢查,避免產生健全狀態檢查日誌。
在健全狀態檢查日誌控制台看不到CLB健全狀態檢查失敗記錄
健全狀態檢查日誌每小時產生一次,預設只保留3天,若3天內CLB監聽的健全狀態檢查的狀態沒有發生變化則無健全狀態檢查日誌。可將健全狀態檢查日誌儲存到OSS來擷取更久的保留時間。