當Tair (Redis OSS-compatible)記憶體不足時,可能導致Key頻繁被逐出、回應時間上升、QPS(每秒訪問次數)不穩定等問題,進而影響業務運行。如果發現執行個體記憶體佔滿或收到記憶體警示,可參考本文判斷記憶體佔用是否長期過高、記憶體佔用是否突然上升、是否發生記憶體傾斜,並通過拆分大Key,設定到期策略,升級規格等方法解決問題。
記憶體使用量率高的現象分類
記憶體使用量率高,通常分為以下三種情況:
記憶體使用量率在較長一段時間內一直處於較高水位。通常,當記憶體使用量率超過95%時需要及時關注。
記憶體使用量率一直較低,但從某個時間點開始突然上升至較高水位,甚至達到100%。
執行個體整體的記憶體使用量率較低,但某個資料分區節點的記憶體使用量率接近100%。
請根據不同情況,分別採取措施降低記憶體使用量率。
記憶體使用量率長期處於高水位的解決辦法
查詢現有的Key是否符合業務預期,及時清理無用的Key。
通過緩衝分析功能,分析大Key分布和Key的TTL到期策略。具體操作,請參見離線全量Key分析。
分析Key是否有合理的TTL策略。
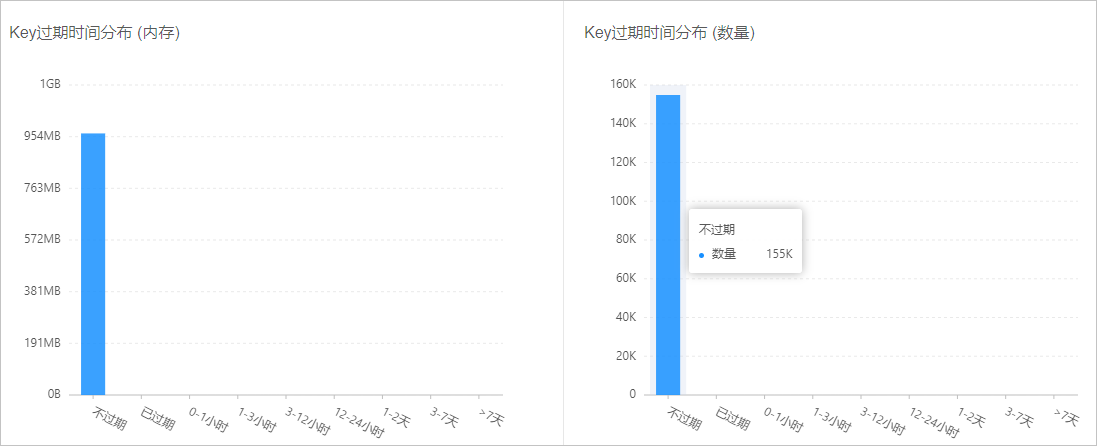
說明以下樣本中,所有的Key均未設定到期時間,建議根據業務需求來衡量,並在應用端設定合理的到期時間。
圖 4. Key的到期時間分布樣本
對大Key進行評估,然後在業務側對大Key進行拆分。
圖 5. 大Key分析樣本

根據業務需求,設定合理的資料逐出策略(即調整maxmemory-policy參數的值)。具體操作,請參見設定參數。
說明執行個體預設的資料逐出策略為volatile-lru,更多資訊,請參見資料逐出策略介紹。
根據業務需求,設定合理的到期Key主動刪除的執行頻率(即調整hz參數的值)。具體操作,請參見調整定期任務的執行頻率。
說明hz的取值建議在100以內,如果該值過大將對CPU的使用率產生較大影響。您也可以設定為自動調整(要求執行個體的大版本為相容Redis 5.0及以上版本),具體操作,請參見自動調整定期任務的執行頻率。
經過上述步驟最佳化後,記憶體使用量率依舊較高,可評估升級至更大記憶體的規格,以承載更多資料並改善效能。具體操作,請參見變更執行個體配置。
說明在正式升級執行個體的規格前,您可以先購買一個隨用隨付的執行個體,測試要升級到的目標規格是否能夠滿足業務的負載需求,測試完成後可將其釋放。關於如何釋放執行個體,請參見釋放隨用隨付執行個體。
記憶體使用量率突然上升的解決辦法
問題原因
記憶體使用量率突然升高的主要原因如下:
短時間內大量寫入新資料。
短時間內大量建立新串連。
突發訪問產生大量流量超過網路頻寬,導致輸入緩衝區和輸出緩衝區積壓。
用戶端處理速度跟不上執行個體的處理速度,導致輸出緩衝區積壓。
解決方案
請依次排查記憶體使用量率突然升高的原因,並參考對應的解決方案解決問題。
排查是否寫入大量新資料
排查方法:
查看效能監控的入流量與寫QPS。如果入流量與寫QPS的趨勢與記憶體使用量率的趨勢一致,說明大量的資料寫入導致記憶體使用量率突然升高。
解決方案:
通過設定Key的到期時間自動清理不再需要的Key,或手動刪除不再需要的Key。
升級執行個體規格,通過增加記憶體容量緩解記憶體使用量率升高的問題。詳情請參見變更執行個體配置。
如果您的執行個體為標準版,擴容記憶體規格後仍無法解決記憶體使用量率高的問題,可以考慮升級為叢集版,將資料分布到多個資料分區節點上,減輕單個資料分區節點的記憶體壓力。詳情請參見變更執行個體配置。
排查是否建立大量新串連
排查方法:
查看效能監控的串連數。如果串連數突然增長,且與記憶體使用量率的趨勢一致,說明大量建立串連導致記憶體使用量率突然升高。
解決方案:
排查是否存在串連泄漏。
設定連線逾時時間,自動關閉空閑串連。詳情請參見設定用戶端串連的空閑時間。
排查是否突發流量導致輸入和輸出緩衝區積壓
排查方法:
查看效能監控的出入口流量使用率是否達到100%。
執行
MEMORY STATS命令,查看clients.normal佔用的記憶體是否過多。說明clients.normal反映了所有普通用戶端串連的輸入和輸出緩衝區所佔用的記憶體總量。
解決方案:
排查業務流量突發原因。
增加執行個體的網路頻寬。詳情請參見手動增加執行個體頻寬和開啟頻寬Auto Scaling。
升級執行個體規格,以保證輸入輸出緩衝區的使用。詳情請參見變更執行個體配置。
排查是否因用戶端效能問題導致輸出緩衝區積壓
排查方法:
在執行個體中,執行MEMORY DOCTOR命令,查看big_client_buf的值。當big_client_buf=1時,代表至少有一個用戶端的輸出緩衝區佔用記憶體較大。
解決方案:
執行CLIENT LIST命令,查看哪個用戶端的輸出緩衝區記憶體佔用量(omem)較大。排查該用戶端應用是否存在效能問題。
資料分區節點記憶體使用量率高的解決方案
現象
如果執行個體為叢集架構,您可能從以下一種或幾種現象探索資料分區節點的記憶體使用量率高:
收到了CloudMonitor的記憶體使用量率警示。警示資訊中顯示某個資料節點的記憶體使用量率高,超過了閾值。
執行個體診斷報告顯示記憶體使用量率發生傾斜。
在效能監控頁面查看執行個體的記憶體使用量率和資料節點的記憶體使用量率,發現執行個體的記憶體使用量率不高,但某個資料分區節點的記憶體使用量率較高。
問題原因
如果執行個體的記憶體使用量率不高,但某個資料分區節點的記憶體使用量率較高,說明發生了記憶體傾斜。
解決方案
檢查是否存在大Key,並拆分大Key
尋找大Key
通過離線全量Key分析找出大Key。
更多找出大Key的方法,請參見大Key和熱Key。
拆分大Key
例如將含有數萬成員的一個HASH Key拆分為多個HASH Key,並確保每個Key的成員數量在合理範圍。在叢集架構執行個體中,拆分大Key能對資料分區間的記憶體平衡起到顯著作用。
檢查是否使用了Hash Tag
如果使用了Hash Tag,請根據業務實際情況,評估將一個Hash Tag拆分為多個Hash Tag,使資料更加均勻地分布在不同的資料分區節點上。
擴容執行個體規格
擴容執行個體規格,可以增加執行個體每個分區的記憶體,是改善記憶體傾斜的臨時解決方案,具體操作請參見變更執行個體配置。
變更配置時執行個體會進行資料扭曲預檢查,若您選擇的執行個體規格無法解決記憶體傾斜問題,執行個體會進行攔截與報錯,請您調大執行個體規格後重試。
在成功升級執行個體規格後,會改善記憶體傾斜問題,但可能也引起頻寬傾斜或CPU傾斜。
附錄1:Redis記憶體佔用介紹
Redis的記憶體佔用主要由以下三部分組成:
記憶體佔用 | 說明 |
鏈路記憶體(動態) | 主要包括Input Buff、Output Buff、JIT Overhead、Fake Lua Link、Lua執行緩衝等,例如可執行INFO命令,通過返回結果的Clients中查看用戶端緩衝資訊。 說明 Input buff與Output buff與每個用戶端的串連有關,通常較小。當執行用戶端Range類操作或大Key收發較慢時,Input buff與Output buff佔用的記憶體會增大,從而影響資料區,甚至會造成記憶體溢出OOM(Out Of Memory)。 |
資料記憶體 | 使用者資料區,即實際儲存的Value資訊,通常作為重點分析的對象。 |
管理記憶體(靜態) | 啟動時較小且相對恒定,該地區由管理資料的Hash記憶體開銷、Repl-buff與aof-buff的記憶體開銷(約32 MB~64 MB)等構成。 說明 當Key數量特別多時(例如幾億個),會佔用較大的記憶體。 |
大部分OOM情境是由於動態記憶體管理失效引起,例如限流時請求堆積導致動態記憶體快速上升、過於複雜或不合理的Lua指令碼也可能導致OOM。Tair(企業版)增強了對動態記憶體的控制,推薦選用。
附錄2:查看記憶體佔用情況的其他方法
使用MEMORY STATS命令查看記憶體佔用情況
使用MEMORY DOCTOR命令查看記憶體診斷建議
在Redis中,執行MEMORY DOCTOR命令擷取記憶體診斷建議。
圖 3. 診斷結果樣本
MEMORY DOCTOR會從以下維度為Redis執行個體的提供記憶體診斷建議,您可以根據診斷建議制定相應的最佳化策略:
int empty = 0; /* Instance is empty or almost empty. */
int big_peak = 0; /* Memory peak is much larger than used mem. */
int high_frag = 0; /* High fragmentation. */
int high_alloc_frag = 0;/* High allocator fragmentation. */
int high_proc_rss = 0; /* High process rss overhead. */
int high_alloc_rss = 0; /* High rss overhead. */
int big_slave_buf = 0; /* Slave buffers are too big. */
int big_client_buf = 0; /* Client buffers are too big. */
int many_scripts = 0; /* Script cache has too many scripts. */