RDS SQL Server提供了增量備份上雲的解決方案。您需要先將全量備份檔案上傳至阿里雲的Object Storage Service服務(OSS),並通過RDS控制台將全量備份資料恢複至指定的RDS SQL Server資料庫中。然後通過RDS控制台將差異備份或記錄備份檔案匯入該RDS SQL Server資料庫中,以實現增量備份上雲的效果。該方案能夠將業務停機時間控制在分鐘層級,從而有效縮短業務停機時間。
適用情境
RDS SQL Server增量資料上雲適用於以下情境:
基於備份檔案物理遷移至RDS SQL Server,而不是邏輯遷移。
說明物理遷移是指基於檔案的遷移,邏輯遷移是指將資料產生DML語句寫入RDS SQL Server。
物理遷移可做到資料庫遷移後和本地環境100%一致。邏輯遷移無法做到100%一致,例如索引片段率、統計資訊等。
對業務停止時間敏感,需要將業務停機時間控制在分鐘層級。
說明如果您對業務停止時間不是非常敏感(例如可以接受2小時的中斷),當資料庫小於100 GB時,建議您通過全量備份檔案上雲。
前提條件
RDS SQL Server執行個體需滿足如下條件:
執行個體版本為SQL Server 2012及以上版本,或SQL Server 2008 R2雲端硬碟。
執行個體中沒有與待上雲資料庫名稱相同的資料庫。
執行個體剩餘空間需大於待上雲的資料檔案。若空間不足,請提前升級執行個體空間。
本地SQL Server資料庫的復原模式需要設定為
FULL模式。說明在進行增量備份資料上雲時,需要進行交易記錄備份,而Simple模式下不允許進行交易記錄備份。
如果差異備份檔案很大,可能會導致增量備份上雲的時間變長。
如果通過RAM使用者登入,需滿足以下條件:
RAM帳號具備AliyunOSSFullAccess許可權和AliyunRDSFullAccess許可權。如何為RAM使用者授權,請參見通過RAM對OSS進行許可權管理和通過RAM對RDS進行許可權管理。
阿里雲帳號(主帳號)已授權RDS官方服務帳號可以訪問您OSS的許可權。
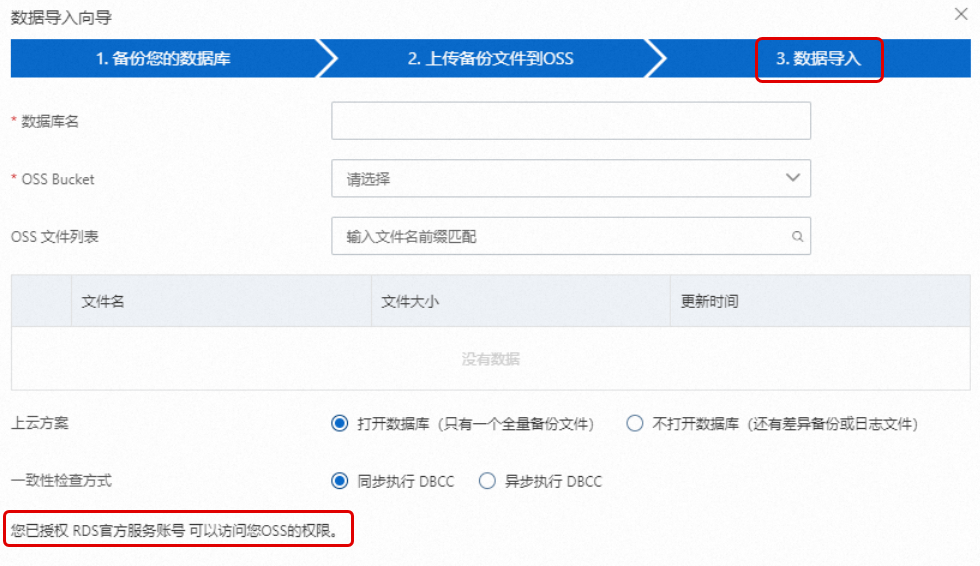
前往RDS執行個體詳情頁備份恢複頁面,單擊OSS備份資料恢複上雲按鈕。
在資料匯入嚮導頁面單擊兩次下一步,進入3. 資料匯入步驟。
若該頁面左下角顯示您已授權RDS官方服務帳號可以訪問您OSS的許可權,則表示已授權。否則表示還未授權,單擊該頁面的授權地址同意授權即可。
所在阿里雲帳號(主帳號)需手動建立權限原則,然後將許可權添加到RAM帳號中。
準備工作
在本機資料庫環境中執行DBCC CHECKDB語句,以確保資料庫中沒有任何的allocation errors和consistency errors。正常執行結果如下:
...
CHECKDB found 0 allocation errors and 0 consistency errors in database 'xxx'.
DBCC execution completed. If DBCC printed error messages, contact your system administrator.注意事項
遷移層級:本方案僅支援單個資料庫的遷移。如需遷移多個或所有資料庫,請參見SQL Server執行個體層級遷移上雲。
版本相容性:備份檔案所在本地SQL Server版本不支援遷移到低版本RDS SQL Server執行個體。
許可權管理:授予RDS服務帳號訪問OSS許可權後,系統會在存取控制RAM的角色管理中建立名為
AliyunRDSImportRole的角色,請勿修改或刪除該角色,否則會導致上雲任務失敗。若誤操作,需通過資料上雲嚮導重新授權。帳號管理:遷移完成後,原有資料庫帳號無法使用,需在RDS控制台重新建立帳號。
OSS檔案保留:在上雲任務完成前,請勿刪除OSS上的備份檔案,否則會導致任務失敗。
備份檔案要求:
檔案名稱限制:檔案名稱不得包含特殊字元(如
!@#$%^&*()_+-=),否則會導致上雲失敗。檔案尾碼:RDS支援的備份檔案為
.bak(全量備份)、.diff(差異備份)、.trn或.log(記錄備份),系統無法識別其他檔案類型。說明實際使用時,並非嚴格要求每種備份類型必須對應其格式尾碼,例如
.bak可代表全量備份、差異備份或交易記錄備份。對於通過RDS控制台下載的SQL Server記錄備份檔案(而非本文步驟一官方指令碼產生的
.bak備份檔案),該檔案預設格式為.zip.log,格式處理後可直接用於增量上雲。處理方法:先將檔案擴充改為
.zip以解壓,再將解壓得到的database_name.lbak重新命名為.bak格式,最後上傳此.bak檔案到OSS中作為增量記錄備份進行上雲。
操作流程舉例
上雲階段 | 步驟 | 說明 |
全量階段 | Step1. 00:00之前 | 完成準備工作,包括:
|
Step2. 00:01 | 開始對線下資料庫做FULL Backup,耗時近1小時。 | |
Step3. 02:00 | 上傳備份檔案到OSS Bucket,耗時近1小時。 | |
Step4. 03:00 | 開始在RDS控制台恢複FULL Backup檔案,耗時19小時。 | |
增量階段 | Step5. 22:00 | 開始資料庫增量LOG備份上雲,完成LOG備份並上傳至OSS,耗時約20分鐘。 |
Step6. 22:20 | 完成LOG Backup上雲,耗時約10分鐘。 | |
Step6. 22:30 |
| |
開啟資料庫 | Step8. 22:34 | 完成了最後一個LOG Backup檔案增量上雲操作,耗時4分鐘,開始將資料庫上線。 |
Step9. 22:35 | 資料庫上線完畢,如果選擇非同步執行DBCC操作,上線速度快,耗時1分鐘。 |
從整個的動作流程和時間軸來看,使用者需要停止應用的時間非常的短,僅在最後一個LOG Backup之前停止應用寫入即可。在本例中整個應用停止的時間控制在5分鐘內。
1. 備份本機資料庫
下載備份指令碼,用SSMS開啟備份指令碼。
修改如下參數。
配置項
說明
@backup_databases_list
需要備份的資料庫,多個資料庫以分號或者逗號分隔。
@backup_type
備份類型。參數值如下:
FULL:全量備份
DIFF:差異備份
LOG:記錄備份
@backup_folder
備份檔案所在的本地目錄。如不存在,會自動建立。
@is_run
是否執行備份。參數值如下:
1:執行備份。
0:只做檢查,不執行備份。
執行備份指令碼。
無論指定何種備份類型,本指令碼均預設產生
.bak格式檔案。
2. 上傳備份檔案到OSS
將備份檔案上傳至OSS前,您需先在OSS中建立儲存空間Bucket。
若OSS中已存在Bucket,請確保該Bucket滿足以下要求:
若OSS中沒有Bucket,需要先行建立。(請確保已開通OSS服務)
登入OSS管理主控台,單擊Bucket列表,然後單擊建立Bucket。
配置如下關鍵參數,其他參數可以保持預設。
重要建立的儲存空間主要用於本次資料上雲,只需配置關鍵參數即可,上雲完成後可以及時刪除以避免資料泄露及產生相關費用。
建立Bucket時請勿開啟資料加密。
參數
說明
取值樣本
Bucket 名稱
儲存空間名稱,全域唯一,設定後無法修改。
命名規則:
只能包括小寫字母、數字和短劃線(-)。
必須以小寫字母或者數字開頭和結尾。
長度必須在3~63字元之間。
migratetest
地區
Bucket所屬的地區,如果您通過ECS內網上傳資料至Bucket中,且通過內網將資料恢複至RDS中,則需要三者地區保持一致。
華東1(杭州)
儲存類型
選擇標準儲存。本文上雲操作不支援其他儲存類型的Bucket。
標準儲存
上傳備份檔案到OSS。
本機資料庫備份完成後,請將備份檔案上傳到與您的RDS執行個體同地區的OSS Bucket中,兩者處於同一地區時可通過內網互連(不會產生外網流量費用),且資料上傳速度更快。您可以採用如下方法之一:
下載ossbrowser。
以Windows x64作業系統為例,解壓下載的
oss-browser-win32-x64.zip壓縮包,雙擊運行oss-browser.exe應用程式。使用AK登入方式,配置參數AccessKeyId和AccessKeySecret,其他參數保持預設,然後單擊登入。
說明AccessKey用於身分識別驗證,確保資料安全,請妥善保管。

單擊目標Bucket,進入儲存空間。

單擊
 ,選擇需要上傳的備份檔案,然後單擊開啟,即可將本地檔案上傳至OSS中。
,選擇需要上傳的備份檔案,然後單擊開啟,即可將本地檔案上傳至OSS中。
說明如果備份檔案小於5 GB,建議您直接通過OSS控制台上傳備份檔案。
登入OSS管理主控台。
單擊Bucket列表,然後單擊目標Bucket名稱。

在檔案清單中,單擊上傳檔案。

您可以將備份檔案拖拽至待上傳檔案地區,也可以單擊掃描檔案,選擇需要上傳的備份檔案。

單擊頁面下方的上傳檔案,即可將本地備份檔案上傳至OSS中。
3. 建立資料上雲任務
訪問RDS執行個體列表,在上方選擇地區,然後單擊目標執行個體ID。
在左側功能表列中選擇備份恢複。
單擊頁面上方的OSS備份資料恢複上雲。
在資料匯入嚮導頁面,單擊兩次下一步,進入資料匯入步驟。
說明首次使用OSS備份資料恢複上雲功能,需授權RDS帳號訪問OSS,請單擊授權地址並同意授權,否則會因許可權問題導致OSS Bucket下拉式清單為空白。
設定如下參數,單擊確定。
請耐心等待上雲任務完成,您可以單擊重新整理查看資料上雲任務最新狀態。如上雲任務失敗,請根據任務描述提示排查錯誤,具體可參見本文常見錯誤。
配置項
說明
資料庫名
備份資料匯入目標RDS執行個體上的資料庫名,名稱需要符合SQL Server官方限制。
重要進行上雲操作前,請確保目標執行個體上不存在與備份檔案指定要還原的資料庫名稱相同的資料庫,也不存在相同名稱的未附加資料庫檔案。若都不存在,則可以使用備份組中同名資料庫檔案名稱還原資料庫。
如果目標執行個體上存在與備份檔案指定要還原的資料庫名稱相同的資料庫,或者存在同名的未附加資料庫檔案,上雲操作將失敗。
OSS Bucket
選擇備份檔案所在的OSS Bucket。
OSS檔案清單
單擊右側放大鏡按鈕,可以按照備份檔案名首碼模糊尋找,會展示檔案名稱、檔案大小和更新時間。請選擇需要上雲的備份檔案。
上雲方案
選擇不開啟資料庫。
開啟資料庫(只有一個全量備份檔案):全量上雲,適合僅有一個完全備份檔案上雲的情境。此時CreateMigrateTask中的
BackupMode = FULL並且IsOnlineDB = True。不開啟資料庫(還有差異備份或記錄檔):增量上雲,適合有完全備份檔案加上記錄備份(或者差異備份檔案)上雲的情境。此時CreateMigrateTask 中的
BackupMode = UPDF並且IsOnlineDB = False。
4. 匯入差異或記錄備份檔案
SQL Server本機資料庫全量備份上雲完成後,接下來需要匯入差異備份或者記錄備份檔案。
訪問RDS執行個體列表,在上方選擇地區,然後單擊目標執行個體ID。
在左側功能表列中選擇備份恢複,單擊備份資料上雲記錄頁簽。
在工作清單中找到待匯入備份檔案的記錄,在右側單擊上傳增量檔案,選擇增量檔案後單擊確認。
說明如果您有多個記錄備份檔案,請使用同樣的方法逐個產生上雲任務。
請在上傳增量檔案時,盡量保證最後一個備份檔案的大小不超過500MB,以此來縮短增量上雲的時間開銷。
在最後一個記錄備份檔案產生前,請停止本機資料庫所有的寫入操作,以保證線下資料庫和RDS SQL Server上的資料庫資料一致。
5. 開啟資料庫
匯入檔案後RDS SQL Server中的資料庫會處於In Recovery或者Restoring狀態。高可用系列會處於In Recovery狀態,單機版會處於Restoring狀態,此時的資料庫還無法進行讀寫操作,需要開啟資料庫。
訪問RDS執行個體列表,在上方選擇地區,然後單擊目標執行個體ID。
在左側功能表列中選擇備份恢複,單擊備份資料上雲記錄頁簽。
在工作清單中找到待匯入備份檔案的記錄,在右側單擊開啟資料庫。
選擇資料庫的開啟檔案,單擊確定。
說明開啟資料庫一致性檢查有以下兩種方式:
非同步執行DBCC:在開啟資料庫的時候系統不做DBCC CheckDB,會在開啟資料庫任務結束以後,非同步執行DBCC CheckDB操作,以此來節約開啟資料庫操作的時間開銷(資料庫比較大,DBCC CheckDB非常耗時),減少您的業務停機時間。如果您對業務停機時間要求非常敏感,且不關心DBCC CheckDB結果,建議使用非同步執行DBCC。此時CreateMigrateTask 中的
CheckDBMode = AsyncExecuteDBCheck。同步執行DBCC:相對於非同步執行DBCC,有的使用者非常關心DBCC CheckDB的結果,以此來找出使用者線下資料庫資料一致性錯誤。此時,建議您選擇同步執行DBCC,影響是會拉長開啟資料庫的時間。此時CreateMigrateTask 中的
CheckDBMode = SyncExecuteDBCheck。
6. 查看上雲任務備份檔案詳情
訪問RDS執行個體左側導覽列備份恢複頁面,在備份資料上雲記錄頁簽內查看備份上雲記錄,單擊對應任務最右側的查看檔案詳情,將展示對應任務所有關聯的備份檔案詳情。
常見錯誤
全量備份資料上雲中常見錯誤,請參見全量備份資料上雲-常見錯誤。
您在增量上雲過程中,可能會遇到如下的錯誤:
資料庫開啟失敗
錯誤資訊:Failed to open database xxx.
錯誤原因:線下SQL Server資料庫啟用了一些進階功能,如果使用者選擇的RDS SQL Server版本不支援這些進階功能,會導致資料庫開啟失敗。例如本地SQL Server資料庫是企業版,啟用了資料壓縮(Data Compression)或者分區(Partition),OSS上雲到RDS SQL Server Web版,就會報告這個錯誤。
解決方案:
在本地SQL Server執行個體上禁用進階功能,重新備份後,再使用OSS上雲功能。
購買與線下SQL Server執行個體相同版本的RDS SQL Server。購買方法,請參見快速建立並使用RDS SQL Server執行個體。
說明更多詳情,請參見RDS SQL Server各版本的功能差異。
Database Backup鏈中LSN無法對接
錯誤資訊:The log in this backup set begins at LSN XXX, which is too recent to apply to the database.RESTORE LOG is terminating abnormally.
錯誤原因:在SQL Server資料庫中,差異備份或者記錄備份能夠成功還原的前提是,差異或者記錄備份的LSN必須與上一次還原的備份檔案LSN能夠對接上,否則就會報告這個錯誤。
解決方案:請選擇對應的LSN備份檔案進行增量備份檔案上雲,您可以按照備份檔案備份操作時間先後順序進行增量上雲操作。
非同步DBCC Checkdb失敗
錯誤資訊:asynchronously DBCC checkdb failed: CHECKDB found 0 allocation errors and 2 consistency errors in table 'XXX' (object ID XXX).
錯誤原因:備份檔案還原到RDS SQL Server上,上雲任務系統會非同步做DBCC CheckDB檢查,如果檢查不通過,說明本機資料庫中已經有錯誤發生。
解決方案:
在RDS SQL Server上執行:
DBCC CHECKDB (DBName,REPAIR_ALLOW_DATA_LOSS)重要使用該命令修複錯誤的過程,可能會導致資料丟失。
在本地使用如下命令修複錯誤後重新進行增量上雲。
DBCC CHECKDB (DBName,REPAIR_ALLOW_DATA_LOSS)
完全備份檔案類型
錯誤資訊:Backup set (xxx) is a Database FULL backup, we only accept transaction log or differential backup.
錯誤原因:在增量上雲RDS SQL Server過程中,全量備份檔案還原完畢後,就只能再接受記錄備份檔案或者是差異備份檔案。如果使用者再次選擇了全量備份檔案,就會報告這個錯誤。
解決方案:選擇記錄備份檔案或者差異備份檔案。
資料庫個數超出最大限制數
錯誤資訊:The database (xxx) migration failed due to databases count limitation.
錯誤原因:當資料庫達到數量限制以後再做上雲操作,任務會失敗報告這個錯誤。
解決方案:遷移上雲資料庫到其他的RDS SQL Server,或者刪除不必要的資料庫。
RAM帳號操作許可權不足
Q1:執行建立資料上雲任務步驟5使,各配置項參數均已填寫完整,但確定按鈕為灰色無法單擊?
A1:無法單擊的原因可能是您為RAM使用者,您的帳號許可權不足。請參見本文前提條件,確保相應許可權已授予。
Q2:使用RAM子帳號進行
AliyunRDSImportRole授權時提示沒有許可權如何解決?A2:使用阿里雲主帳號為RAM子帳號臨時增加
AliyunRAMFullAccess許可權解決。如何為RAM使用者授權,請參見通過RAM對RDS進行許可權管理。
相關API
API | 描述 |
將OSS上的備份檔案還原到RDS SQL Server執行個體,建立資料上雲任務。 | |
開啟RDS SQL Server備份資料上雲任務的資料庫。 | |
查詢RDS SQL Server執行個體備份資料上雲工作清單。 | |
查詢RDS SQL Server備份資料上雲任務的檔案詳情。 |