在資料庫維護或故障處理時查看效能指標是必不可少的步驟。RDS MySQL的標準監控提供了豐富的效能監控指標和強大的診斷能力,能夠及時發現異常並提供治理方案。
功能簡介
RDS MySQL升級了標準監控,融合了效能趨勢,提供了更豐富的功能。
自訂視圖:標準監控提供更加豐富的效能監控指標,支援自訂視圖,自主選擇指標進行監控。
說明監控指標對應的績效參數請參見績效參數表。
常見問題的診斷視圖:提供了記憶體OOM診斷、唯讀執行個體延遲診斷、空間滿問題診斷、CPU抖動診斷和大事務識別診斷等視圖,您可以選擇對應的診斷視圖,快速定位問題。
自動診斷:標準監控能及時探索資料庫執行個體的事件,進行自動診斷,輸出根因分析和建議。
手動診斷:支援自主選擇時段進行手動診斷。
查看標準監控
訪問RDS執行個體列表,在上方選擇地區,然後單擊目標執行個體ID。
在左側導覽列單擊監控與報警。
在標準監控頁面,選擇標準視圖或自訂視圖。
標準視圖
在標準視圖頁簽,選取查詢時間,查看選定時間範圍內的效能事件和效能指標。
說明在選擇時間範圍時,開始時間與結束時間之間的間隔不得超過7天,最多可查看30天內的資料。
查看效能事件
在事件統計地區,查看選定時間範圍內各類事件的統計資訊。單擊查看詳情,可以跳轉到查看效能事件頁面,查看執行個體例外狀況事件和最佳化事件的詳細資料,包括計劃執行、正在執行和已執行完成的事件。
查看效能指標
查看監控指標
在預設的傳統檢視中,您可以查看選定時間段的監控指標。
單擊更多指標,選擇需要查看效能趨勢的指標。
單擊每個監控項後的
 查看各個監控項包含的指標。
查看各個監控項包含的指標。
單擊某個監控指標趨勢圖中的詳情,放大並修改時間查看趨勢。
單擊添加趨勢對比,查看不同時間段內相同指標的效能趨勢對比。

查看事件分析
在預設傳統檢視中,選擇需要展示的事件層級,系統會在MySQL CPU/記憶體利用率和會話串連的趨勢圖中展示這些事件。
單擊趨勢圖中的事件,在事件詳情中查看診斷結果。

診斷分析指標
在任意指標趨勢圖中,使用滑鼠拖拽的方式選定一段時間,可以對選擇時段進行診斷。
查看常見問題診斷視圖
您可以通過這些視圖快速定位問題原因,當前提供的診斷視圖包括:記憶體OOM診斷、唯讀執行個體延遲診斷、空間滿問題診斷、CPU抖動診斷和大事務識別診斷。詳情請參見診斷視圖使用指南。
自訂視圖
在自訂視圖頁簽,單擊新增監控大盤,通過自訂監控大盤,查看需要進行監控的指標趨勢。監控指標對應的績效參數請參見績效參數表。
單擊添加節點和指標監控,為監控大盤選擇需要監控的節點和指標。
您可以選擇不同的指標展示方式,合并展示和分開展示。
合并展示:多個指標在同一個趨勢圖表展示。
分開展示:單獨展示每個指標的趨勢圖。
通過圖表布局,設定每行顯示監控指標趨勢圖的數量。
單擊某個監控指標趨勢圖中的詳情,放大並修改時間查看趨勢。
單擊標準監控頁面右上方的返回舊版按鈕,可以返回舊版監控。
診斷視圖使用指南
記憶體OOM診斷
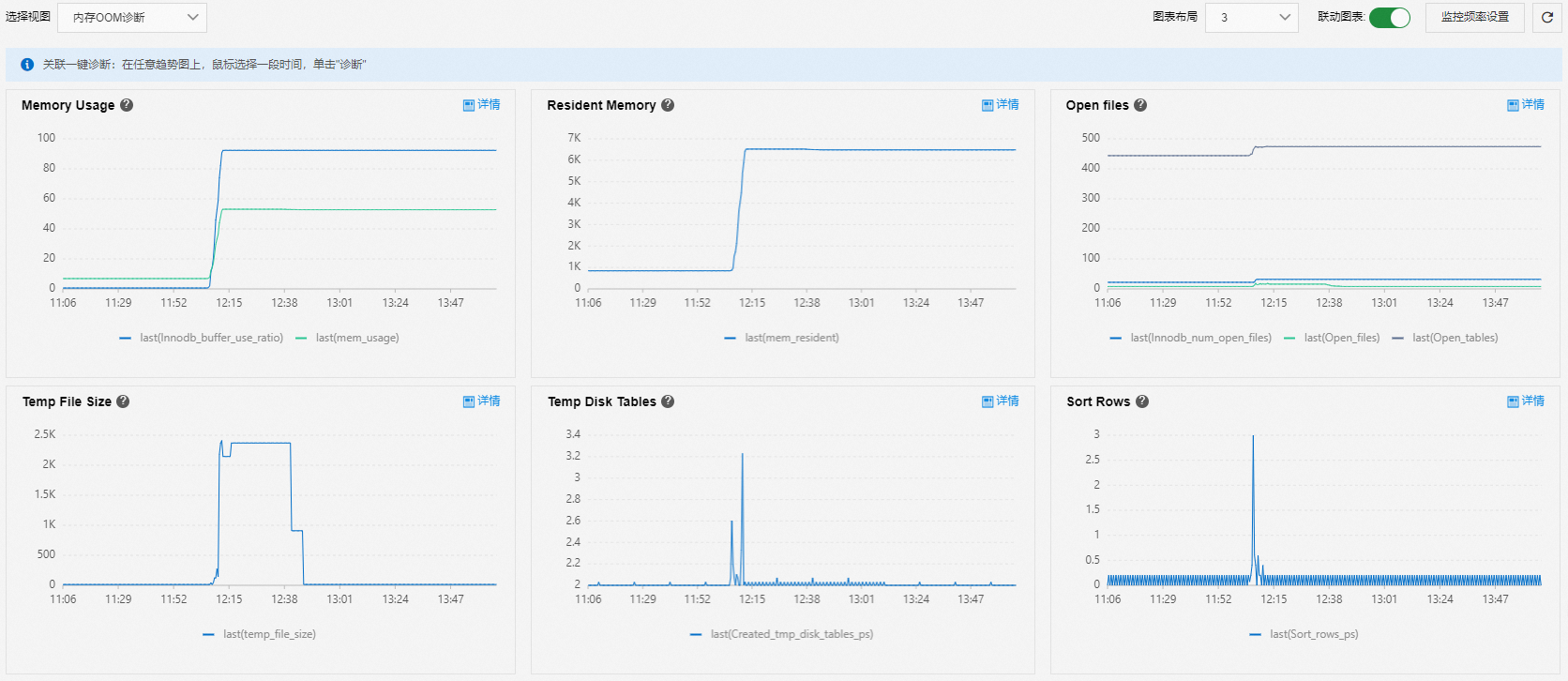
使用記憶體OOM診斷視圖分析記憶體OOM(Out of Memory)問題。
Memory Usage:
InnoDB Buffer Pool使用率不變,記憶體使用量率長時間(例如超過7天)緩慢持續上漲時,可能是記憶體流失導致。
記憶體突然上漲,InnoDB Buffer Pool使用率不變時,可能是突增業務導致。
記憶體和InnoDB Buffer Pool同步增長時,InnoDB Buffer Pool被逐步填充,屬於正常情況。
Resident Memory:查看記憶體大小。
Open files、Temp File Size、Temp Disk Tables和Sort Rows:查看消耗記憶體的常見指標。
記憶體增長與業務指標相關,記憶體突增的SQL通常因OOM無法追溯,因此建議:
檢查業務日誌,判斷記憶體突增的原因。
升級記憶體規格,並且開啟SQL洞察和審計,在記憶體突增時查看SQL的執行時間來判斷記憶體突增的原因。
唯讀執行個體延遲診斷
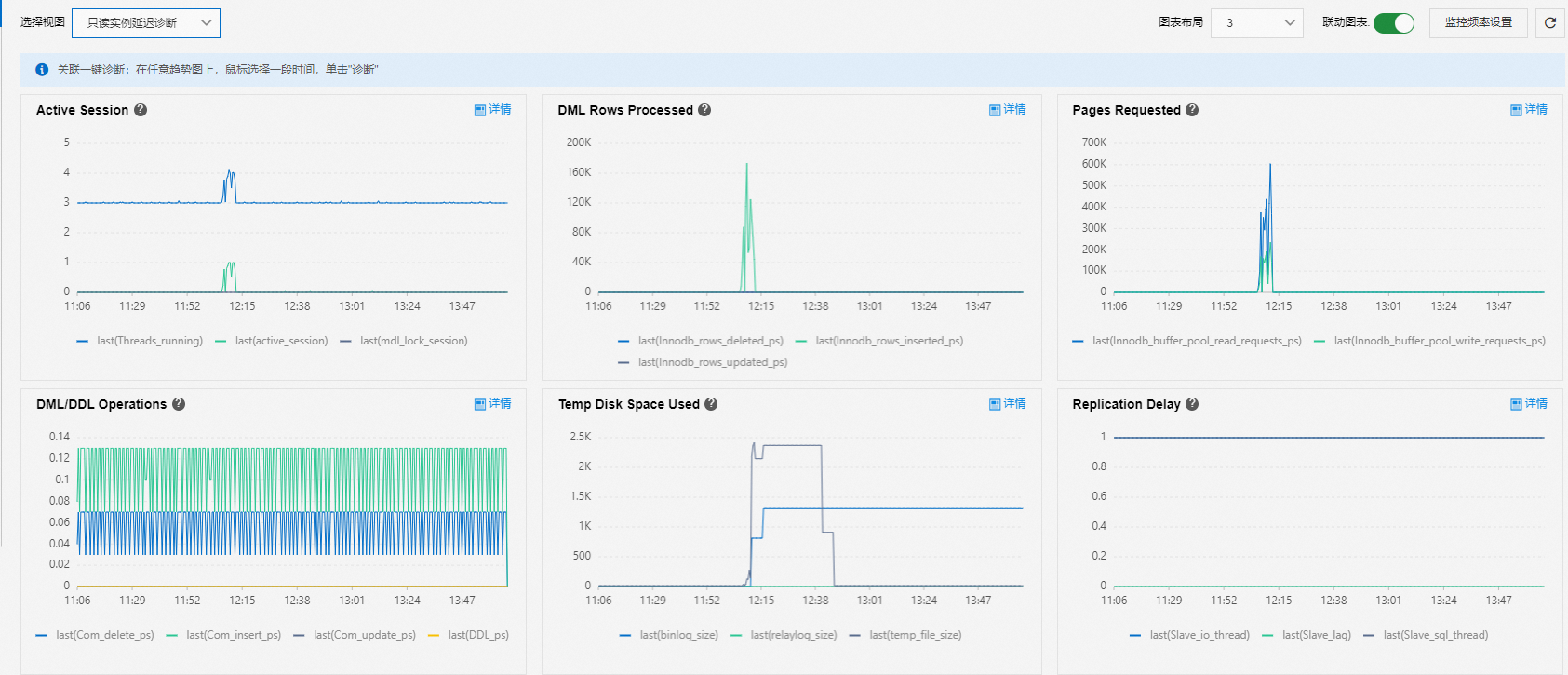
使用唯讀執行個體延遲診斷視圖分析唯讀執行個體延遲問題。
Active Session:查看是否有MDL鎖阻塞的情況。
通常大量資料的查詢會讓DDL無法擷取MDL鎖,此時DDL會阻塞其他會話,導致串連數堆積。
DML Rows Processed、Pages Requested、DML/DDL Operations和Temp Disk Space Used:查看常見的業務指標。
Replication Delay:查看延遲指標。
空間滿問題診斷

使用空間滿問題診斷視圖分析空間佔滿問題。
查看執行個體佔用儲存空間的檔案類型和變化趨勢,常見佔用儲存的指標如下:
資料檔案(user_data_size):可以通過空間分析查看各資料庫、表的空間佔用情況,根據實際情況擴容或者刪除不需要的資料。請參見資料檔案導致執行個體空間滿的解決辦法處理資料檔案。
臨時檔案(temp_file_size):MySQL執行個體可能會由於查詢語句的排序、分組、關聯表產生的暫存資料表檔案,或者大事務提交前產生的binlog cache檔案佔用空間。請參見臨時檔案導致執行個體空間滿的解決辦法處理臨時檔案。
Binlog日誌(binlog_size):MySQL執行個體可能會由於大事務快速產生Binlog檔案佔用空間。請參見MySQL Binlog檔案導致執行個體空間滿的解決辦法處理Binlog日誌。
說明如果業務側訂閱了資料庫的Binlog,也可能導致Binlog未及時清理而佔用空間。
Undo日誌(undo_log_size):一般情況下,長時間執行的查詢導致Undo日誌無法被清理。請檢查是否有長時間執行且未結束的查詢語句。
說明MySQL 5.6及以前的版本,Undo日誌沒有獨立的資料表空間。
慢日誌(slowlog_size):慢日誌佔用空間過高時,建議在業務低峰期使用
truncate命令進行清理。說明MySQL 5.7的20210630版本和MySQL 8.0的20210930版本開始支援
truncate命令。常規日誌(general_log_size):執行個體的錯誤記錄檔、Performance Agent日誌、recover日誌大小之和 。這部分日誌總量一般都會在1 GB以內,基本保持穩定,如果大小明顯超過這個範圍,請提交工單聯絡產品解決。該指標是MySQL核心定時輸出的核心指標資料,並非是MySQL的general_log的日誌大小。
CPU抖動診斷

使用CPU抖動診斷視圖分析CPU抖動問題,相關指標有:
業務指標:
Page Request:通常情況下,Buffer Pool請求數的趨勢和CPU使用率同頻波動。
Rows Processed:查看CPU使用率和系統處理行數的關係,判斷CPU使用率變化時是否存在突增的行數。
Queries:查看CPU使用率變化時,主要執行的SQL語句類型。
串連數:
Thread Running:高並發會導致CPU使用率變高;MDL堆積或者行鎖會導致串連數堆積,進而影響CPU使用率。
CPU抖動的常見原因:
業務指標(Page Request/Rows Processed)發生變化,導致CPU使用率同步變化,此時可以選中CPU使用率變化的時間段,執行診斷擷取詳細的根因分析結果。
活躍串連數增加引起CPU消耗,此時請從業務側進行排查。
大事務識別診斷
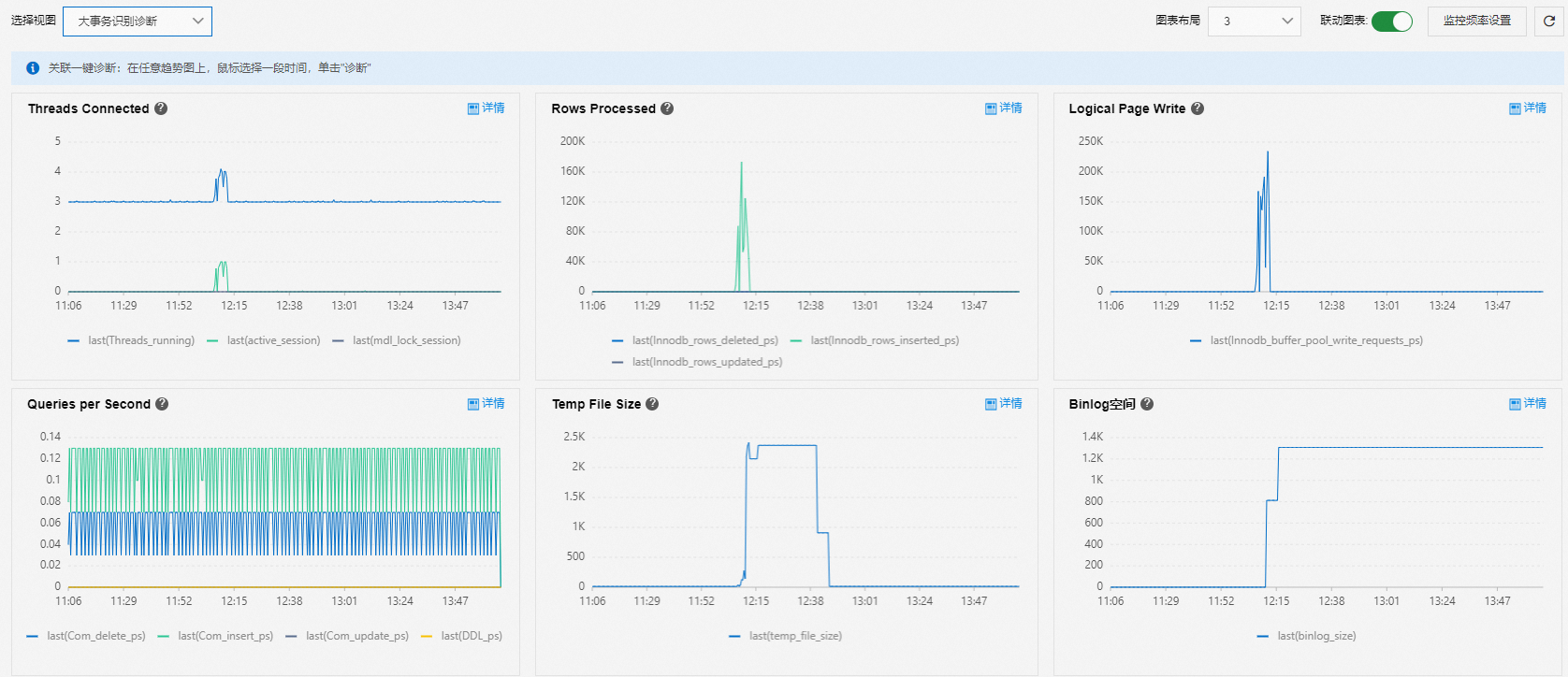
使用大事務識別診斷視圖分析大事務問題。
Threads Connected、Temp File Size和Binlog空間:查看判斷是否為大事務的三個核心指標。當出現如下情況時,可判斷為資料庫存在大事務:
活躍會話堆積。
臨時空間先增加然後減少。
臨時空間減少後Binlog空間同步增加。
Rows Processed、Logical Page Write和Queries per Second:判斷大事務是什麼類型。
例如查詢很少,但刪除的行數很多時,表明存在刪除資料的大事務。
大事務會引起Binlog寫入阻塞:
當執行個體有大事務時,暫存資料表空間(binlog cache)先逐步增加,然後保持平穩。
當暫存資料表空間平穩時,Binlog空間增加;由於Binlog寫入是全域串列,其他事務會被阻塞,導致串連數開始堆積。
當執行個體為高可用系列時,主執行個體和備執行個體的HA組件探測語句也被阻塞,執行個體會直接發生主備切換。
建議您將大事務拆分為小事務分別執行。例如在delete語句中增加where條件子句,限制每次刪除的資料量,將一次刪除操作拆分為多次資料量較小的刪除操作進行。
相關文檔
相關API
API | 描述 |
查詢RDS執行個體效能資料 |
附錄:舊版監控
舊版監控指標概述
查看舊版監控
訪問RDS執行個體列表,在上方選擇地區,然後單擊目標執行個體ID。
在左側導覽列單擊監控與報警。
選擇標準監控頁簽,單擊返回舊版。

在舊版監控頁面選擇資源監控、引擎監控或部署監控,並選取查詢時間(如果是叢集系列執行個體,還可以選擇執行個體或節點ID),即可查看相應的監控資料。僅支援查詢過去30天內的監控資料。