查詢最佳化工具負責最佳化邏輯計劃從而輸出物理計劃,其主要階段包含查詢改寫和計劃枚舉。本文將介紹查詢最佳化工具的基本原理,以及什麼是關係代數運算子、查詢改寫(RBO階段)和查詢計劃枚舉(CBO階段)。
PolarDB-X接收到一條SQL後的執行過程大致如下:
文法解析器(Parser)將SQL文本解析成抽象文法樹(AST)。
文法樹被轉化成基於關係代數的邏輯計劃。
查詢最佳化工具(Optimizer)對邏輯計划進行最佳化得到物理計劃。
查詢執行器(Executor)執行該計劃,得到查詢結果並返回給用戶端。
關係代數運算子

一條SQL查詢在資料庫系統中通常被表示為一棵關係代數運算子組成的樹,主要包含以下運算子:
Project:用於描述SQL中的SELECT列,包括Function Compute。
Filter:用於描述SQL中的WHERE條件。
JOIN:用於描述SQL中的JOIN,其對應的物理運算元有HashJoin、 BKAJoin、Nested-Loop Join、SortMergeJoin等。
Agg:用於描述SQL中的Group By及彙總函式,其對應的物理運算元有HashAgg、SortAgg。
Sort:用於描述SQL中的Order By及Limit,其對應的物理運算元有TopN、MemSort。
例如,對於如下查詢SQL:
SELECT l_orderkey, sum(l_extendedprice *(1 - l_discount)) AS revenue
FROM CUSTOMER, ORDERS, LINEITEM
WHERE c_mktsegment = 'AUTOMOBILE'
and c_custkey = o_custkey
and l_orderkey = o_orderkey
and o_orderdate < '1995-03-13'
and l_shipdate > '1995-03-13'
GROUP BY l_orderkey;通過EXPLAIN命令看到該SQL的執行計畫如下:
HashAgg(group="l_orderkey", revenue="SUM(*)")
HashJoin(condition="o_custkey = c_custkey", type="inner")
Gather(concurrent=true)
LogicalView(tables="ORDERS_[0-7],LINEITEM_[0-7]", shardCount=8, sql="SELECT `ORDERS`.`o_custkey`, `LINEITEM`.`l_orderkey`, (`LINEITEM`.`l_extendedprice` * (? - `LINEITEM`.`l_discount`)) AS `x` FROM `ORDERS` AS `ORDERS` INNER JOIN `LINEITEM` AS `LINEITEM` ON (((`ORDERS`.`o_orderkey` = `LINEITEM`.`l_orderkey`) AND (`ORDERS`.`o_orderdate` < ?)) AND (`LINEITEM`.`l_shipdate` > ?))")
Gather(concurrent=true)
LogicalView(tables="CUSTOMER_[0-7]", shardCount=8, sql="SELECT `c_custkey` FROM `CUSTOMER` AS `CUSTOMER` WHERE (`c_mktsegment` = ?)")用樹狀圖表示如下:
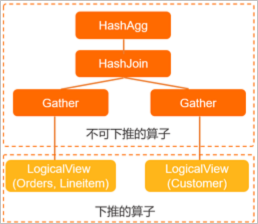
左邊的LogicalView實際包含了ORDERS和LINEITEM兩張表的JOIN。EXPLAIN結果中LogicalView的SQL屬性也體現了這一點。
查詢改寫(RBO)
查詢改寫(SQL Rewrite)階段輸入輸出都為邏輯執行計畫。這一步主要應用一些啟發學習法規則,是基於規則的最佳化器(Rule-Based Optimizer,簡稱RBO),所以也常被稱為RBO階段。
查詢改寫主要完成以下功能:
子查詢去關聯化(Subquery Unnesting)
子查詢去關聯化是將含有關聯項的子查詢(關聯子查詢)表示為SemiJoin或類似的物理運算元,便於後續的各種最佳化。例如下推到儲存層MySQL或在PolarDB-X計算層選擇某種運算元執行。在如下樣本中IN子查詢轉化為SemiJoin物理運算元,並最終轉化成SemiHashJoin物理運算元由PolarDB-X執行:
explain select id from t1 where id in (select id from t2 where t2.name = 'hello'); SemiHashJoin(condition="id = id", type="semi") Gather(concurrent=true) LogicalView(tables="t1", shardCount=2, sql="SELECT `id` FROM `t1` AS `t1`") Gather(concurrent=true) LogicalView(tables="t2_[0-3]", shardCount=4, sql="SELECT `id` FROM `t2` AS `t2` WHERE (`name` = ?)")物理運算元下推
物理運算元下推是非常關鍵的一步,PolarDB-X內建了如下物理運算元的下推最佳化規則:
最佳化規則
描述
謂詞下推或列裁剪
將Filter及Project物理運算元下推至儲存層MySQL執行,過濾掉不需要的行和列。
JOINClustering
將JOIN按照拆分方式及拆分鍵的等值條件進行重排和聚簇,方便下一步的JOIN下推。
JOIN下推
對於合格JOIN,將其下推至儲存層MySQL執行。
Agg下推
將彙總(Agg)拆分為FinalAgg和LocalAgg兩個階段,並將LocalAgg下推至儲存層MySQL。
Sort下推
將排序(Sort)拆分為MergeSort和LocalSort兩個階段,並將LocalSort下推至儲存層MySQL。
更多關於查詢下推的資訊,請參見查詢改寫與下推。
查詢計劃枚舉(CBO)
查詢改寫階段輸出的邏輯執行計畫會被輸入到查詢計劃枚舉(Plan Enumerator)中,並輸出一個最終的物理執行計畫。查詢計劃枚舉在多個可行的查詢計劃中,根據預先定義的代價模型,選擇出代價最低的一個。與查詢改寫階段不同,在查詢計劃枚舉中,規則可能產生更好的執行計畫,也可能產生更差的執行計畫,可以根據物理運算元經過規則最佳化後的前後代價對比選出較優的那個,因此這也被稱為基於代價的最佳化(Cost-based Optimizer,簡稱CBO)。
其核心組件包括以下幾部分:
統計資訊(Statistics)。
基數估計(Cardinality Estimation)。
轉化規則(Transform Rules)。
代價模型(Cost Model)。
計劃空間搜尋引擎(Plan Space Search Engine)。
邏輯上,CBO的過程包括以下幾個步驟:
搜尋引擎利用轉化規則,對輸入的邏輯執行計畫進行變換,構造出物理執行計畫的搜尋空間。
利用代價模型對搜尋空間中的每一個執行計畫進行代價估計,選出代價最低的物理執行計畫。
代價估計的過程離不開基數估計,它利用各個表、列的統計資訊,估算出各物理運算元的輸入行數、選擇率等資訊,提供給物理運算元的代價模型,從而估算出查詢計劃的代價。