您可以使用Semi-Join半串連最佳化子查詢,減少查詢次數,提高查詢效能。本文將介紹Semi-Join半串連的基本資料和操作方法。
前提條件
PolarDB叢集版本需為PolarDB MySQL版8.0版本且修訂版本滿足以下條件:
8.0.1.0.5 或以上。
8.0.2.2.7 或以上。
如何查看叢集版本,請參見查詢版本號碼。
背景資訊
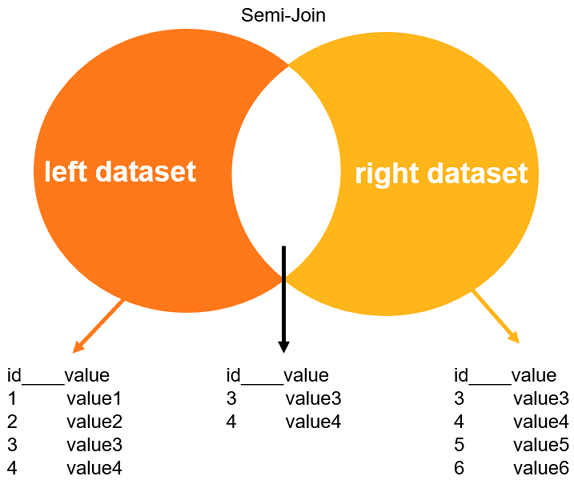
MySQL 5.6.5引入了Semi-Join半串連,當外表在內表中找到匹配的記錄之後,Semi-Join會返回外表中的記錄。但即使在內表中找到多條匹配的記錄,外表也只會返回已經存在於外表中的記錄。而對於子查詢,外表的每個合格元組都要執行一輪子查詢,效率比較低下。此時使用半串連操作最佳化子查詢,會減少查詢次數,提高查詢效能。其主要思路是將子查詢上拉到父查詢中,這樣內表和外表是並列關係,外表的每個合格元組,只需要在內表中找合格元組即可,所以效率會大大提高。
策略
Semi-Join主要使用了如下策略:
DuplicateWeedout Strategy
該策略建立由
row id組成唯一ID的暫存資料表,再通過該唯一ID達到去重目的。
Materialization Strategy
該策略將
nested tables物化到暫存資料表中,再通過尋找物化表或者遍曆物化表尋找外表的方法達到去重目的。
Firstmatch Strategy
該策略採用順序尋找表的方式,找到第一個匹配的記錄後立即跳轉到最後一個外表,並對外表的下一條記錄執行JOIN操作,從而達到去重的目的。

LooseScan Strategy
該策略對內表基於索引(Index)進行分組,分組後與外表執行JOIN(進行Condition的匹配)操作,如果存在匹配的記錄,則提取外表的記錄,內表選取下一個分組繼續進行計算,從而達到去重目的。

文法
Semi-Join通常使用IN或EXISTS作為串連條件。
IN
SELECT * FROM Employee WHERE DeptName IN ( SELECT DeptName FROM Dept )EXISTS
SELECT * FROM Employee WHERE EXISTS ( SELECT 1 FROM Dept WHERE Employee.DeptName = Dept.DeptName )
並行Semi-Join效能提升
對於選擇Semi-Join策略的查詢,PolarDB對Semi-Join所有策略實現了並行加速。通過拆分Semi-Join的任務,多執行緒模式並行運行任務集,強化去重能力,使查詢效能得到了顯著的提升。在PolarDB 8.0.2.2.7後支援對物化策略(Semi-Join Materialization)的多階段並行查詢,進一步提升了Semi-Join的查詢效能,以Q20為例進行說明。
SELECT
s_name,
s_address
FROM
supplier,
nation
WHERE
s_suppkey IN
(
SELECT
ps_suppkey
FROM
partsupp
WHERE
ps_partkey IN
(
SELECT
p_partkey
FROM
part
WHERE
p_name LIKE '[COLOR]%'
)
AND ps_availqty > (
SELECT
0.5 * SUM(l_quantity)
FROM
lineitem
WHERE
l_partkey = ps_partkey
AND l_suppkey = ps_suppkey
AND l_shipdate >= date('[DATE]')
AND l_shipdate < date('[DATE]') + interval '1' year )
)
AND s_nationkey = n_nationkey
AND n_name = '[NATION]'
ORDER BY
s_name;本文例子中,子查詢和外層查詢都以並行度(DOP)為32並存執行,子查詢首先並行產生物化表,之後外層查詢也並行的進行後續處理,充分發揮CPU的處理能力,將查詢並行能力最大化。下文展示了在標準TPC-H中,SCALE為100 GB的資料量熱資料情境下,開啟並行後多階段的平行處理能力。
本文的TPC-H的實現基於TPC-H的基準測試,並不能與發行的TPC-H基準測試結果相比較,本文中的測試並不符合TPC-H基準測試的所有要求。
並行的執行計畫如下:
-> Sort: <temporary>.s_name (cost=5014616.15 rows=100942)
-> Stream results
-> Nested loop inner join (cost=127689.96 rows=100942)
-> Gather (slice: 2; workers: 64; nodes: 2) (cost=6187.68 rows=100928)
-> Nested loop inner join (cost=1052.43 rows=1577)
-> Filter: (nation.N_NAME = 'KENYA') (cost=2.29 rows=3)
-> Table scan on nation (cost=2.29 rows=25)
-> Parallel index lookup on supplier using SUPPLIER_FK1 (S_NATIONKEY=nation.N_NATIONKEY), with index condition: (supplier.S_SUPPKEY is not null), with parallel partitions: 863 (cost=381.79 rows=631)
-> Single-row index lookup on <subquery2> using <auto_distinct_key> (ps_suppkey=supplier.S_SUPPKEY)
-> Materialize with deduplication
-> Gather (slice: 1; workers: 64; nodes: 2) (cost=487376.70 rows=8142336)
-> Nested loop inner join (cost=73888.70 rows=127224)
-> Filter: (part.P_NAME like 'lime%') (cost=31271.54 rows=33159)
-> Parallel table scan on part, with parallel partitions: 6244 (cost=31271.54 rows=298459)
-> Filter: (partsupp.PS_AVAILQTY > (select #4)) (cost=0.94 rows=4)
-> Index lookup on partsupp using PRIMARY (PS_PARTKEY=part.P_PARTKEY) (cost=0.94 rows=4)
-> Select #4 (subquery in condition; dependent)
-> Aggregate: sum(lineitem.L_QUANTITY)
-> Filter: ((lineitem.L_SHIPDATE >= DATE'1994-01-01') and (lineitem.L_SHIPDATE < <cache>((DATE'1994-01-01' + interval '1' year)))) (cost=4.05 rows=1)
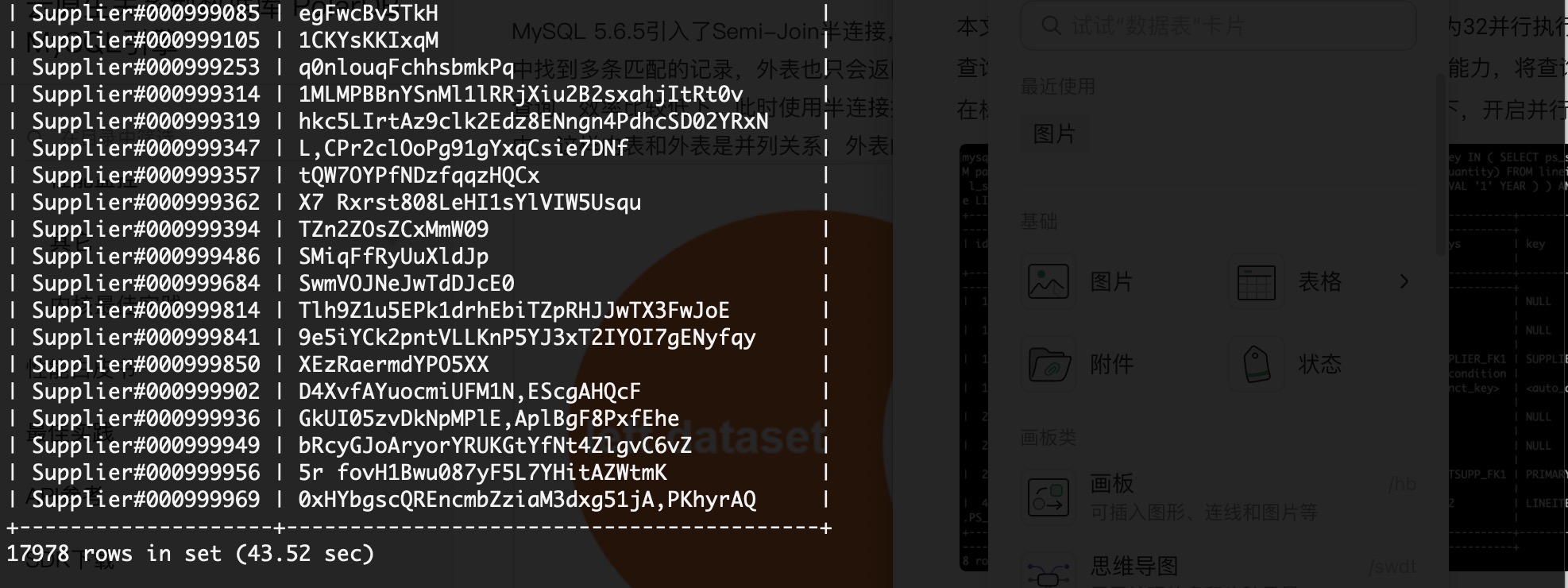
-> Index lookup on lineitem using LINEITEM_FK2 (L_PARTKEY=partsupp.PS_PARTKEY, L_SUPPKEY=partsupp.PS_SUPPKEY) (cost=4.05 rows=7)在標準TPC-H 100 GB的資料量,熱資料情境下,串列的執行時間:
多機並行開啟情況下的執行時間:
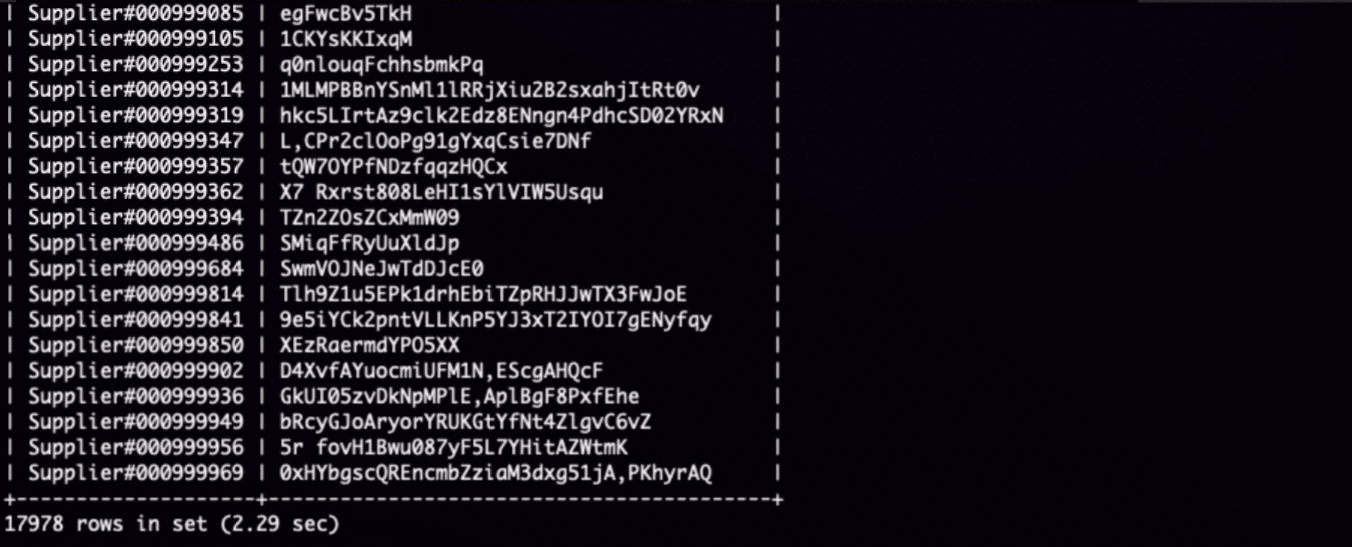
可以看到執行時間從43.52秒減少到了2.29秒,效能提升19倍。