您可以使用PolarDB for MySQL提供的Partial Result Cache(簡稱PTRC)功能來緩衝查詢語句中運算元的中間結果集,來減少這些複雜運算元的重複計算,以此來提升查詢效能。本文介紹了PTRC的概念、工作原理、如何基於代價選擇PTRC以及PTRC的動態反饋機制等內容。
PTRC概念
PTRC是針對一個查詢內部運算元層級粒度的結果集緩衝特性,比如緩衝Correlated subquery或NestLoopJoin等運算元執行的臨時結果,後續再次執行該運算元時,如果結果集緩衝中已存在運算元的計算結果,則無需再重複執行該運算元。
PTRC中的Partial有兩層含義:
PTRC緩衝的不是整個查詢的結果集,而是查詢內部某個或某幾個運算元執行的中間結果集。
並不一定緩衝運算元所有的中間結果集,而是根據記憶體限制可能只緩衝部分中間結果集。
相較於傳統的Query Cache,PTRC的緩衝粒度更小,是對查詢內部某些運算元進行加速,並且可以看出PTRC的生命週期也是跟隨查詢一起開始和結束。基於此,PTRC的適用範圍會更廣,因為只針對查詢內部運算元的最佳化,不存在跨節點查詢時的資料一致性問題,只要一個運算元符合要求(即運算元執行時依賴的參數不變,執行結果也不會變)就可以使用PTRC,在選擇PTRC時不僅需要遵循規則,還會基於代價來決策是否使用PTRC。
PTRC工作原理
PTRC的核心思想是緩衝查詢語句中運算元的中間結果集來避免某些運算元的重複執行,可以被PTRC加速的運算元需要滿足如下條件:
運算元執行時依賴相關性參數(Correlated Parameters),並且會被反覆執行多次。如NestLoopJoin和相互關聯的子查詢;
運算元的相關性參數保持不變,無論執行多少次,運算元執行的結果是固定的。比如運算元中不能有影響運算元重複執行結果的函數Random、NOW和UDF等,否則緩衝中的資料會影響最終結果的正確性。
運算元執行時依賴的相關性參數(Correlated Parameters),即運算元執行時所依賴的外部參數。例如t1 join t2 on t1.a = t2.a,t1表作為驅動表,t1表的每一行都要和t2表完成一次join操作,而 t1.a 則被認為是該NestLoopJoin運算元執行時依賴的相關性參數。如果t1.a在t1表中存在較多的重複值,那PTRC將會減少這部分的重複計算。再比如Correlated subquery運算元,每執行一次子查詢,都依賴於父查詢的一次掃描結果作為驅動參數。
此處以TPCH-Q17為例來說明PTRC的基本工作原理。查詢語句樣本如下:
select
sum(l_extendedprice) / 7.0 as avg_yearly
from
lineitem,
part
where
p_partkey = l_partkey
and p_brand = 'Brand#34'
and p_container = 'MED BOX'
and l_quantity < (
select
0.2 * avg(l_quantity)
from
lineitem
where
l_partkey = p_partkey
);PTRC以運算元的相關性參數作為key,運算元的執行結果作為value儲存在緩衝中。故TPCH-Q17中PTRC的緩衝儲存格式為:key= p_partkey, value = [true/false] 。
TPCH-Q17中相互關聯的子查詢的PTRC的主要執行流程如下圖所示: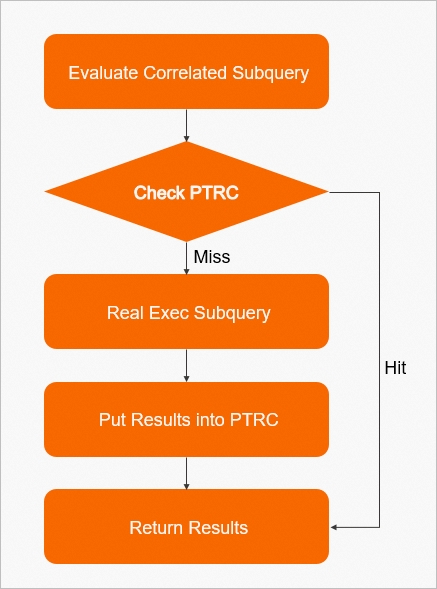
每次對相互關聯的子查詢求值時,根據p_partkey的值在PTRC的緩衝中尋找結果:
如果未命中,則需要執行子查詢進行求值,並將求值結果記錄到PTRC的緩衝中;
如果命中緩衝中的結果,則直接將結果返回,從而避免重複執行一次子查詢。
因為TPCH-Q17是part表join lineitem表後再執行子查詢,join之後的結果中p_partkey重複項非常多,而p_partkey又是子查詢的相關性參數,所以TPCH-Q17的PTRC命中率會很高,效能提升會非常顯著。
使用EXPLAIN命令可以查看執行計畫,在子查詢執行前添加了一個Partial Result Cache運算元,則說明該子查詢中引入了PTRC,如下圖所示:
前提條件
PolarDB for MySQL叢集需為8.0版本且Revision version為8.0.2.2.9或以上,您可以通過查詢版本號碼來確認叢集版本。
參數說明
參數 | 層級 | 說明 |
partial_result_cache_enabled | Global/Session | Partial Result Cache功能開關。取值範圍如下:
|
partial_result_cache_cost_threshold | Global/Session | PTRC的代價閾值。當單個查詢的整體cost超過該閾值時,才使用PTRC。 取值範圍:0~ 18446744073709551615。預設值:10000。 |
partial_result_cache_check_frequency | Global/Session | 觸發PTRC動態反饋檢測的頻率,當累計cache miss的次數達到該值時觸發一次檢測。 取值範圍:0~18446744073709551615。預設值:200。 |
partial_result_cache_low_hit_rate | Global/Session | PTRC命中率的低水位閾值。當最佳化器估算的命中率高於此值時才考慮使用PTRC,如果已使用PTRC,動態反饋機制中發現真實命中率低於該值時,將直接放棄繼續使用PTRC。 取值範圍:0~100。預設值:20。 |
partial_result_cache_high_hit_rate | Global/Session | PTRC命中率的高水位閾值。當記憶體使用量達到上限並且命中率高於此值時,記憶體緩衝變更為檔案儲存體緩衝,已緩衝的資料也會轉存至檔案中。 取值範圍:0~100。預設值:70。 |
partial_result_cache_max_mem_size | Global/Session | 單個查詢中PTRC累積記憶體使用量量。一個查詢內部可能有多個PTRC,多個PTRC累計使用的記憶體不能超過該值。 取值範圍:0~18446744073709551615。單位:Byte。預設值:67108864。 |
如何基於代價選擇PTRC
根據PTRC執行流程可以看出,引入PTRC並不是越多越好,還取決於PTRC的命中率,如果命中率不高,引入PTRC會帶來額外的效能開銷,比如每一次查詢都需要Check Cache,以及佔用額外的記憶體等。
為了減少不必要的開銷,最佳化器會基於代價來選擇是否使用PTRC,主要從以下兩個維度來進行判斷:
當查詢的整體cost高於
partial_result_cache_cost_threshold參數值時,才考慮引入PTRC;評估運算元使用PTRC的命中率,當命中率高於
partial_result_cache_low_hit_rate參數值時,才考慮引入PTRC。
基於代價選擇PTRC時,最佳化器會優先檢查partial_result_cache_cost_threshold參數值。
當查詢的整體cost小於該閾值時,該查詢的執行代價比較低,本身應該就是一個短查詢,即便引入了PTRC,效能提升也比較有限,且額外的Check Cache等操作可能還會對高並發下的短事務類查詢的latency造成負面影響,所以提供了一個總的代價閾值來控制是否完全忽略PTRC。且該閾值不滿足使用PTRC的條件時,減少了最佳化器階段枚舉所有運算式來判斷是否使用PTRC的開銷。
當查詢的整體cost大於或等於
partial_result_cache_cost_threshold參數值時,最佳化器會遍曆檢查所有可能滿足PTRC規則的運算元,並估算滿足規則的運算元的PTRC命中率,計算公式為:hit_rate = (fanout - ndv)/ fanout其中,
fanout表示一個運算元需要被重複執行的總次數。ndv表示PTRC的key的唯一值的個數,即所有相關性參數組合值的唯一值個數。
當估算的hit_rate小於partial_result_cache_low_hit_rate參數值時,該運算元就不會考慮使用PTRC。但在MySQL已有的代價模型中,它的統計資訊依賴於表的索引或長條圖,如果相關性參數所在的列沒有索引或長條圖,則很難評估出非常準確的ndv值,這種情況下查詢時會盡量引入PTRC,然後交給PTRC執行階段的動態反饋機制來動態檢查是否有必要繼續使用PTRC。
PTRC的動態反饋機制
在PTRC執行階段,每次Cache是否命中都會記錄到統計資訊中,動態反饋機制負責對PTRC的真實命中率進行計算,如果發現實際命中率低於partial_result_cache_low_hit_rate參數值時,則會直接在執行階段禁掉PTRC,恢複到沒有引入PTRC前的執行狀態,以減少低效的PTRC帶來的額外開銷。
參數partial_result_cache_check_frequency用於控制PTRC動態檢測命中率的頻率,即累計出現cache miss的次數,比如預設值為200,則當cache miss的次數累計達到200次後,就會觸發一次動態反饋機制。
由於結果集緩衝在記憶體中,當PTRC的記憶體使用量量達到上限時,同樣也會觸發動態反饋機制,但此時的動態反饋不僅要檢查命中率是否過低,還會決策是否進行資料淘汰或者是否需要將結果集轉儲到Disk。
當PTRC的記憶體使用量量達到上限時,動態反饋策略如下:
當
hit_rate低於partial_result_cache_low_hit_rate參數值時,認為命中率過低,直接禁用PTRC;當
hit_rate高於partial_result_cache_high_hit_rate參數值時,命中率大於高水位,會將記憶體中的快取資料轉存至Disk儲存,即便轉儲至Disk,依然會有可預期的效能提升;當
hit_rate位於低水位和高水位之間時,則會觸發LRU資料淘汰,將命中率不符合預期的資料清理掉,後續重新緩衝新的資料,若新快取資料後再次觸發記憶體不足,則重複執行上述步驟1~步驟3。
參數partial_result_cache_max_mem_size限制單個查詢中PTRC累積記憶體使用量量,當查詢中PTRC累積記憶體超過該限制,則所有的PTRC都將會觸發動態反饋機制。
PTRC效能測試
通過基於代價選擇PTRC的內容可以看出,影響PTRC加速效果的主要因素如下:
使用PTRC加速的運算元的執行代價要足夠大。如果運算元本身執行代價不高,則緩衝加速的提升空間有限;
快取命中率。PTRC的快取命中率越高,加速效果越明顯。
以TPCH-Q17測試為例: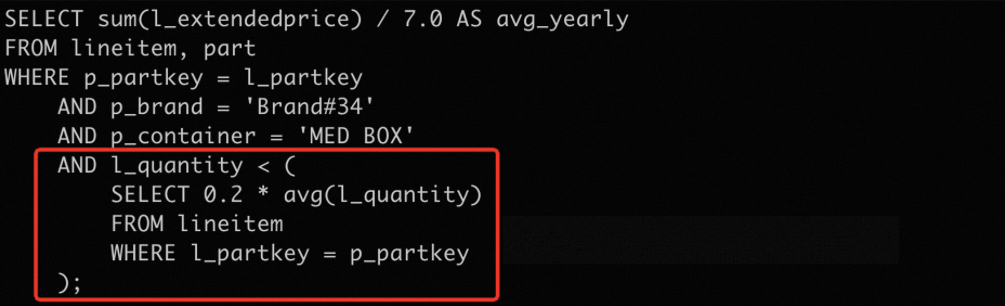
上圖中的子查詢會重複執行很多次,在子查詢中引入PTRC後的查詢計劃如下:
經過測試統計資訊計算,在TPCH-Q17子查詢中引入PTRC後的快取命中率高達96%,緩衝加速效果非常明顯。測試資料如下圖: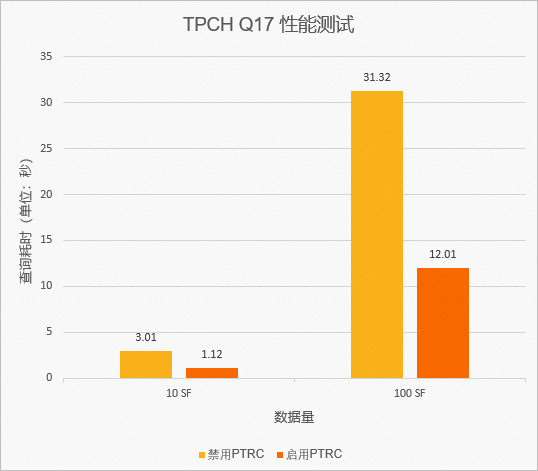
總結
PTRC是針對單個查詢內部具有相關性參數依賴的複雜運算元,通過緩衝運算元執行的中間結果集來減少這些複雜運算元的重複計算,只要命中率足夠高,就可以獲得非常可觀的加速效果。目前查詢中Correlated Subquery、Nested Loop Join(包含Inner join、Outer join、Semi join以及Anti join)等多種運算元均可以使用PTRC進行加速。