Hash Join是社區版MySQL 8.0版本中引入的新Join方式,可以大幅提升分析型查詢的執行效能。PolarDB MySQL版8.0版本提供了對Hash Join的並存執行支援,並不斷豐富其並存執行策略。本文介紹如何在PolarDB的並行查詢中使用Hash Join功能。
簡單並行Hash Join
前提條件
叢集版本需為PolarDB MySQL版8.0叢集版,且Revision version為8.0.2.1.0或以上,您可以參見查詢版本號碼確認叢集版本。
並行策略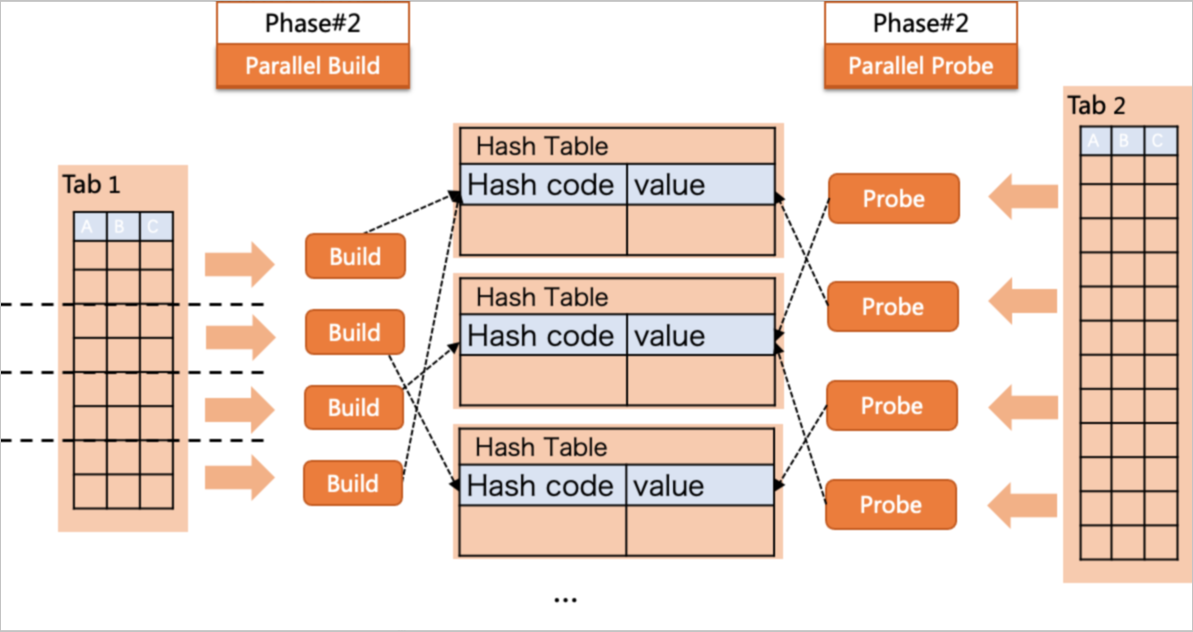
上圖中是並行度為4的並行查詢計劃(即PolarDB會啟用4個Worker來執行查詢)。其中t1表會執行Parallel Scan,即由4個Worker分別掃描這個表。每個Worker使用t1的一部分資料建立各自的Hash表,再和整個t2表執行JOIN操作,最後收集(Gather)在Leader中,得到整個查詢的結果。
使用方法
文法:
目前在PolarDB中Hash Join只能通過
EXPLAIN FORMAT=TREE語句來顯示。樣本:
如下樣本中建立了2個表,且在表裡插入了一些資料:
CREATE TABLE t1 (c1 INT, c2 INT); CREATE TABLE t2 (c1 INT, c2 INT); INSERT t1(c1, c2) WITH RECURSIVE seq AS ( SELECT 1 AS a, 1 AS b UNION ALL SELECT a + 1, b + 1 FROM seq WHERE a < 1000 ) SELECT a,b FROM seq; INSERT INTO t2 SELECT * FROM t1;查看SQL語句的查詢計劃:
EXPLAIN FORMAT=TREE SELECT /*+ PQ_DISTRIBUTE(t1 PQ_NONE) PQ_DISTRIBUTE(t2 PQ_NONE) */ * FROM t1 JOIN t2 ON t1.c1 = t2.c2;如下是上述2個表的JOIN查詢計劃:
EXPLAIN FORMAT=TREE EXPLAIN -> Gather (slice: 1; workers: 4) (cost=10.82 rows=4) -> Parallel inner hash join (t2.c2 = t1.c1) (cost=0.57 rows=1) -> Parallel table scan on t2, with parallel partitions: 1 (cost=0.03 rows=1) -> Parallel hash -> Parallel table scan on t1, with parallel partitions: 1 (cost=0.16 rows=1)上述是並行度為4的並行查詢計劃(即PolarDB會啟用4個Worker來執行查詢)。其中
t1表會執行Parallel Scan,即由4個Worker分掃這個表,每個Worker使用t1的一部分資料建立各自的Hash表,再和整個t2表執行JOIN操作,最後收集(Gather)在Leader,得到整個查詢的結果。
Shuffle Hash Join
前提條件
叢集版本需為PolarDB MySQL版8.0叢集版,且Revision version為8.0.2.2.0或以上,您可以參見查詢版本號碼確認叢集版本。
並行策略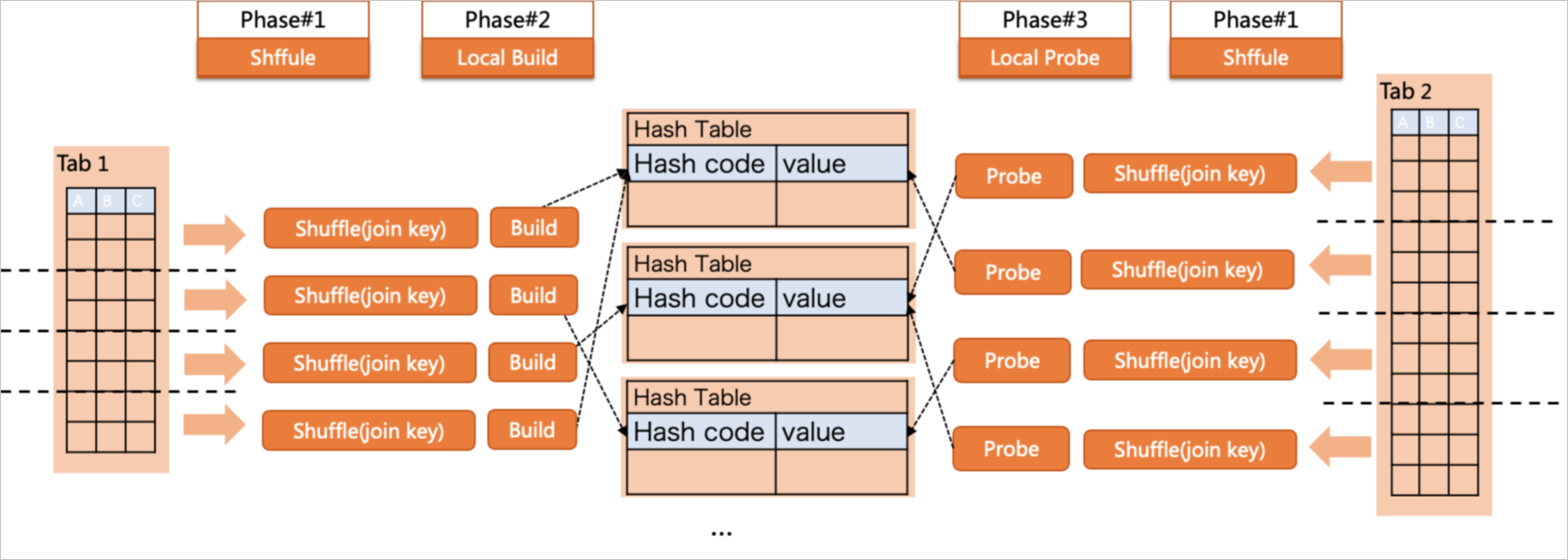
Parallel hash join實現了build+probe全階段的並存執行,但如果共用的hash table較大,會導致轉儲到磁碟的IO操作,影響查詢執行效率。因此引入了partition hash join來解決此問題。如上圖所示,其中t1表會執行Parallel Scan,即由4個Worker分別掃描這個表,每個Worker使用t1的一部分資料,然後將資料按照join key做repartition的分發到下一個階段的Worker中,在各個Worker內構建本地容量更小的hash table。完成構建後,會開始對t2表執行Parallel Scan,分別掃描這張表,同樣按照join key做repartition的分發到已經完成hash table構建的Worker中。在Worker線程內完成分區資料的probe操作,最後收集(Gather)在Leader中,得到整個查詢的結果。
使用方法
文法:
目前在PolarDB中Hash Join只能通過
EXPLAIN FORMAT=TREE語句來顯示。樣本:
如下樣本中建立了2個表,且在表裡插入了一些資料:
CREATE TABLE t1 (c1 INT, c2 INT); CREATE TABLE t2 (c1 INT, c2 INT); INSERT t1(c1, c2) WITH RECURSIVE seq AS ( SELECT 1 AS a, 1 AS b UNION ALL SELECT a + 1, b + 1 FROM seq WHERE a < 1000 ) SELECT a,b FROM seq; INSERT INTO t2 SELECT * FROM t1;查看SQL語句的查詢計劃:
EXPLAIN FORMAT=TREE SELECT * FROM t1 JOIN t2 ON t1.c1 = t2.c2;如下是上述2個表的JOIN查詢計劃:
EXPLAIN FORMAT=TREE EXPLAIN | -> Gather (slice: 1; workers: 2) (cost=33.38 rows=4) -> Inner hash join (t2.c1 = t1.c1) (cost=23.08 rows=2) -> Repartition (hash keys: t2.c1; slice: 2; workers: 1) (cost=11.35 rows=2) -> Parallel table scan on t2, with parallel partitions: 1 (cost=0.65 rows=4) -> Hash -> Repartition (hash keys: t1.c1; slice: 3; workers: 1) (cost=11.35 rows=2) -> Parallel table scan on t1, with parallel partitions: 1 (cost=0.65 rows=4)