PolarDB MySQL版叢集的一鍵診斷功能融合了資料庫自治服務DAS的部分功能,您可以通過其中的自治中心開啟自動擴縮容服務。本文檔介紹了開啟自動擴縮容服務的操作步驟。
前提條件
PolarDB MySQL版叢集要求:
產品版本:企業版
系列:叢集版
叢集無進行中的配置變更。
需建立DAS服務關聯角色。
費用說明
具體的費用說明,請參見變更配置費用說明。
注意事項
資料庫自治服務DAS自動變更配置功能在自動擴容時不支援對主節點和唯讀節點分別變更配置,自動回縮後所有隻讀節點會跟主節點變成同一規格,請謹慎使用。
說明當PolarDB叢集中節點數量大於2個且主節點與唯讀節點規格不一致,並開啟自動擴容時。在整個觀測視窗內,如果CPU平均使用率大於或等於設定值時,PolarDB會根據叢集的即時讀寫流量情況選擇以下幾種可能的擴容方式:
增加與主節點同一規格的唯讀節點。
增加與叢集中某個唯讀節點同一規格的唯讀節點。
說明該擴容方式適用於唯讀節點的CPU平均使用率大於或等於設定值時的情境。
與主節點升配到同一規格。
開啟自動回縮後,如果叢集不在靜默期,且縮容觀測視窗期間CPU使用率小於30%的時間佔比超過99%,則系統將自動逐級回縮叢集規格,直到回縮至原始規格,有以下幾種可能的回縮方式:
刪除增加的唯讀節點。
說明未被刪除的唯讀節點規格保持不變。
所有隻讀節點會跟主節點變成同一規格。
叢集規格的升降級不會對叢集中已有資料造成任何影響。
規格變更過程中,可能會出現一次約30秒的閃斷,建議您在業務低穀期執行變更,並確保應用具備自動重連機制。
PolarDB叢集變更配置期間,唯讀請求相比讀寫請求的延隔時間,可能比正常運行狀態的延隔時間更長。
操作步驟
登入PolarDB控制台,選擇叢集所在地區,在叢集列表中單擊目的地組群ID進入詳情頁。
在左側導覽列中,選擇。
單擊自治中心頁簽。在自治中心地區,單擊自治功能開關。
在自治功能管理對話方塊中的自治功能設定頁簽下,開啟自治功能開關。
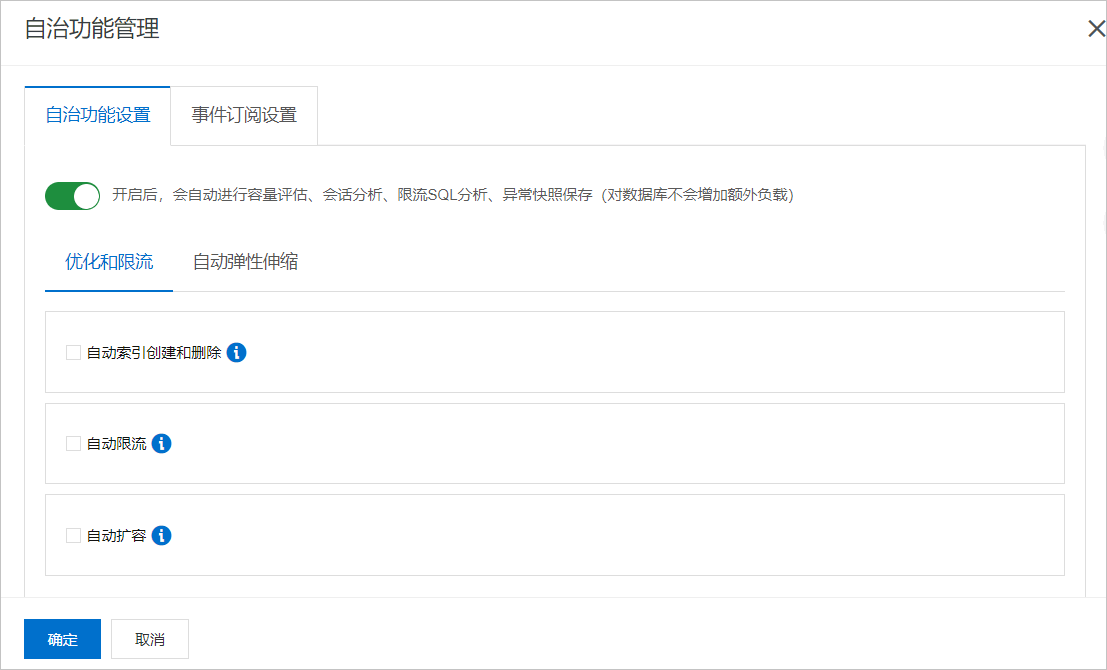
在最佳化和限流頁簽下,勾選自動擴容和自動回縮。
勾選自動擴容後,在整個觀測視窗內如果CPU平均使用率大於或等於設定值,則在觀測視窗結束後,PolarDB將根據叢集負載進行擴容。例如,CPU平均使用率的閾值為70%,觀測視窗期是5分鐘,自動擴容的時間是10分鐘,所以當叢集某個節點在觀測視窗內的平均CPU使用率超過70%時,將對叢集進行擴容。對叢集進行擴容時,將根據叢集的即時讀寫流量情況選擇增加節點或升配的擴容方式。讀流量主導時預設增加唯讀節點,寫流量主導時預設提升叢集規格。而在主節點負載過高等特殊情境下,系統將選擇提升叢集規格。
勾選自動回縮後,如果叢集不在靜默期,且縮容觀測視窗(觀測視窗+10分鐘)期間觸發自動擴容節點的CPU平均利用率小於30%的時間佔比超過99%,則系統將自動逐級回縮叢集規格,直到回縮至原始規格。若自動擴容時增加了唯讀節點,則縮容時逐個減少唯讀節點。若自動擴容時提升了叢集規格,則縮容時進行規格降級。對於PolarDB MySQL版叢集,只能對整個叢集進行規格升降級,無法對叢集中的單個節點進行規格升降級。
設定自動擴容和自動回縮參數,單擊確定。
參數名稱
參數說明
CPU平均利用率不小於
自動擴容的觸發閾值。當CPU平均使用率大於或等於設定的值時,就會觸發自動擴容。
規格上限
自動擴容的規格上限。觸發自動擴容後,會逐級擴容PolarDB的叢集規格,例如從4核到8核再到16核,直到升級至擴容規格的上限。
唯讀節點數量上限
自動擴容唯讀節點的數量上限。觸發自動擴容後,系統會根據實際情況增加1~2個唯讀節點,直到增加至上限。
說明自動擴容的節點會加入叢集預設地址,自訂地址需要配置新节点自动加入。關於如何配置新节点自动加入,詳情請參見設定資料庫代理。
觀測視窗
在整個觀察視窗期內,若CPU平均使用率大於等於設定值,則在觀測視窗結束後,PolarDB將根據叢集的即時讀寫流量情況選擇增加節點或升配的擴容方式。例如觀測視窗期是5分鐘,自動擴容的時間是10分鐘,所以您需要等待15分鐘左右才能看到自動擴容的效果。
說明縮容觀測視窗時間長度為觀測視窗+10分鐘。例如,觀測視窗設定為30分鐘時,縮容觀測視窗為40分鐘。
靜默期
兩次自動擴容或自動回縮的最小間隔時間。在靜默期內,PolarDB會持續進行觀測,但不會觸發自動擴容或縮容。若在靜默期與觀測視窗同時結束,且該觀測視窗內CPU使用率達到調整閾值,PolarDB會在靜默期和觀測視窗同時結束時觸發自動規格調整。